
Residual Network by Hand ✍️
Calculating AI by Hand: 17 of 28

Library › Calculating AI by Hand ✍️
Residual Network by Hand ✍️
Reinforcement Learning with Human Feedback (RLHF) by Hand ✍️
ResNet, "Deep Residual Learning for Image Recognition" by Kaiming He (CVPR 2016), is among the most cited deep learning papers ever.
Why is it so important?
It found a simple solution to the exploding and diminishing gradient problems of deep networks, making thousands of layers possible.
How simple? An identity matrix.
Residual Block
Step 1 of 10: Given
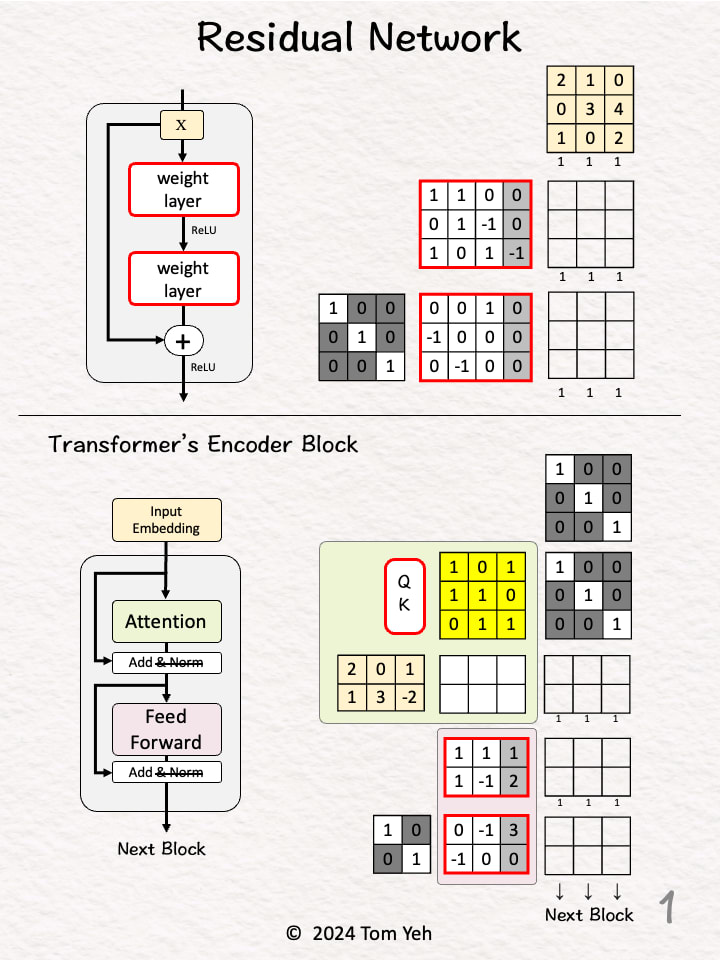
A mini batch of 3 input vectors (3D)
Step 2 of 10: Linear Layer
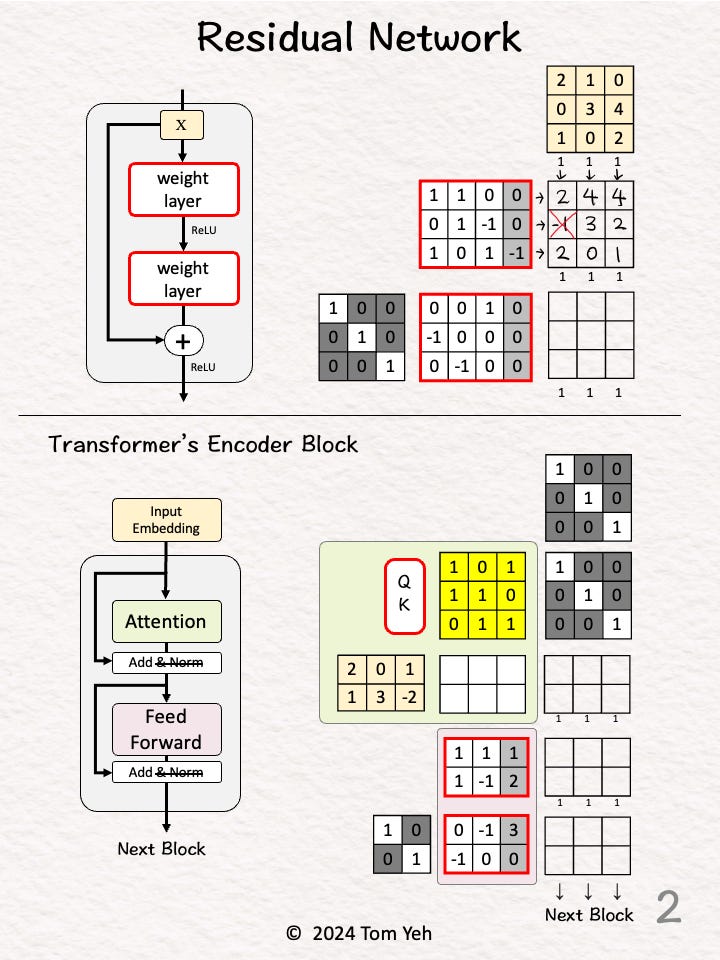
Multiply the input with weights and bias
Apply ReLU (negatives → 0)
Obtain 3 feature vectors
Step 3 of 10: Concatenate
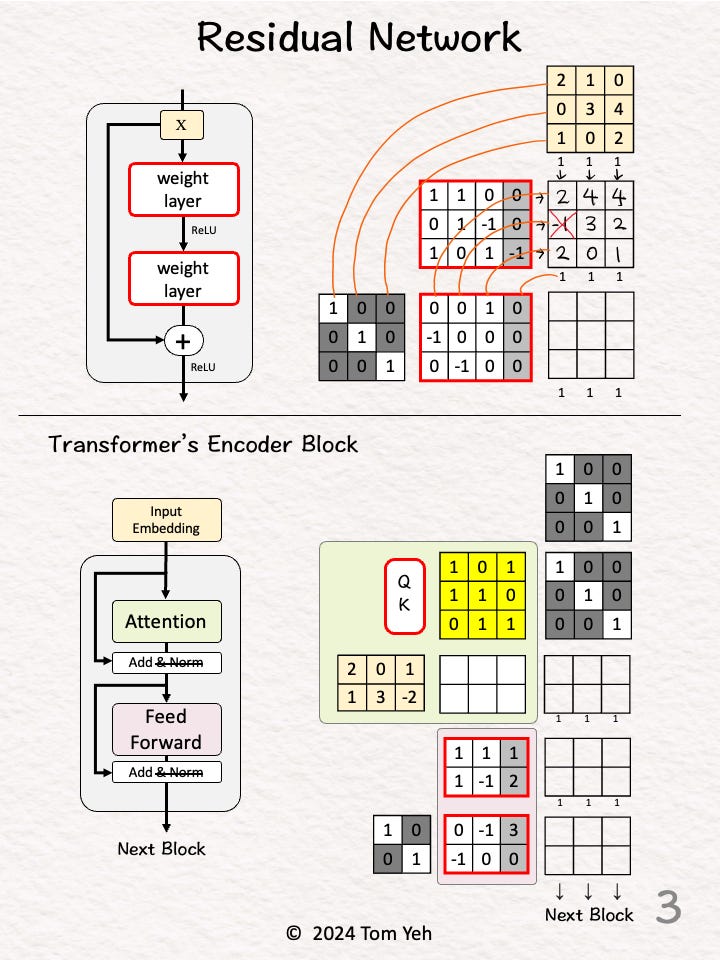
Stack (horizontally) an identity matrix and the weight and bias matrix of the 2nd layer
Stack (vertically) the input vectors and the feature vectors from the previous layer
Draw lines to visualize the links between rows (weights) and columns (features)
These links are the "Skip Connections"