
Graph Convolutional Network (GCN) by Hand ✍️
Calculating AI by Hand: 20 of 28

Library › Calculating AI by Hand ✍️
Graph Convolutional Network (GCN) by Hand ✍️
Reinforcement Learning with Human Feedback (RLHF) by Hand ✍️
Graph Convolutional Networks (GCNs), introduced by Thomas Kipf and Max Welling in 2017, have emerged as a powerful tool in the analysis and interpretation of data structured as graphs.
GCNs have found many successful applications:
Social network analysis
Recommendation systems
Biological network interpretation
Drug discovery
Molecular chemistry
This exercise demonstrates how GCN works in a simple application: binary classification.
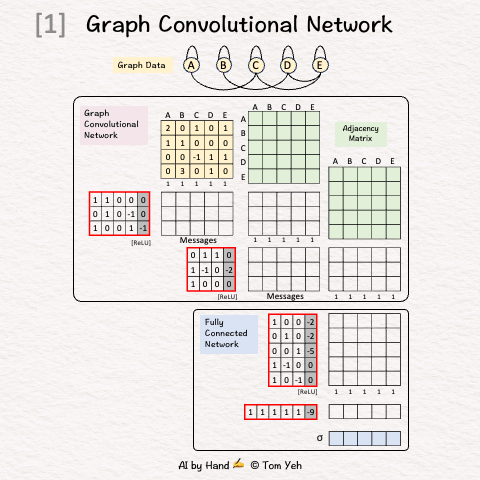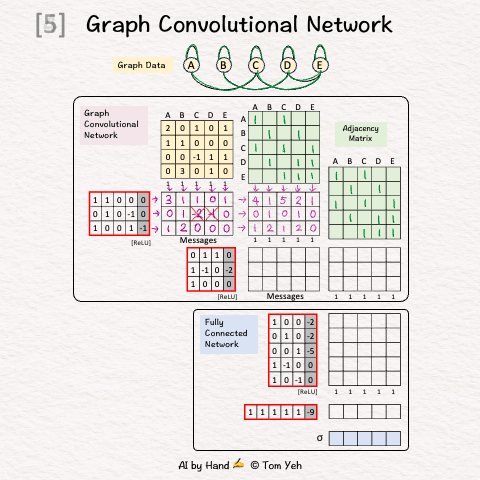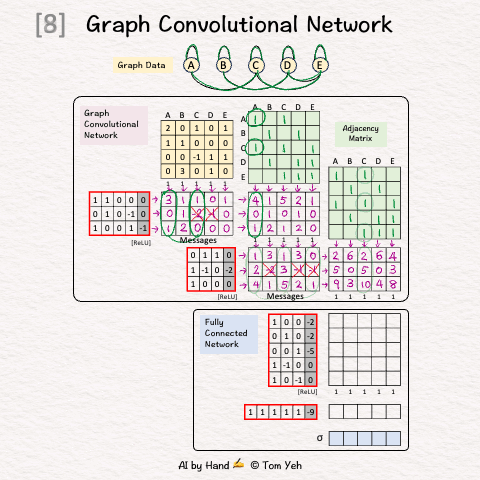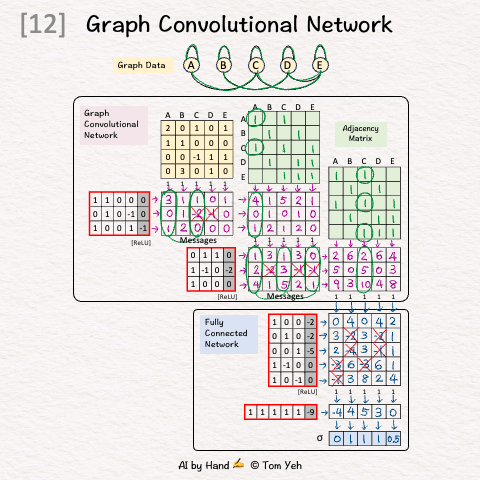
Goal
Predict if a node in a graph is X.
Architecture
🟪 Graph Convolutional Network (GCN)
GCN1(4,3)
GCN2(3,3)
🟦 Fully Connected Network (FCN)
Linear1(3,5)
ReLU
Linear2(5,1)
Sigmoid
Simplications:
Adjacent matrices are not normalized.
ReLU is applied to messages directly.
Setup
Step 1 of 12: Given
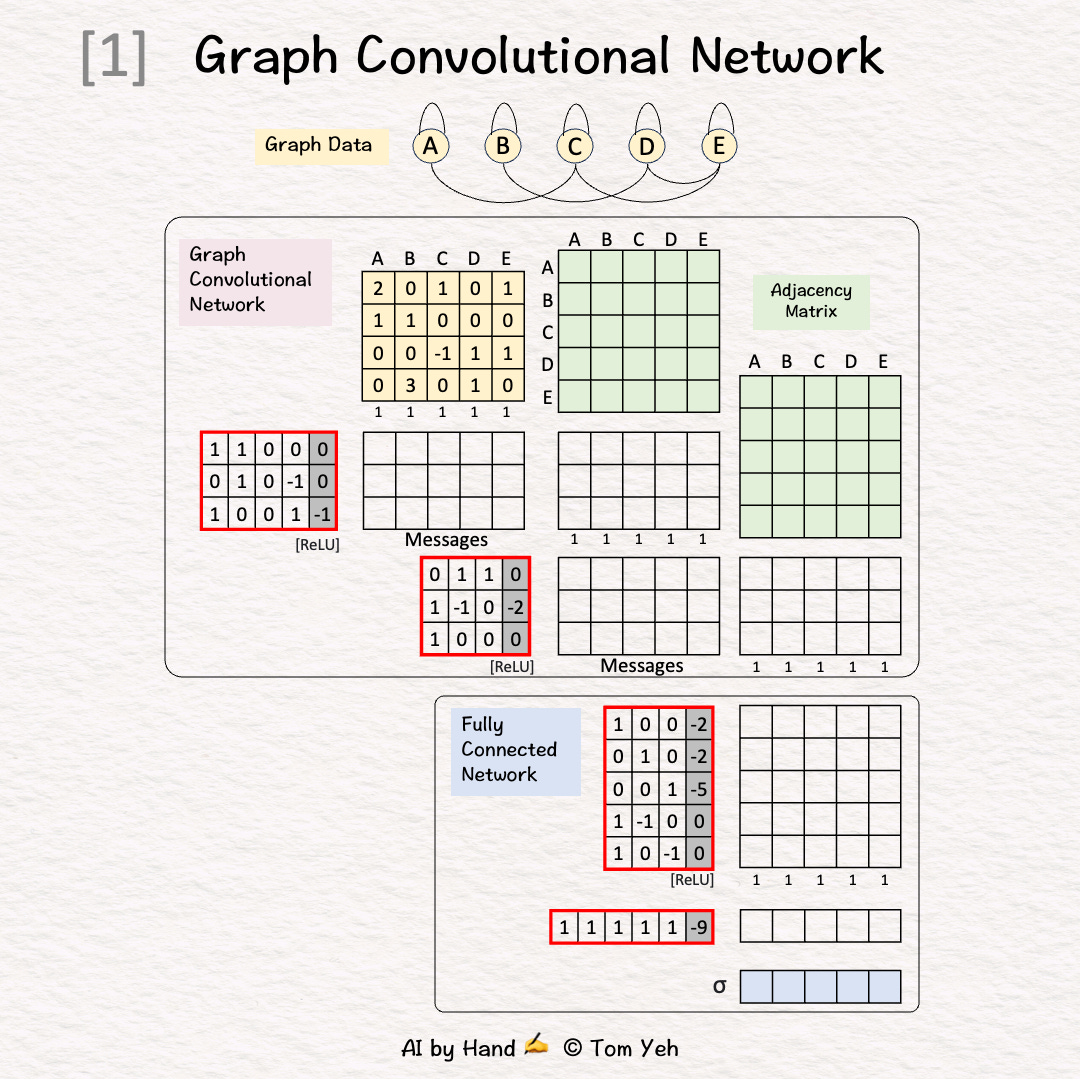
A graph with five nodes A, B, C, D, E
Step 2 of 12: Adjacency Matrix (Neighbors)
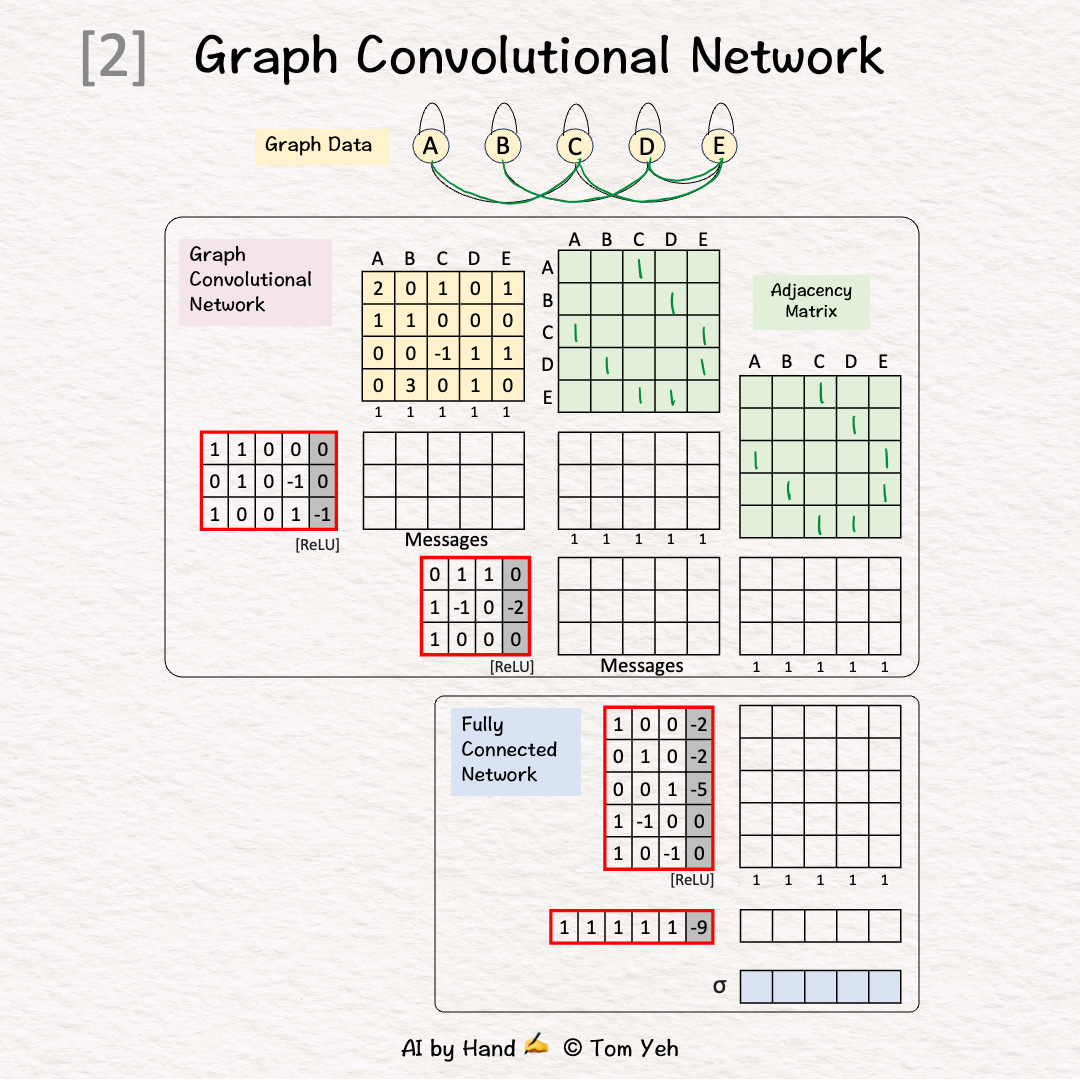
Add 1 for each edge to neighbors
Repeat in both directions (e.g., A->C, C->A)
Repeat for both GCN layers
Step 3 of 12: Adjacency Matrix (Self)
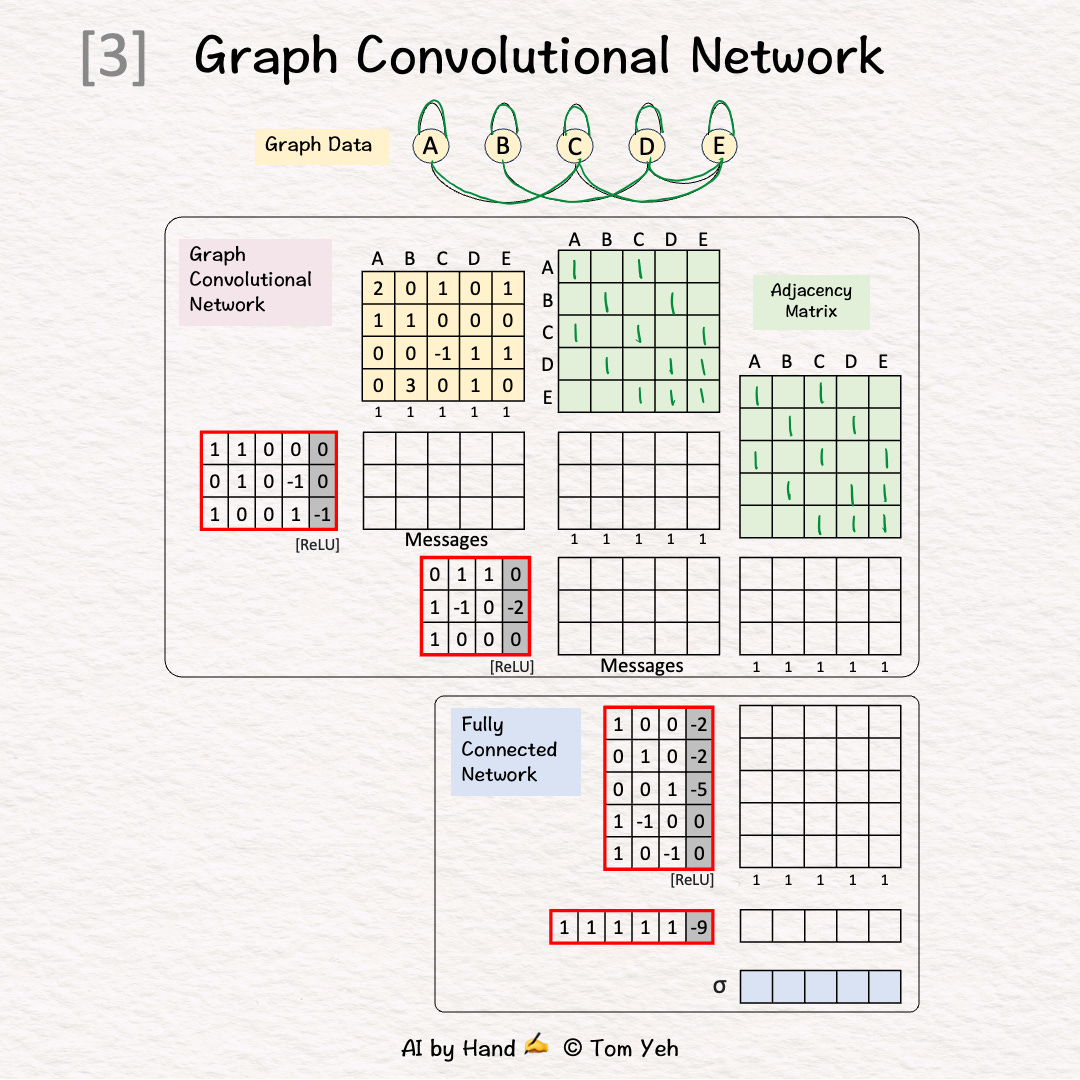
Add 1's for each self loop
Equivalent to adding the identity matrix
Repeat for both GCN layers