
Autoencoder by Hand ✍️

The autoencoder model is the basis for training foundational models from a ton of data. We are talking about tens of billions of training examples, like a good portion of the Internet.
With that much data, it is not economically feasible to hire humans to label all of those data to tell a model what its targets are. Thus, people came up with many clever ideas to derive training targets from the training examples themselves [auto]matically.
The most straightforward idea is to just use the training data itself as the targets. This hands-on exercise demonstrates this idea.
Then, people tried hiding some parts of the training data and using those missing parts as the targets. This is called masking, which is how LLMs are trained these days.
Then, people tried pairing up text and images and using each other as targets. This is called "constrative" learning. This is the C in the famous CLIP model from OpenAI, which is the basis of all the multimodal foundational models.
Let's start with the basic---AutoEncoder.
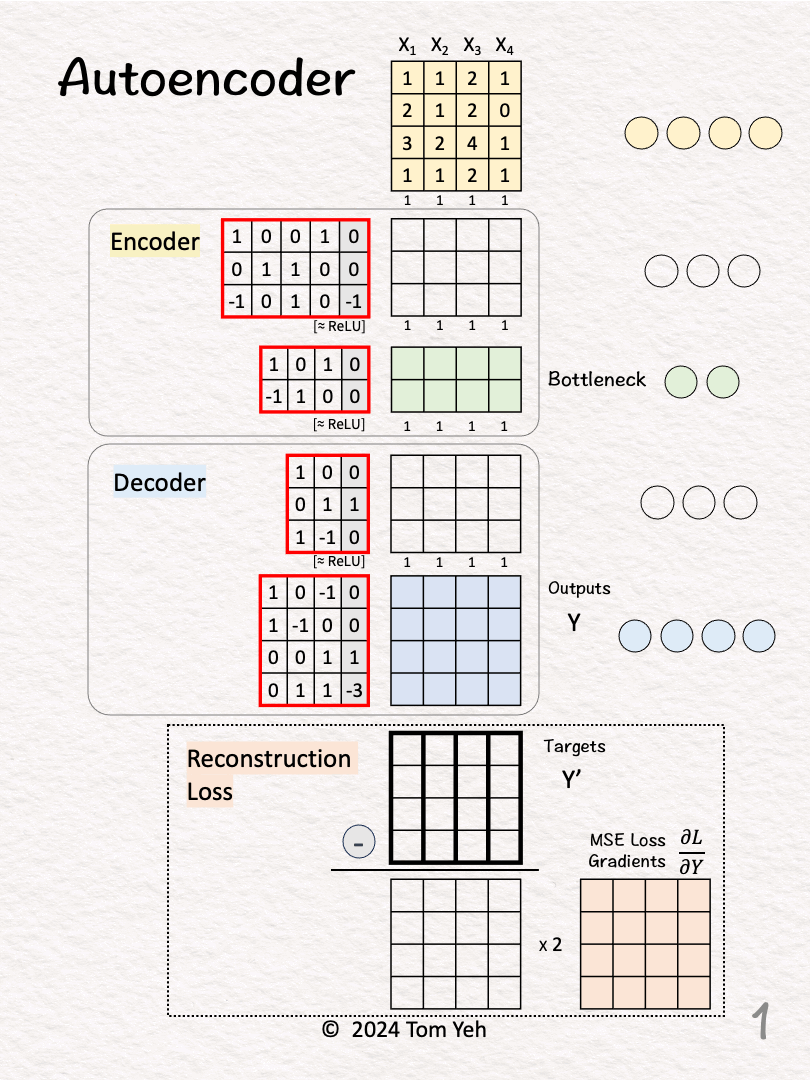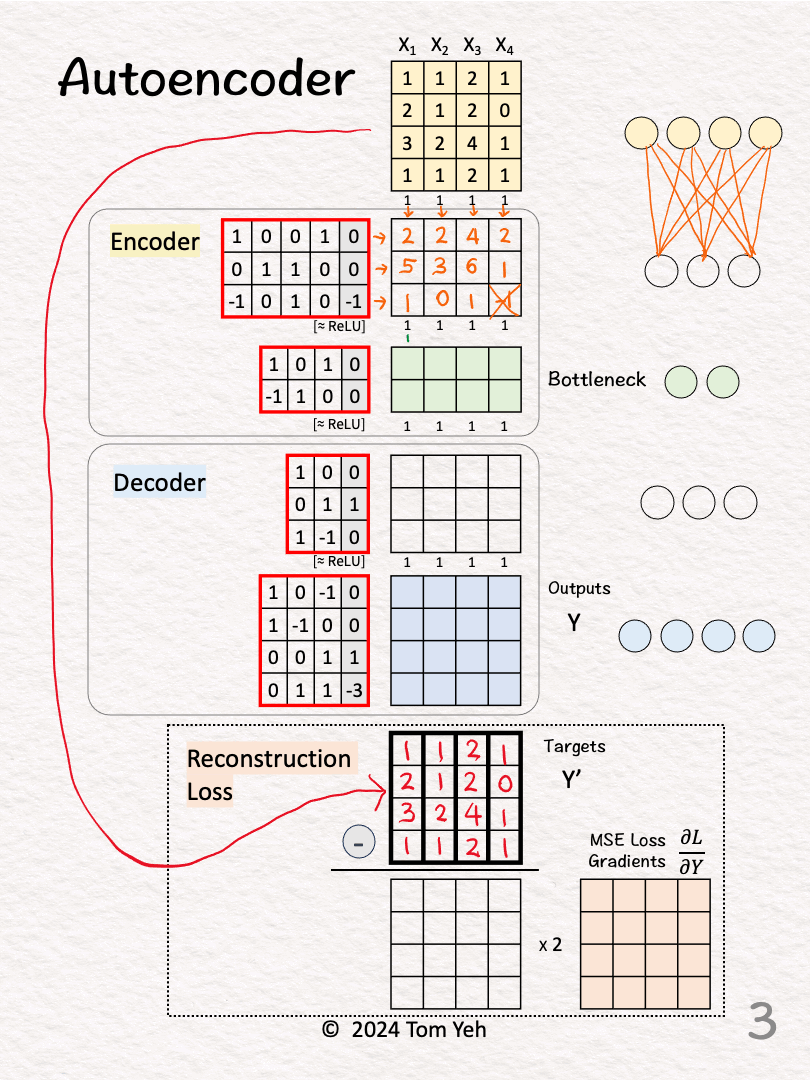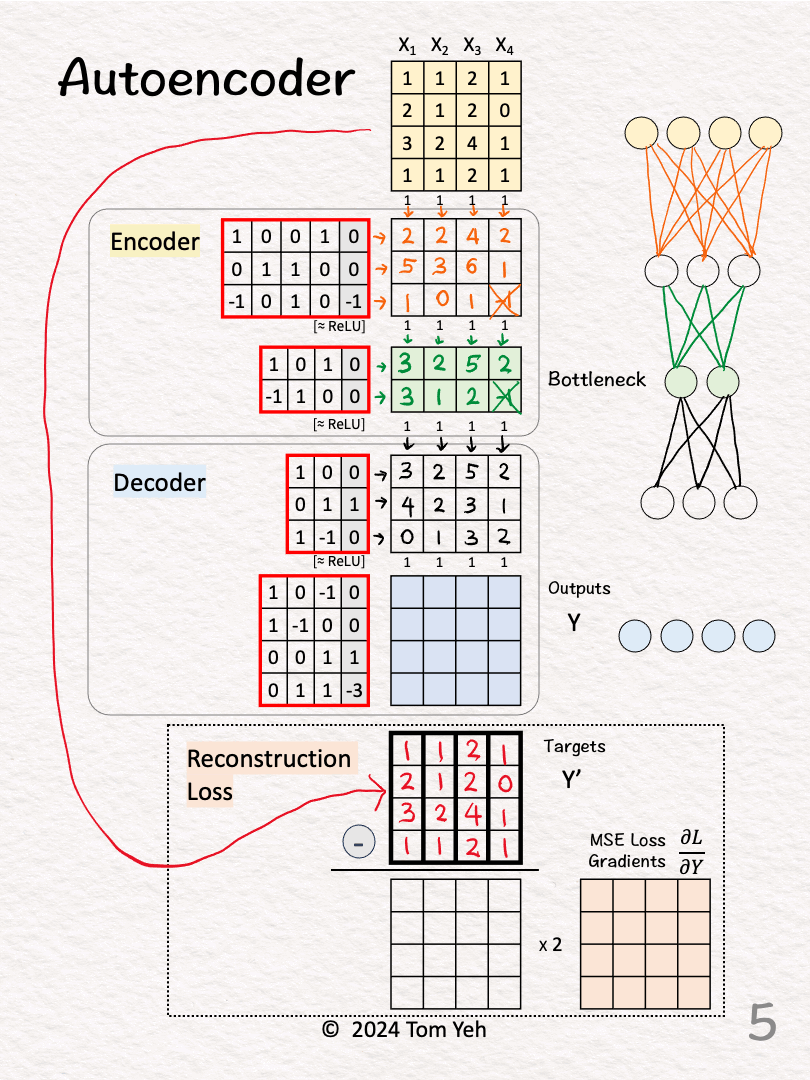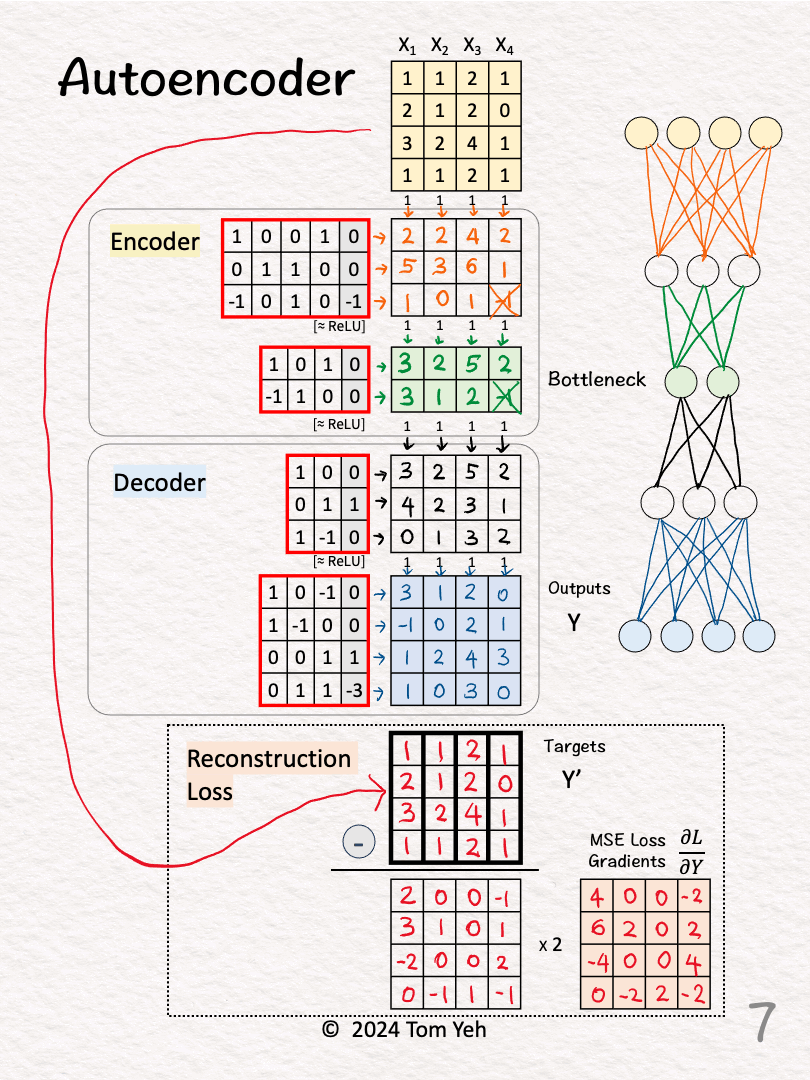
Network Architecture
🟨 Encoder
Linear(4,3)
ReLU
Linear(3,2)
ReLU
🟦 Decoder
Linear(2,3)
ReLU
Linear(3,4)
Walkthrough
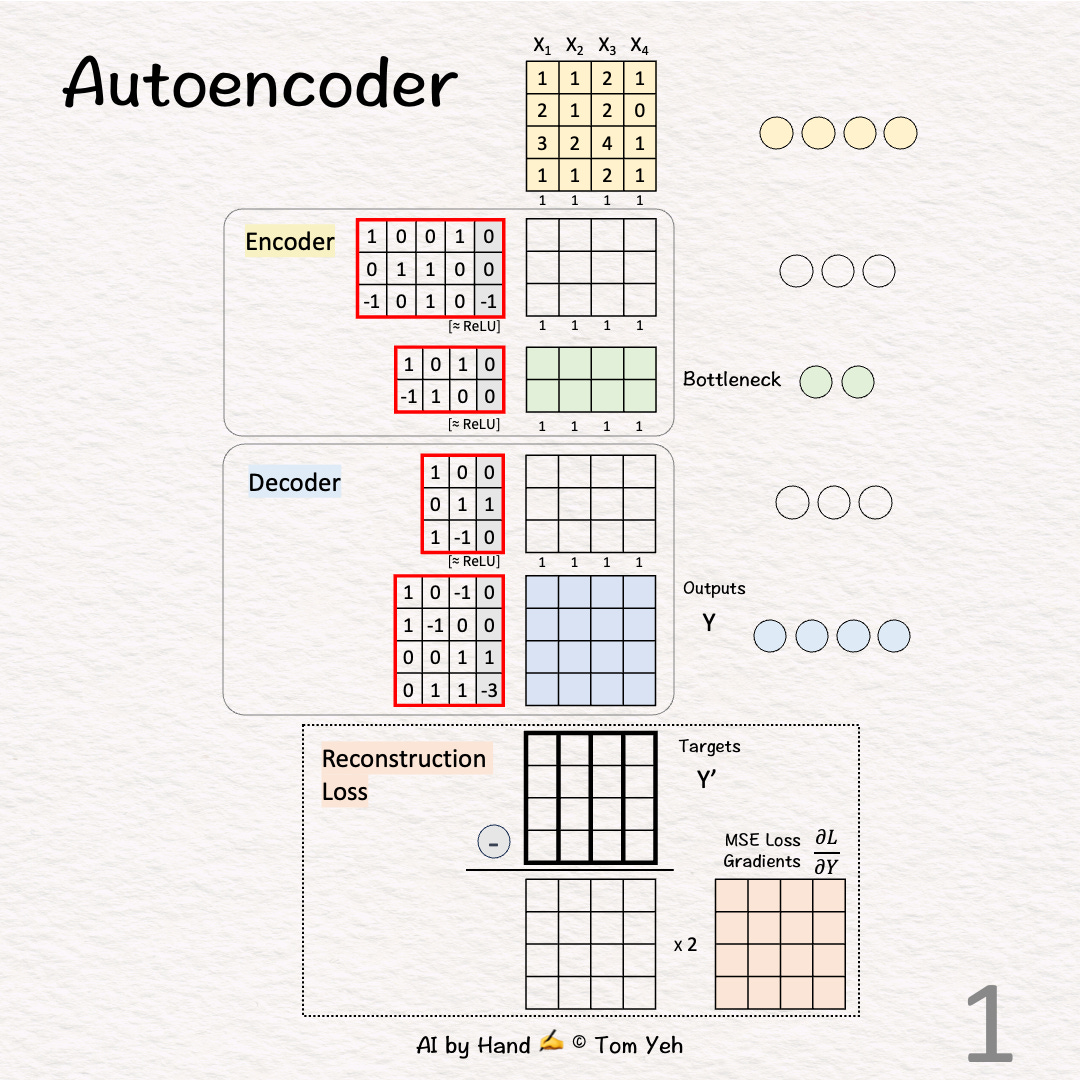
[1] Given
↳ Four training examples X1, X2, X3, X4
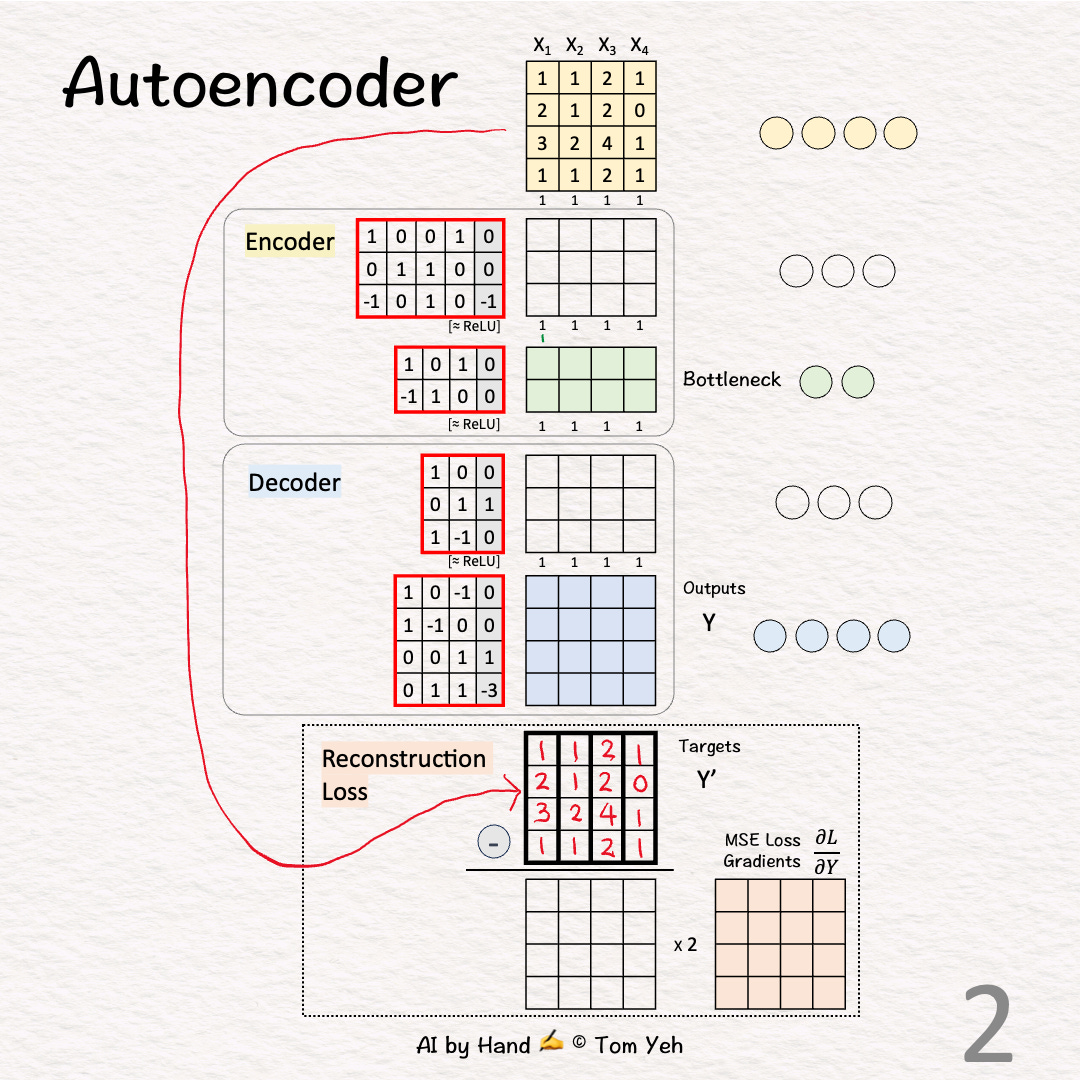
[2] Auto
↳ Copy training examples to Targets (Y')
↳ The purpose is to train the network to reconstruct the training examples.
↳ Since each target is a training example itself, we use the Greek word "auto" which means "self." This crucial step is what makes an autoencoder "auto."
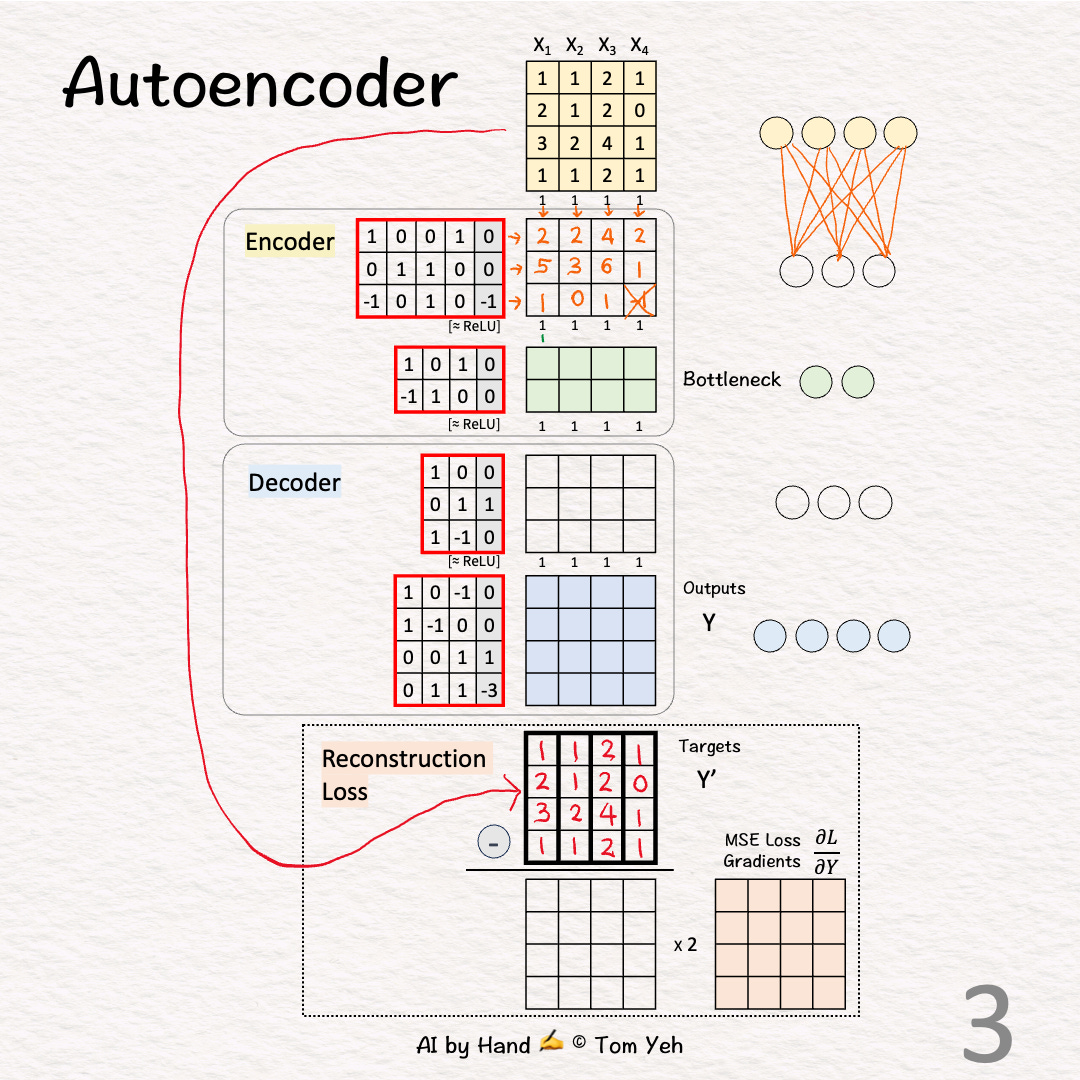
[3] 🟨 Encoder: Layer 1 + ReLU
↳ Multiply inputs with weights and biases
↳Apply ReLU, crossing out negative values (-1 -> 0)
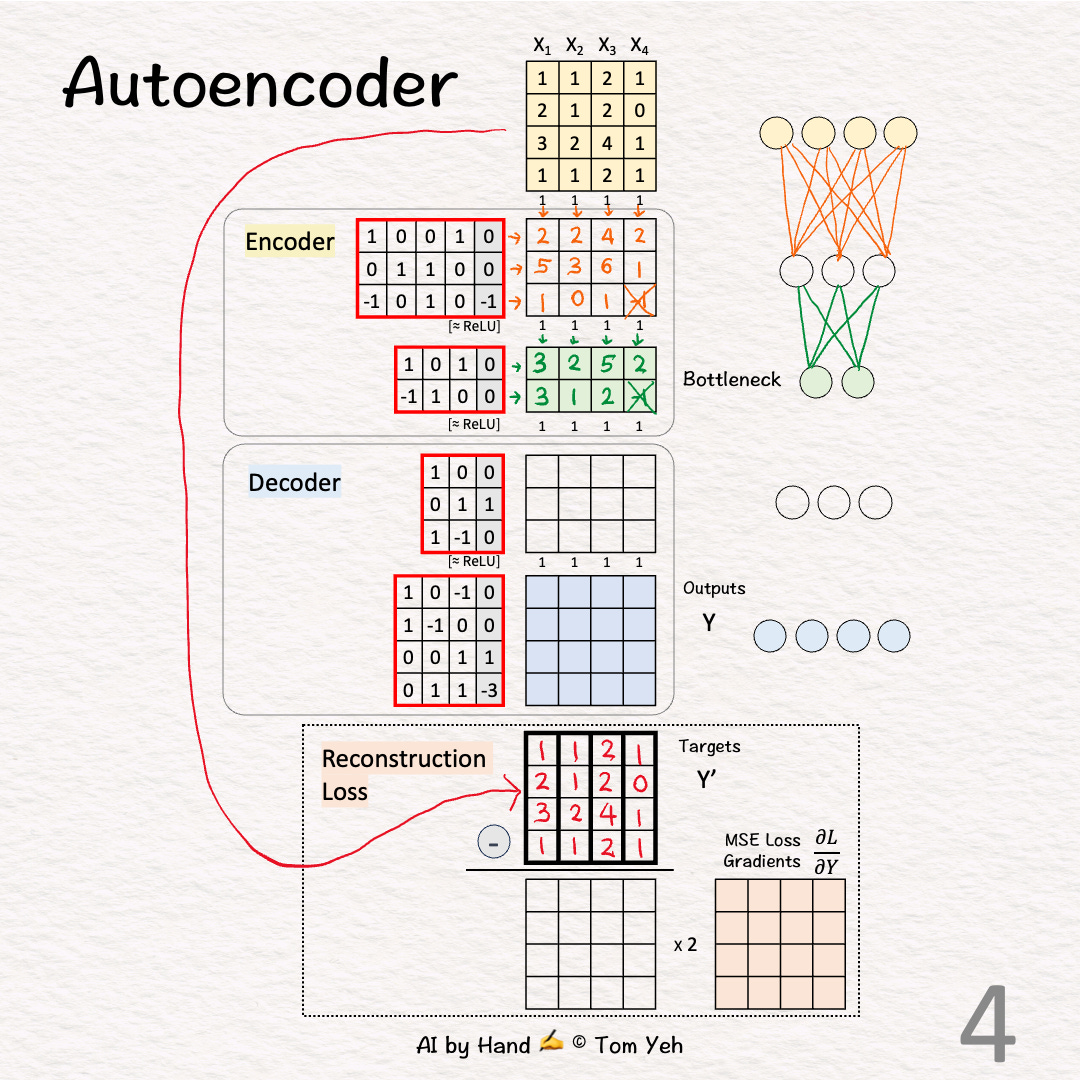
[4] 🟨 Encoder: Layer 2 + ReLU
↳ Multiply features with weights and biases
↳Apply ReLU, crossing out negative values (-1 -> 0)
↳ This layer is often called the "bottleneck" because its outputs (green 🟩) have a lot fewer feature dimensions (2) than the input features (4).
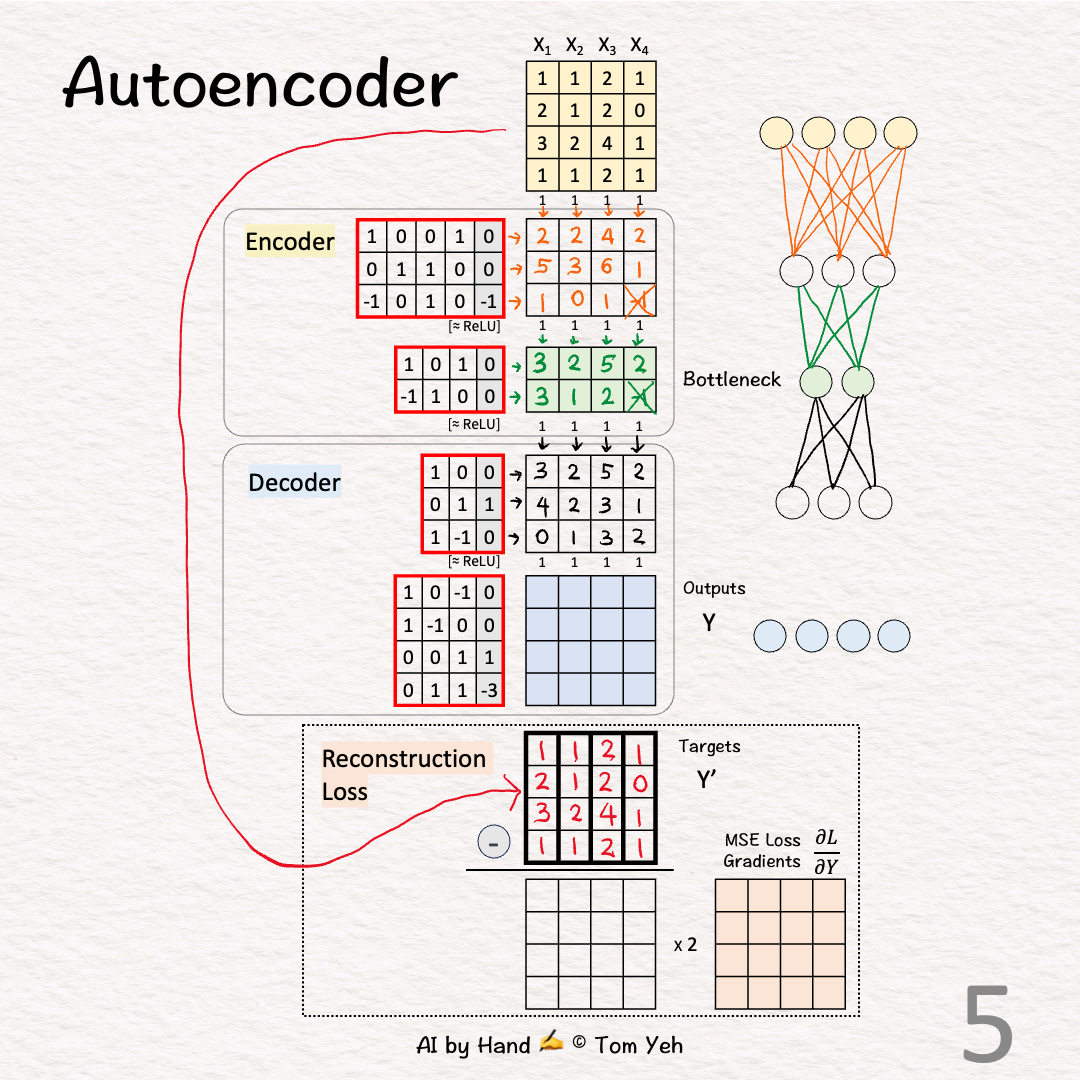
[5] 🟦 Decoder: Layer 1 + ReLU
↳ Multiply features with weights and biases
↳ Apply ReLU, crossing out negative values. Here, no negative values to cross out.
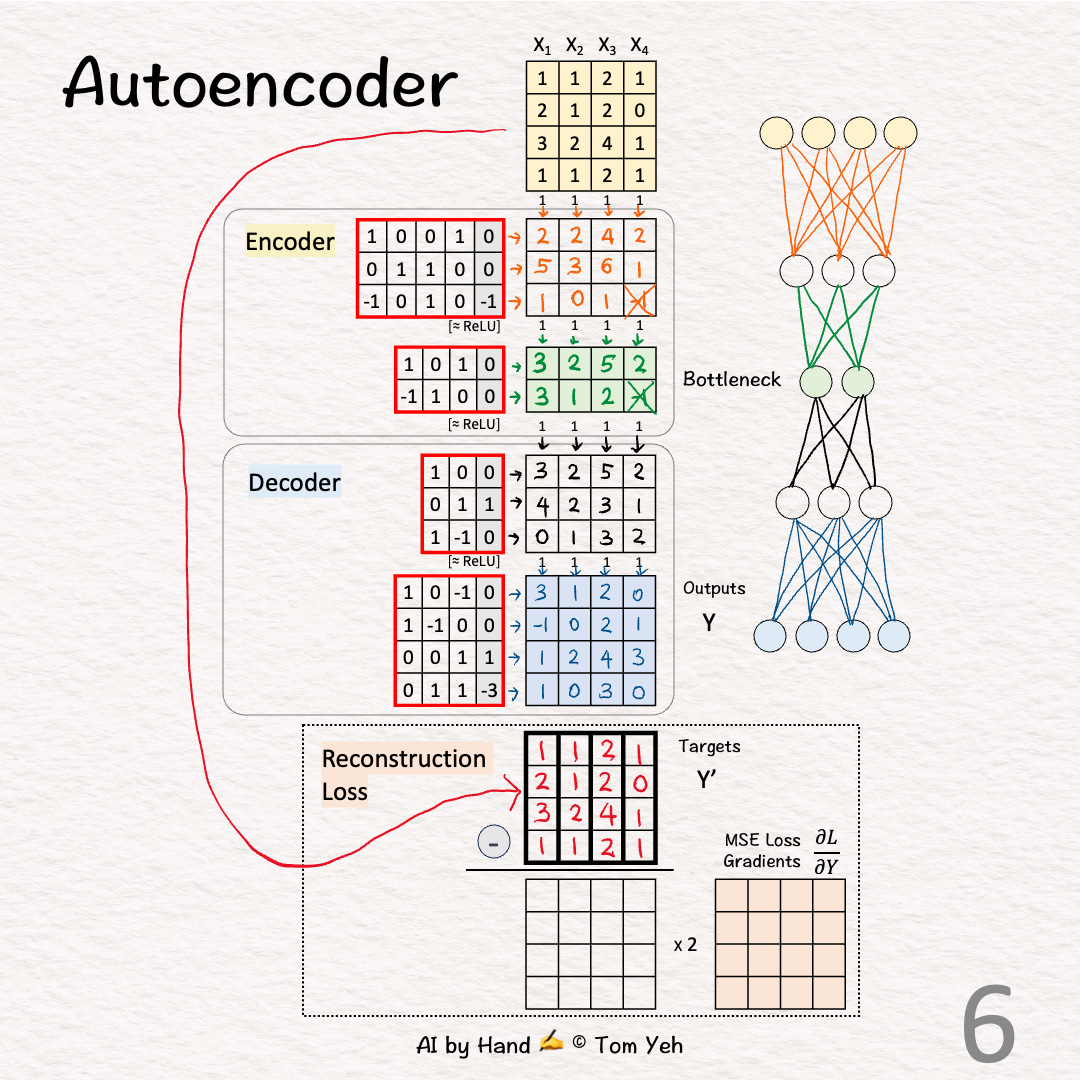
[6] 🟦 Decoder: Layer 2
↳ Multiply features with weights and biases
↳ The Outputs (Y) are the Decoder's attempt to reconstruct the training examples from their reduced 2-D representation (green 🟩).
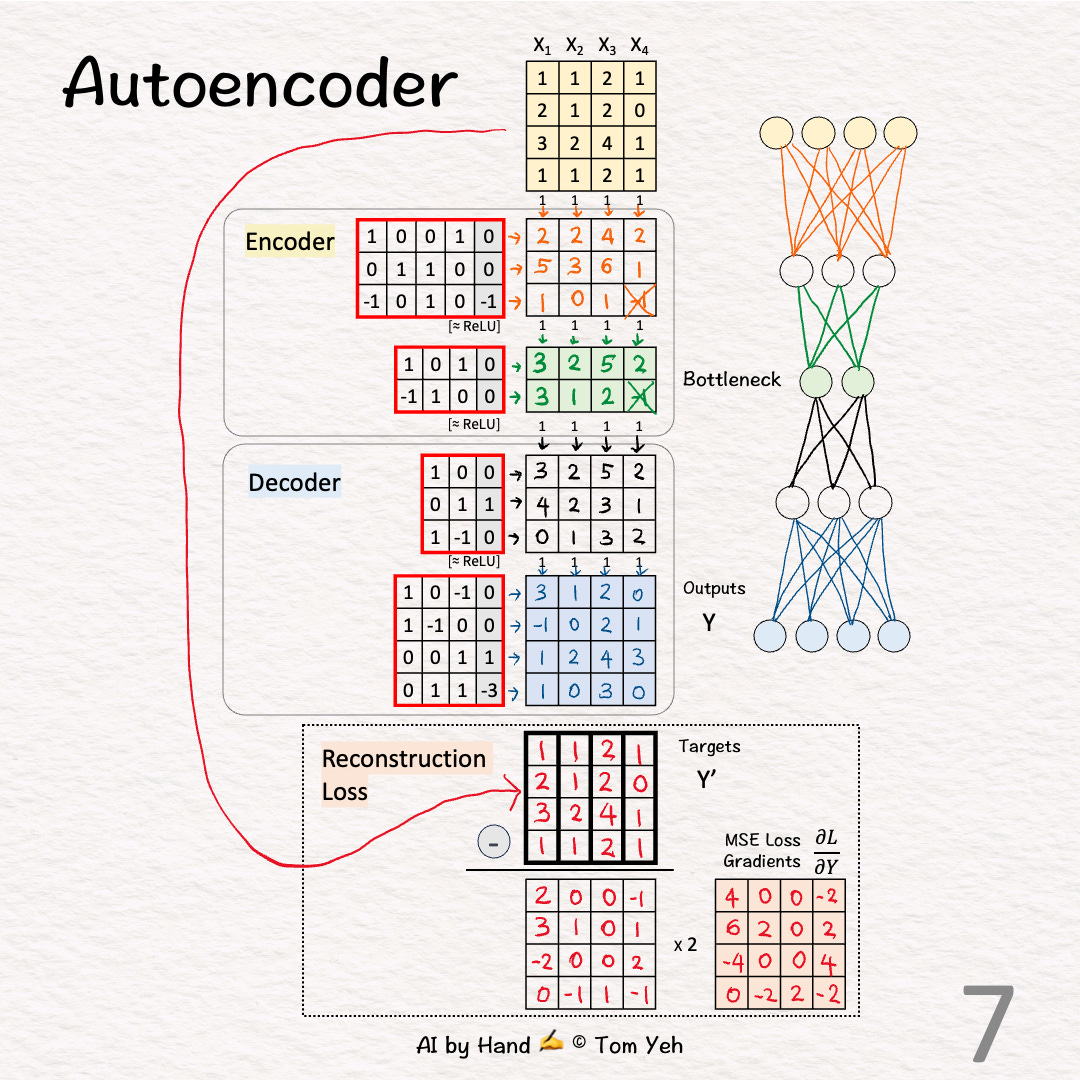
[7] 🟥 Loss Gradients & Backpropagation
↳ Calculate the gradients of the Mean Square Error (MSE) loss between the outputs (Y) and targets (Y').
↳ The formula is 2 * (Y - Y')
↳ First we calculate Outputs (Y) - Targets (Y')
↳ Second we multiply each element by 2
↳ These gradients kick off the backpropagation process to update weights and biases.
Superb sir. Could you please send me your email ID for my doubts in sequence of numbers generated algorithm. Thanks sir.
Can you please provide the file of that Exercise?