
Self Attention by Hand ✍️

Self-attention is what enables LLMs to understand context.
How does it work?
This exercise demonstrates how to calculate a 6-3 attention head by hand. Note that if we have two instances of this, we get 6-6 attention (i.e., multi-head attention, n=2).
Goal:
Transform [6D Features 🟧] to [3D Attention Weighted Features 🟦]
[1] Given
↳ A set of 4 feature vectors (6-D)
[2] Query, Key, Value
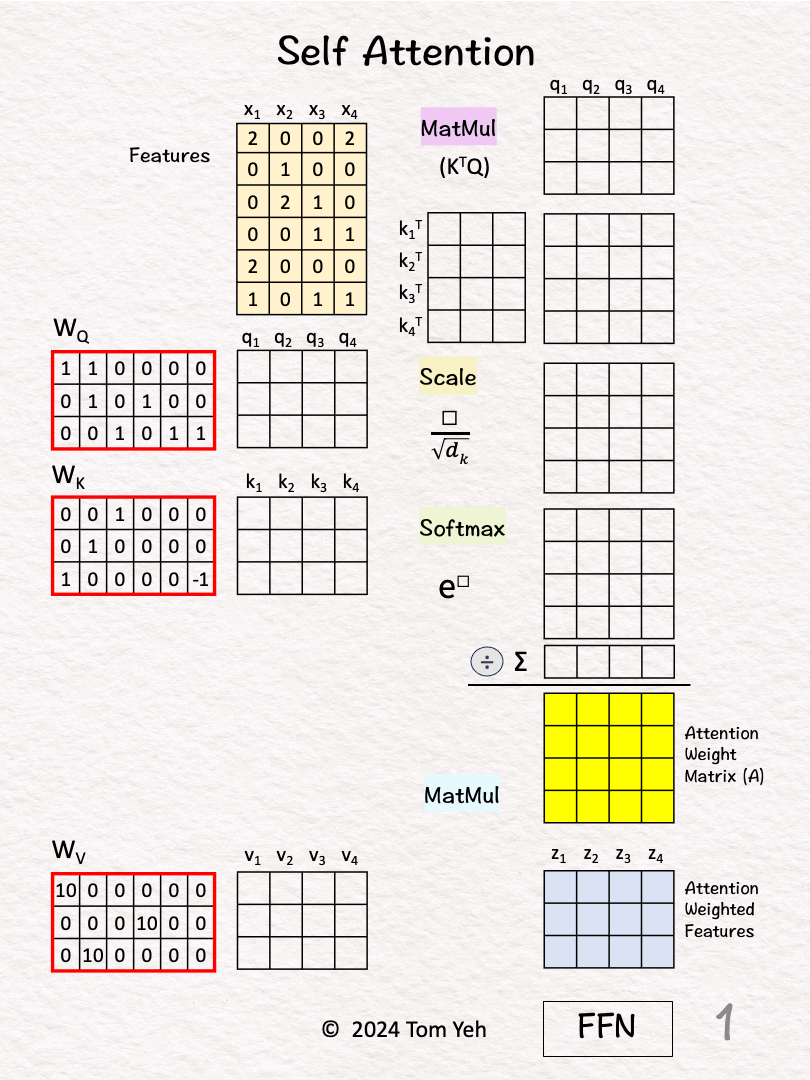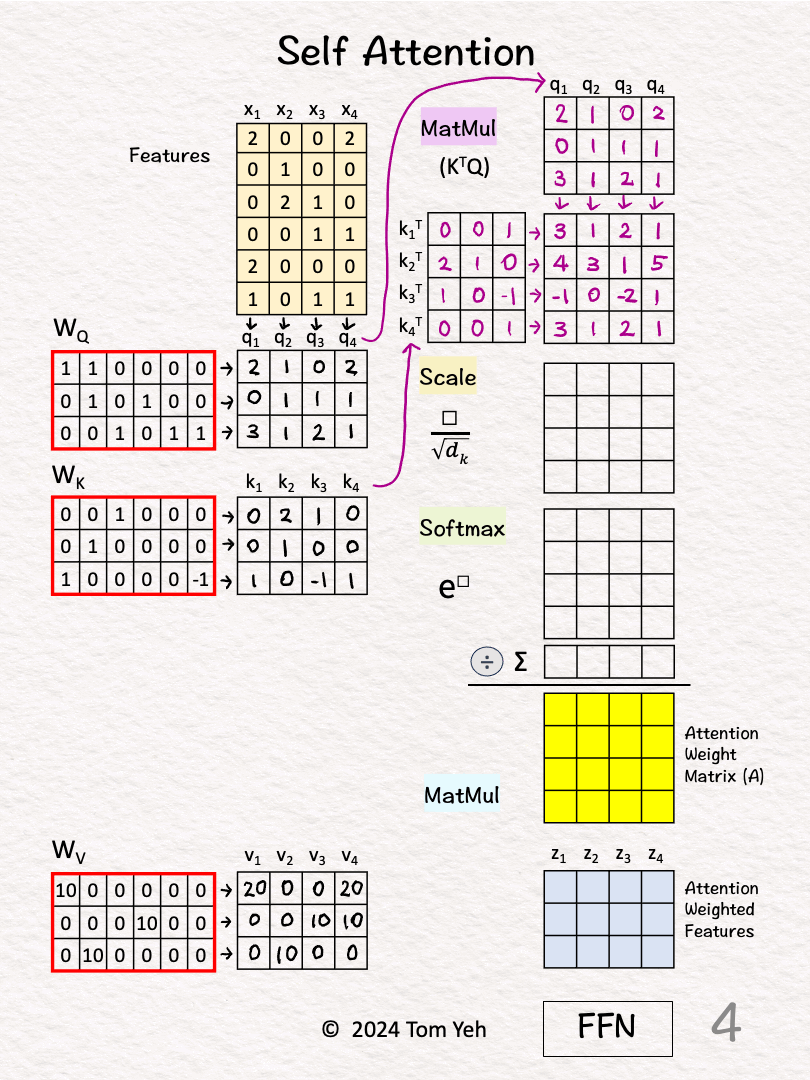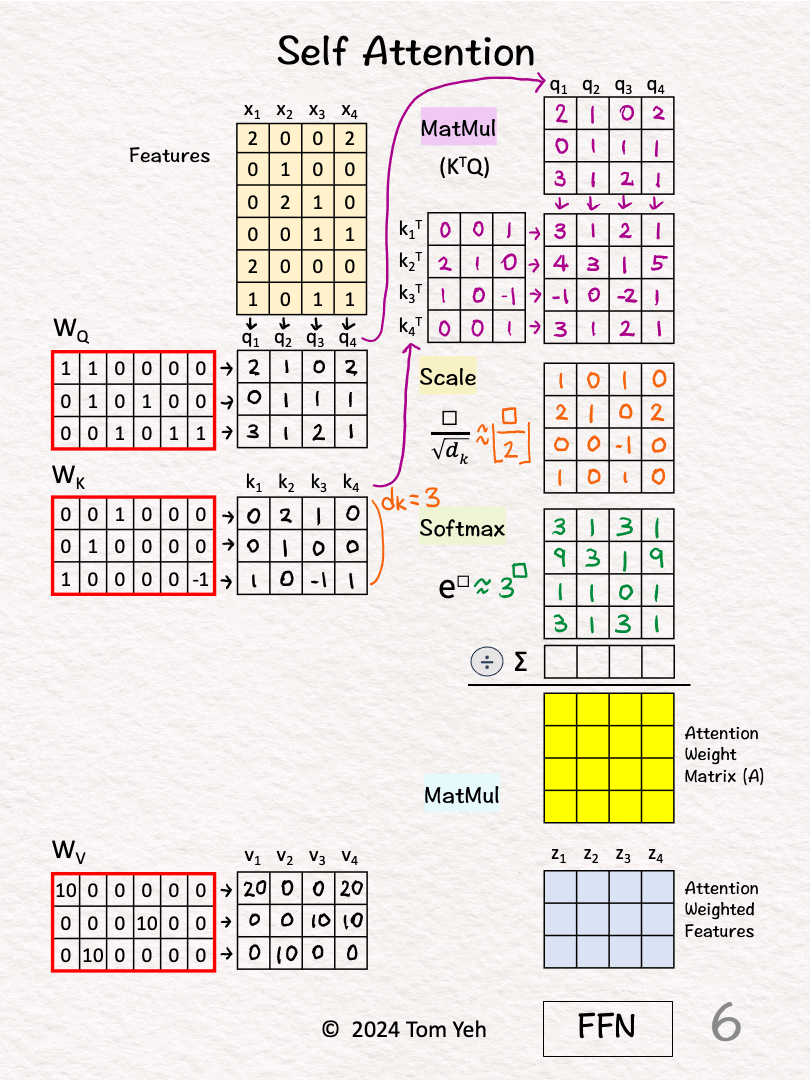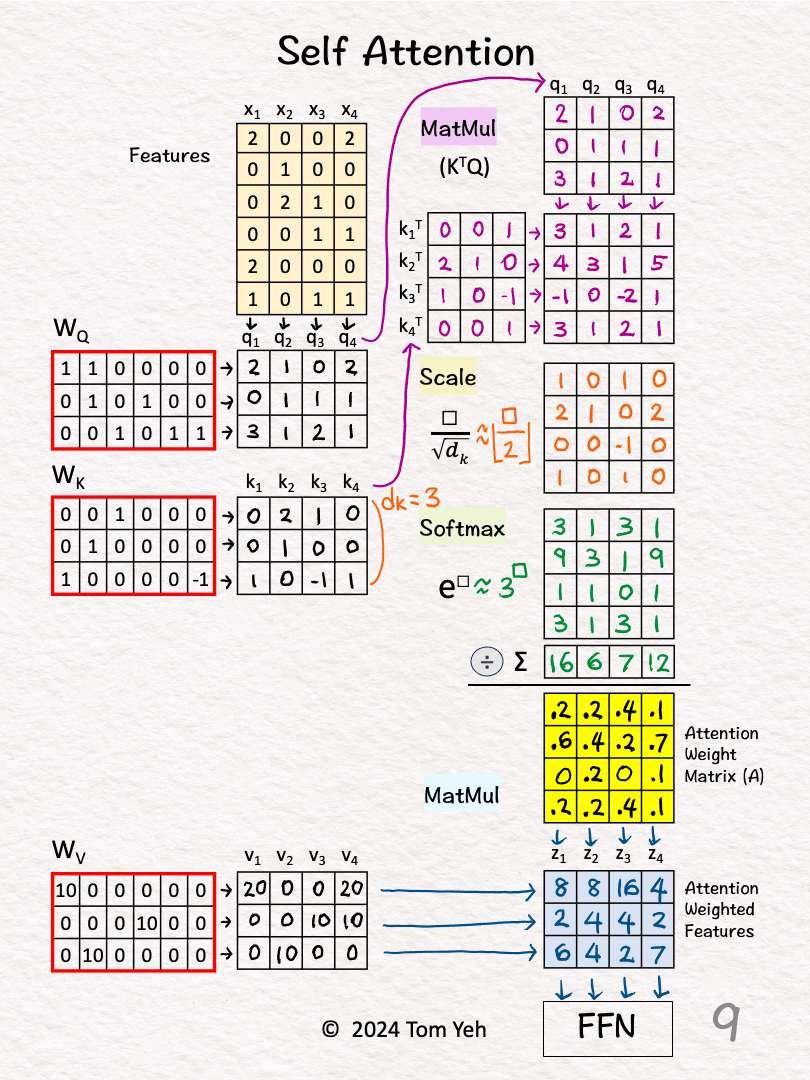
↳ Multiply features x's with linear transformation matrices WQ, WK, and WV, to obtain query vectors (q1,q2,q3,q4), key vectors (k1,k2,k3,k4), and value vectors (v1,v2,v3,v4).
↳ "Self" refers to the fact that both queries and keys are derived from the same set of features.
[3] 🟪 Prepare for MatMul
↳ Copy query vectors
↳ Copy the transpose of key vectors
[4] 🟪 MatMul
↳ Multiply K^T and Q
↳ This is equivalent to taking dot product between every pair of query and key vectors.
↳ The purpose is to use dot product as an estimate of the "matching score" between every key-value pair.
↳ This estimate makes sense because dot product is the numerator of Cosine Similarity between two vectors.
[5] 🟨 Scale
↳ Scale each element by the square root of dk, which is the dimension of key vectors (dk=3).
↳ The purpose is to normalize the impact of the dk on matching scores, even if we scale dk to 32, 64, or 128.
↳ To simplify hand calculation, we approximate [ □/sqrt(3) ] with [ floor(□/2) ].
[6] 🟩 Softmax: e^x
↳ Raise e to the power of the number in each cell
↳ To simplify hand calculation, we approximate e^□ with 3^□.
[7] 🟩 Softmax: ∑
↳ Sum across each column
[8] 🟩 Softmax: 1 / sum
↳ For each column, divide each element by the column sum
↳ The purpose is normalize each column so that the numbers sum to 1. In other words, each column is a probability distribution of attention, and we have four of them.
↳ The result is the Attention Weight Matrix (A) (yellow)
[9] 🟦 MatMul
↳ Multiply the value vectors (Vs) with the Attention Weight Matrix (A)
↳ The results are the attention weighted features Zs.
↳ They are fed to the position-wise feed forward network in the next layer.
Hi professor,
I think there's a typo. q2 should be [1,1,2] instead of [1,1,1].
Thank you!
Carlos
It would be great if we can pose the video to think about what is going on, and if the explanation are next to the video not down . Thanks for your effort