
Recurrent Neural Network (RNN) by Hand ✍️

Today is the final exam for the Computer Vision course. I hope my students are ready!
Even though RNN was not originally invented for Computer Vision tasks, I believe it is important for students in my Computer Vision course to practice calculating an RNN by hand to gain a good intuition about how an RNN processes a sequence. Later, when I teach students how to calculate a vision transformer (ViT) model, it is easier for students to see the differences, especially how a transformer processes all tokens in parallel.
Moreover, several people recommended me to do a post about Mamba (Pascal Biese, Steve Solun). RNN is a prerequisite to understand Mamba.
𝗪𝗮𝗹𝗸𝘁𝗵𝗿𝗼𝘂𝗴𝗵
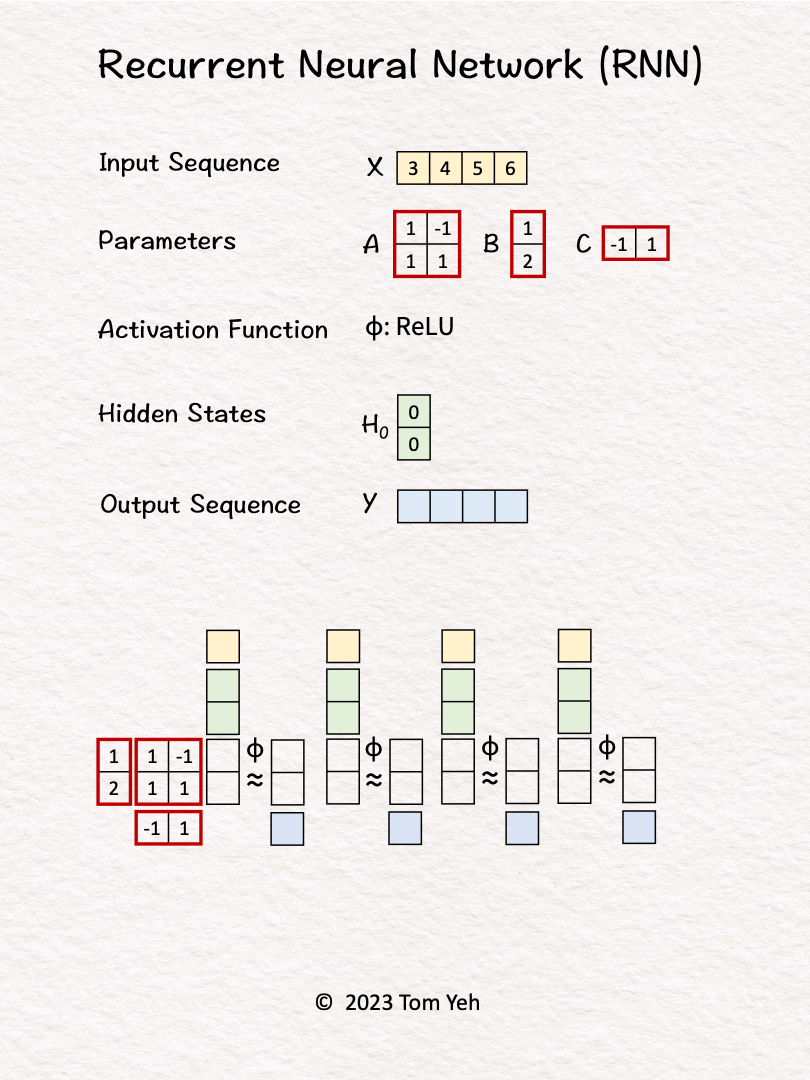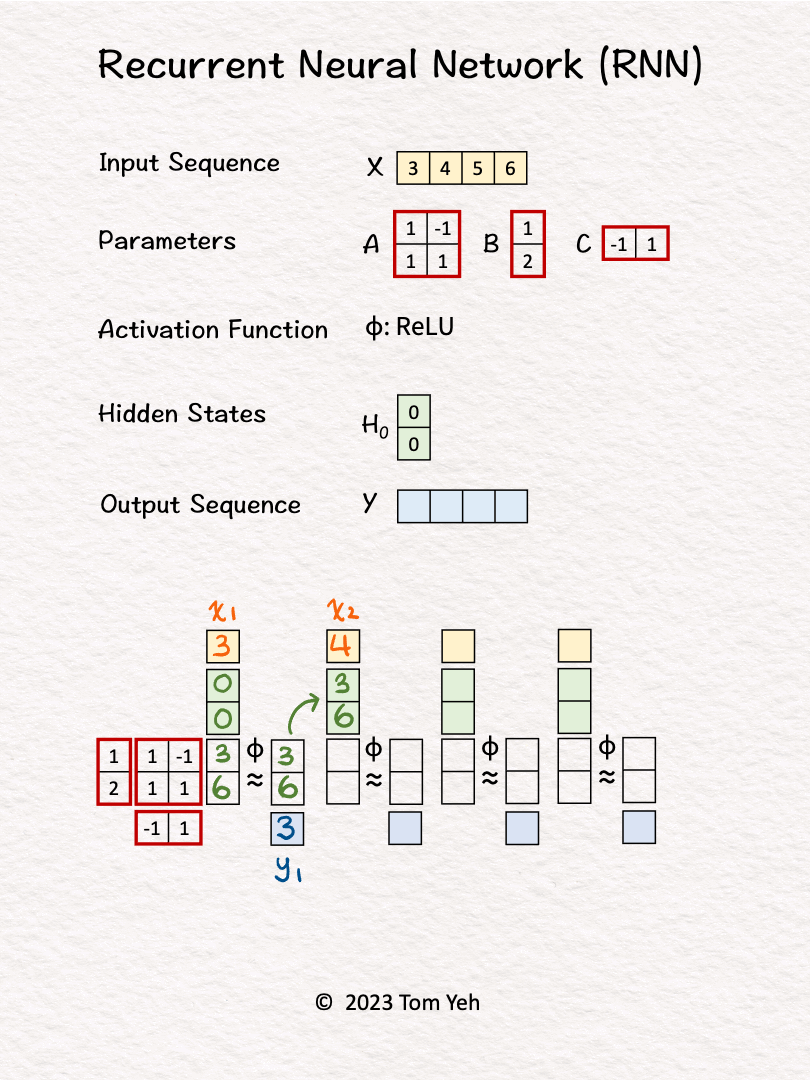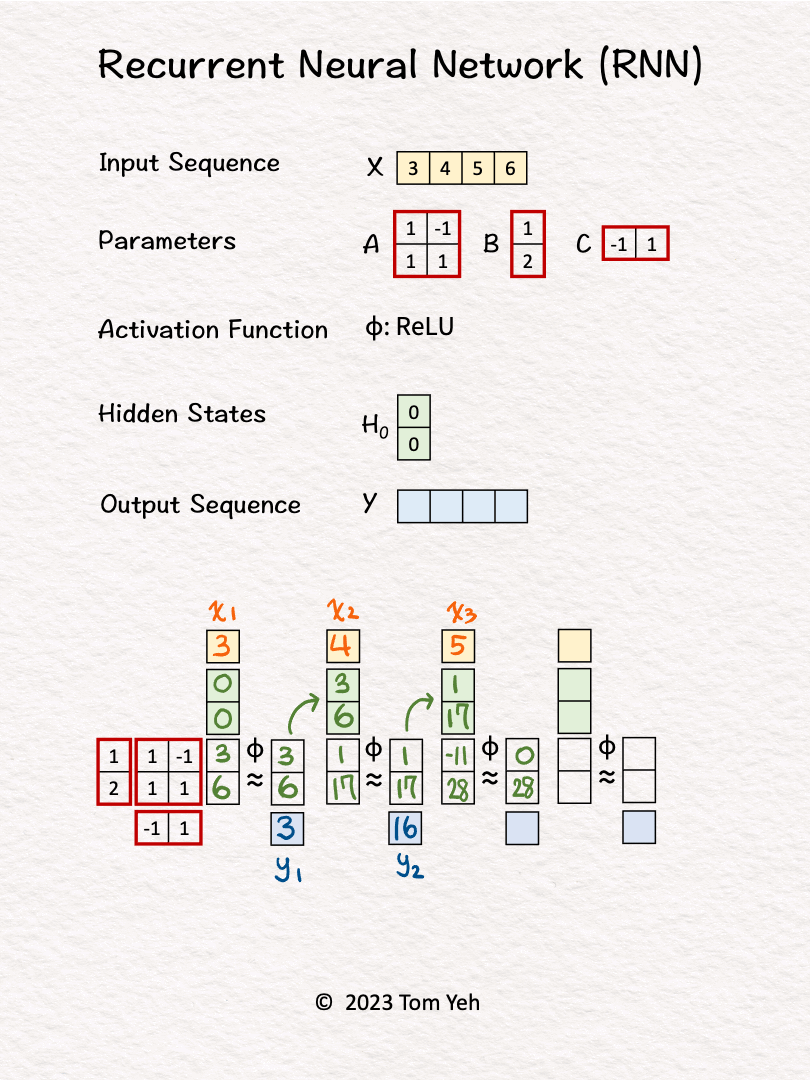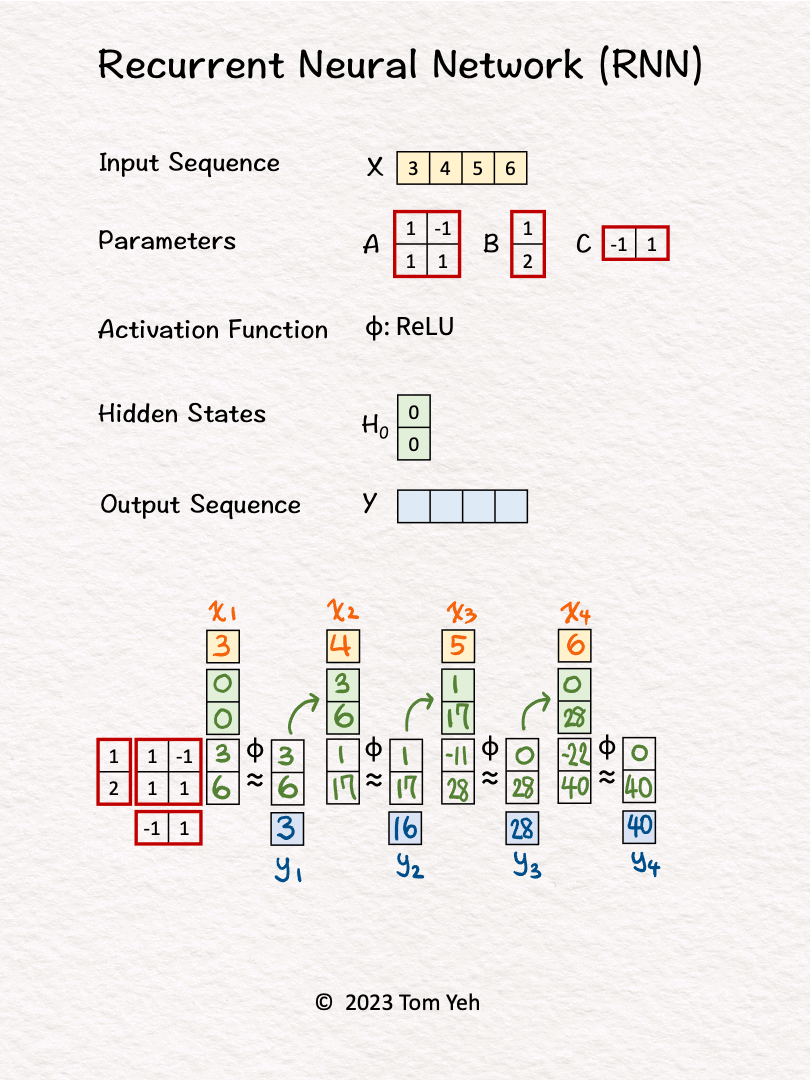
1. Hidden state are initialized to [0, 0].
2. The first input 𝘹1 and hidden states [0, 0] are linearly combined using weights 𝘈 and 𝘉, followed by a non-linear activation function ReLu, to calculate the new hidden states -> [3, 6].
3. Hidden states [3, 6] are linearly combined using weights 𝘊 to obtain the first output 𝘺1
4. Repeat 1-3 for 𝘹2, 𝘹3, 𝘹4
𝗞𝗲𝘆 𝗣𝗿𝗼𝗽𝗲𝗿𝘁𝗶𝗲𝘀
💡Parameters: The same set of parameter matrices (A, B, C) are reused to process each input token. This is the main reason why we use the word 𝘳𝘦𝘤𝘶𝘳𝘳𝘦𝘯𝘵.
💡Sequential: An RNN sequentially processes each input token and produces each output token in turn. An RNN can not process all tokens in parallel. In contrast, the Transformer model can process all tokens in parallel using attention.
Let me know if you have any questions!
Stay tuned for my next post about Mamba!
Superb sir. Could you please send me your email ID for my doubts in sequence of numbers generated algorithm. Thanks sir.