
Dropout by Hand ✍️
Calculating AI by Hand: 6 of 28

Library › Calculating AI by Hand ✍️
Dropout by Hand ✍️
Reinforcement Learning with Human Feedback (RLHF) by Hand ✍️
Dropout is a simple yet effective way of reducing overfitting and improving generalization. This hands-on exercise lets students practice calculating dropout, thereby gaining insight into its inner workings.
As an additional bonus, students get to practice calculating the gradients of the Mean Square Error (MSE) loss. After the practice, students are often surprised by how simple it is.
Network Architecture
Linear(2,4)
ReLU
Dropout(0.5)
Linear(4,3)
ReLU
Dropout(0.33)
Linear(3,2)
Training
Step 1 of 10: Given
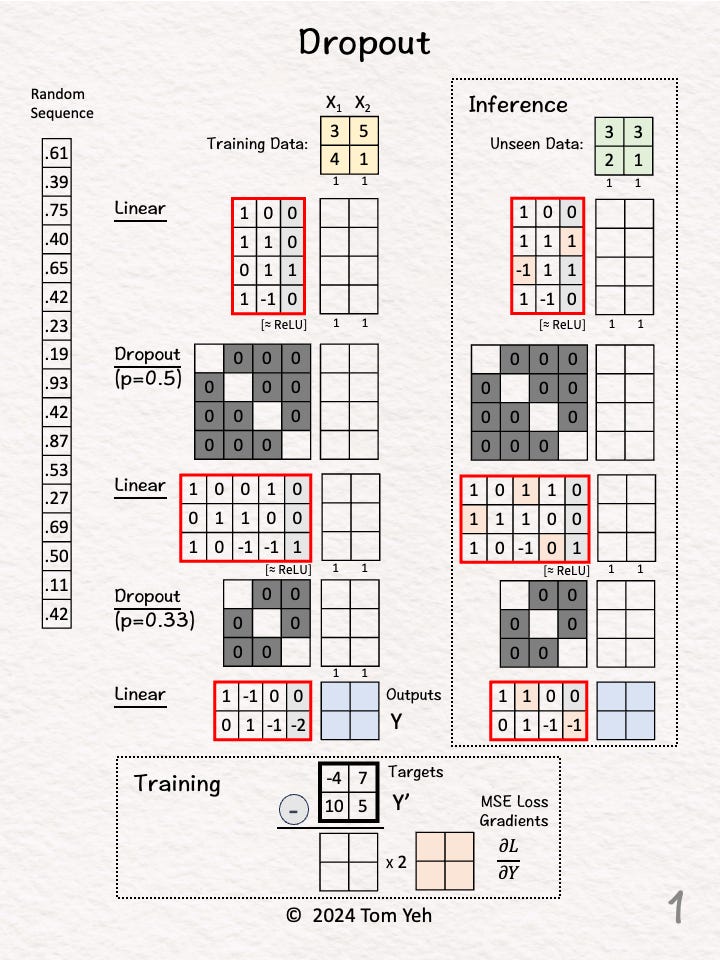
A training set of 2 examples X1, X2
Step 2 of 10: Random (p > 0.5)
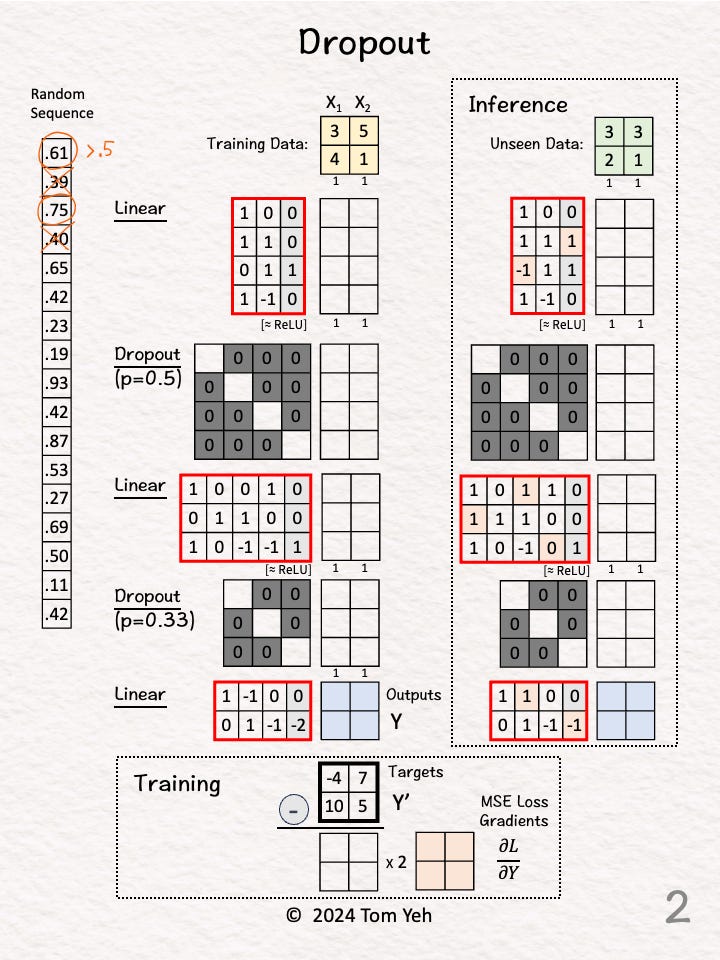
Draw 4 random numbers
For each random number, if it is above 0.5, we keep and denote it as ◯. Otherwise we drop and denote it as ╳.
The result is [◯, ╳, ◯, ╳]
Step 3 of 10: Dropout Matrix
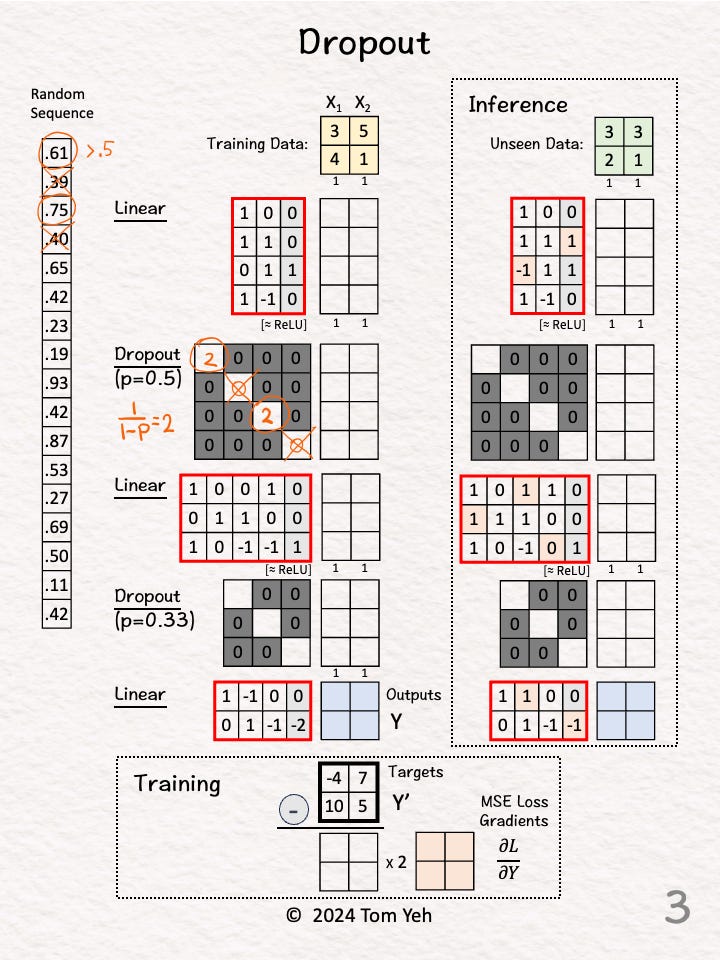
Calculate the scaling factor: 1 / (1-p) = 2
Set the diagonal based on [◯, ╳, ◯, ╳], where ◯ = 2 and ╳ = 0
The purpose is to drop the 2nd and the 4th nodes, and scale the remaining two nodes by 2.