
Vector Database by Hand ✍️
Calculating AI by Hand: 22 of 28

Library › Calculating AI by Hand ✍️
Vector Database by Hand ✍️
Reinforcement Learning with Human Feedback (RLHF) by Hand ✍️
Vector databases are revolutionizing how we search and analyze complex data. They have become the backbone of Retrieval Augmented Generation (RAG).
How do vector databases work?
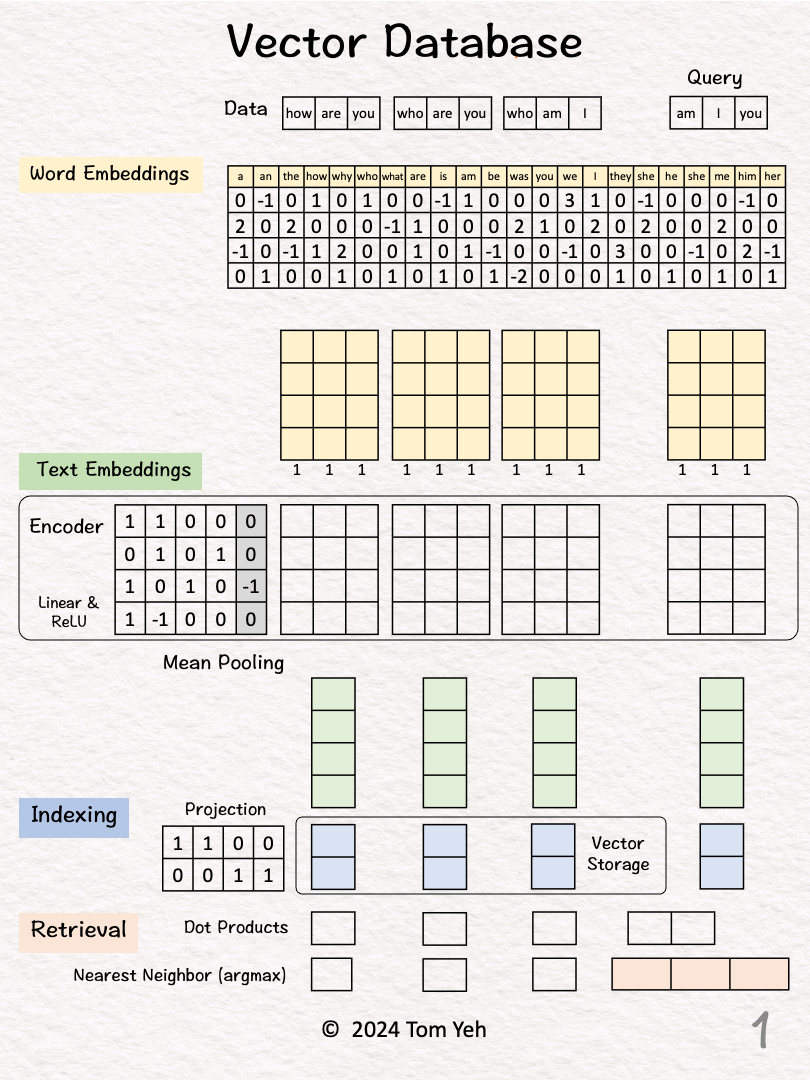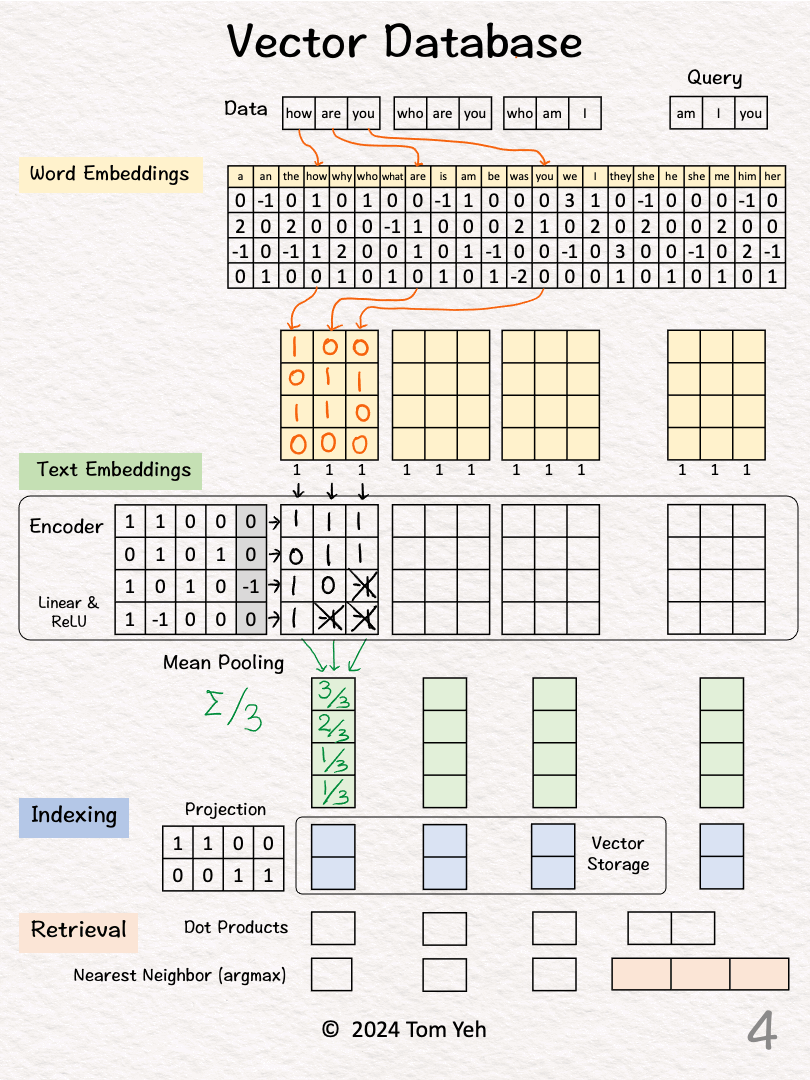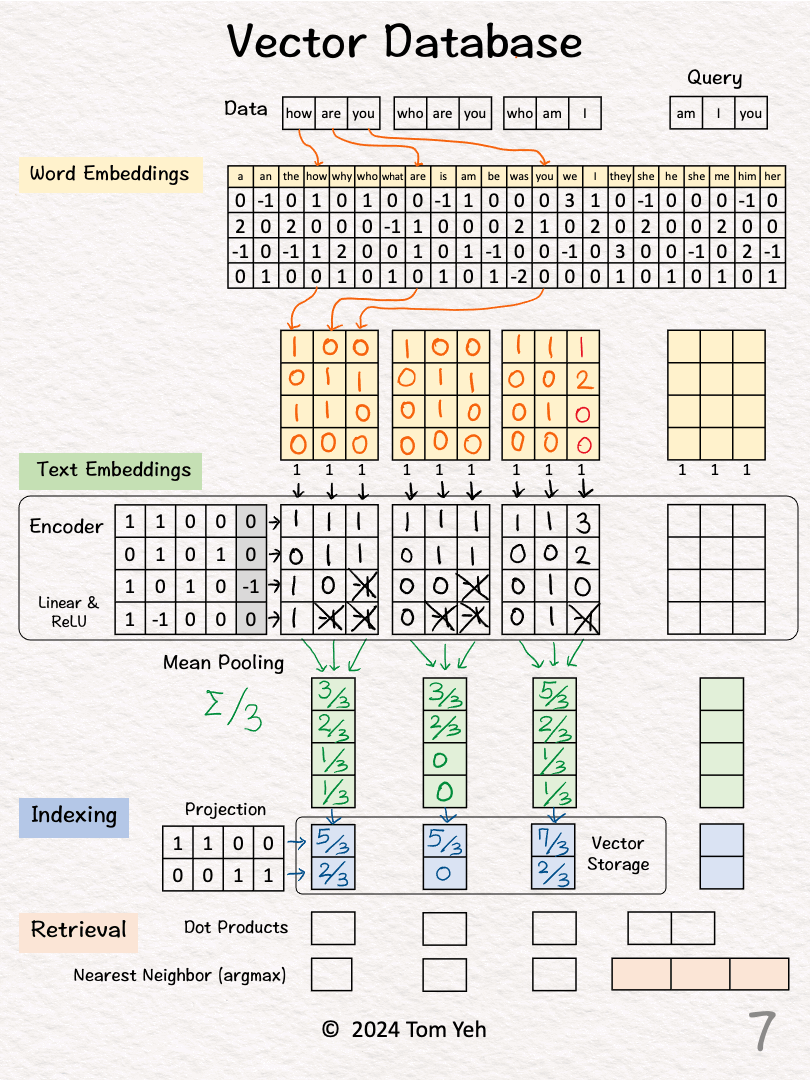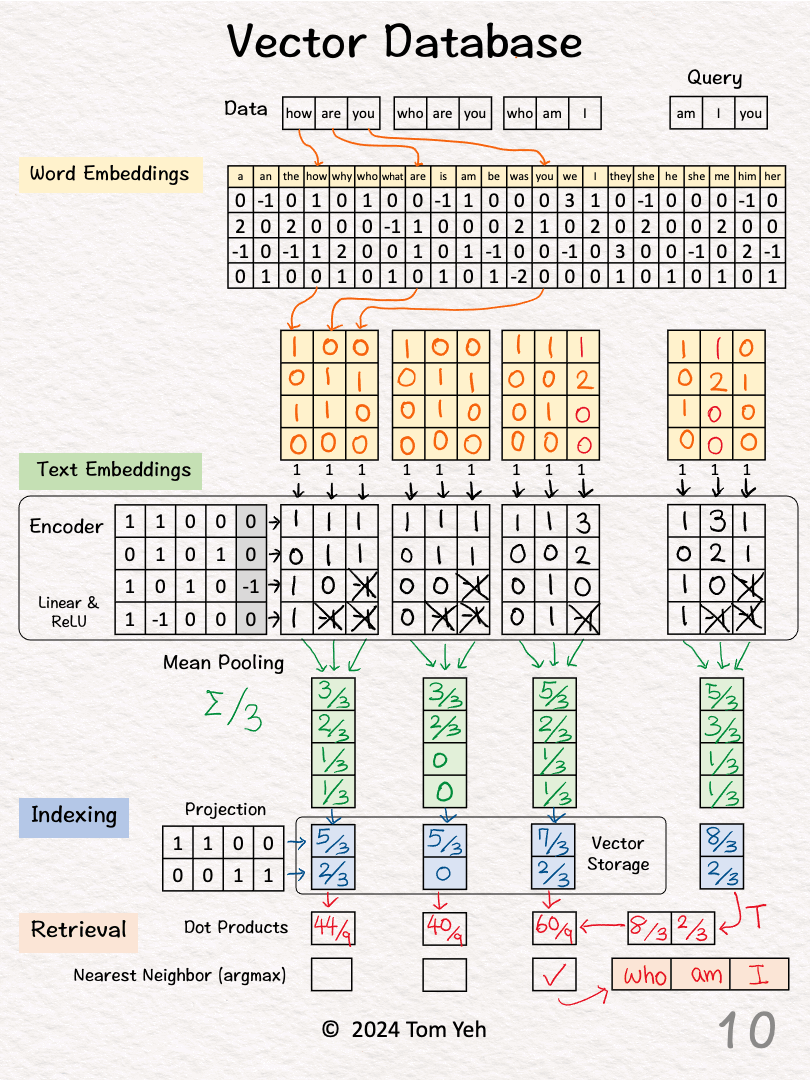
Setup
Step 1 of 10: Given
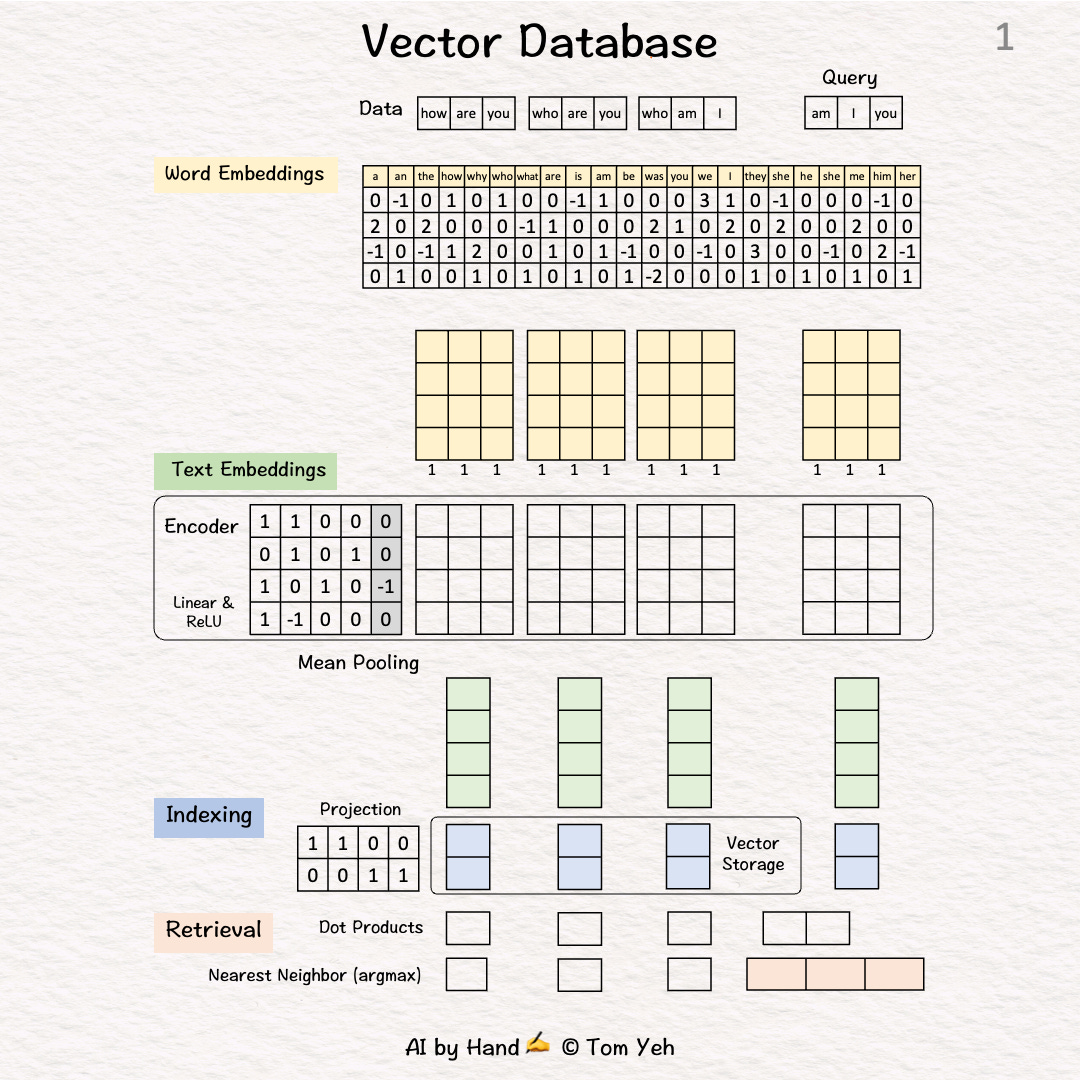
A dataset of three sentences, each has 3 words (or tokens)
In practice, a dataset may contain millions or billions of sentences. The max number of tokens may be tens of thousands (e.g., 32,768 mistral-7b).
Index the Dataset
Process "how are you"
Step 2 of 10: Word Embeddings
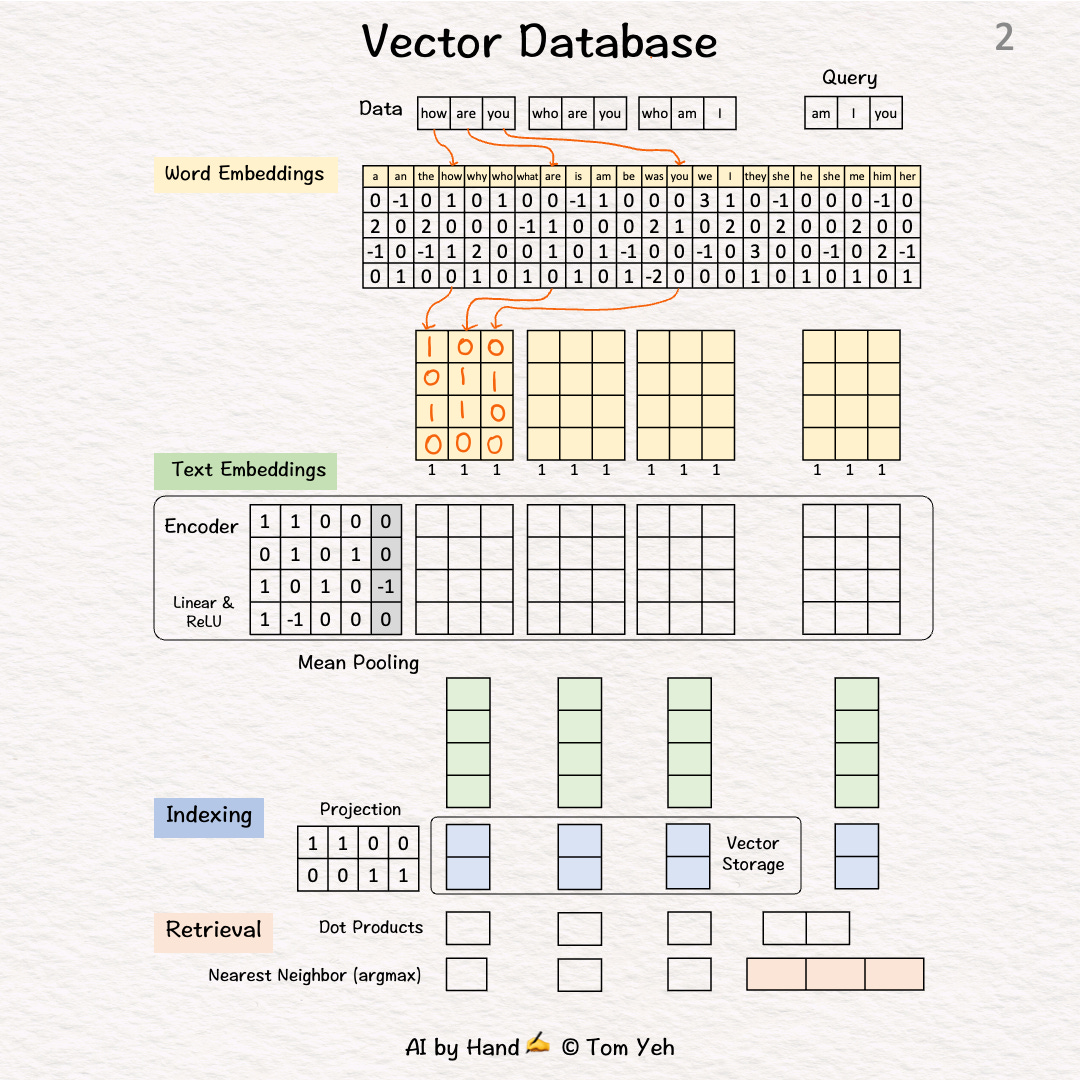
For each word, look up corresponding word embedding vector from a table of 22 vectors, where 22 is the vocabulary size.
In practice, the vocabulary size can be tens of thousands. The word embedding dimensions are in the thousands (e.g., 1024, 4096)
Step 3 of 10: Encoding
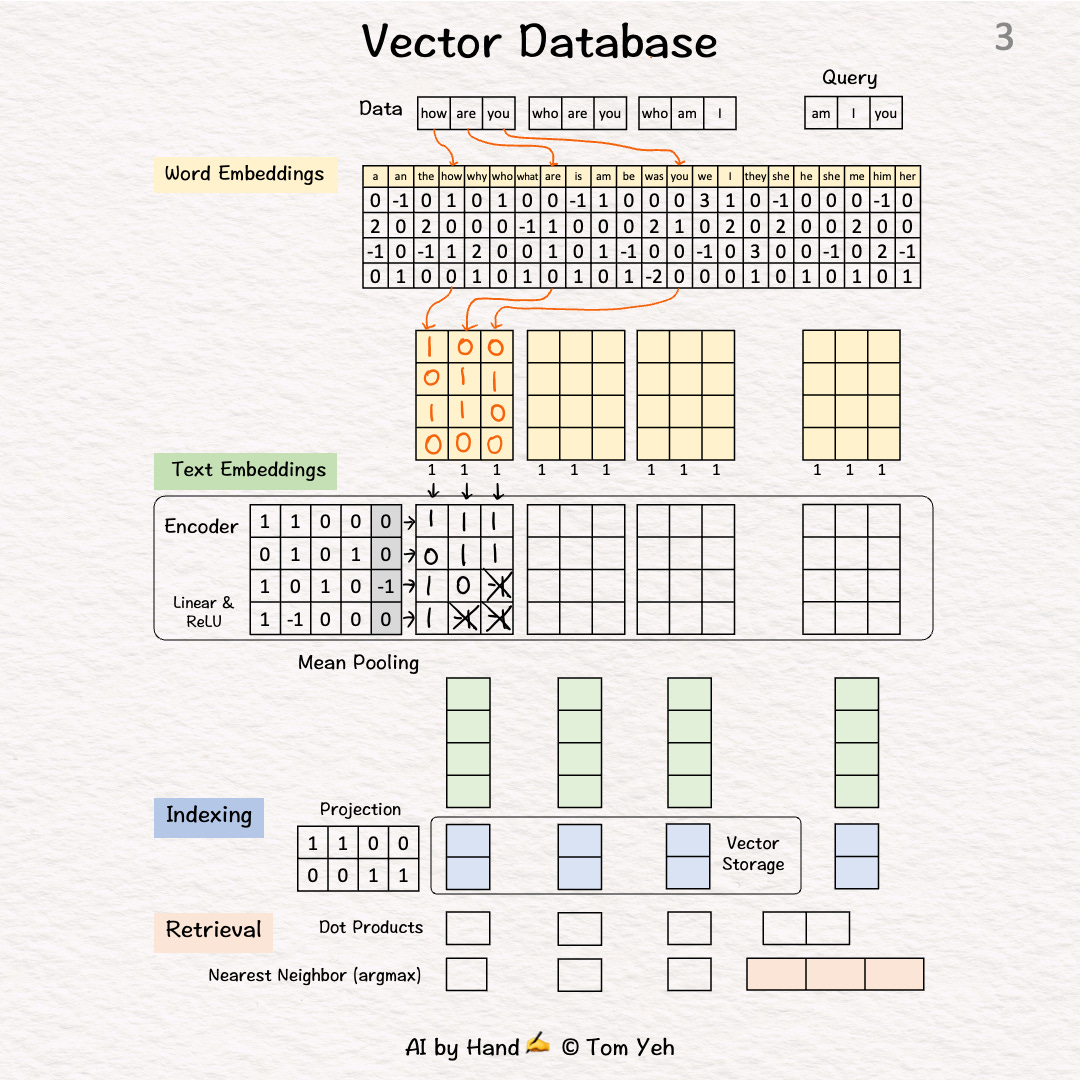
Feed the sequence of word embeddings to an encoder to obtain a sequence of feature vectors, one per word.
Here, the encoder is a simple one layer perceptron (linear layer + ReLU)
In practice, the encoder is a transformer or one of its many variants.