
Mamba's S6 by Hand ✍️
Calculating AI by Hand: 25 of 28

Library › Calculating AI by Hand ✍️
Mamba's S6 by Hand ✍️
Reinforcement Learning with Human Feedback (RLHF) by Hand ✍️
Mamba is a linear-time sequence model that rivals the Transformer, whose attention is quadratic-time. At its core is the S6 model: Structured State-Space Sequence modeling using a Selective Scan.
This exercise works through S6 by hand on a small example (1D, 4 tokens, 2 hidden states).
How does Mamba's S6 work?
Setup
Step 1 of 10: Given
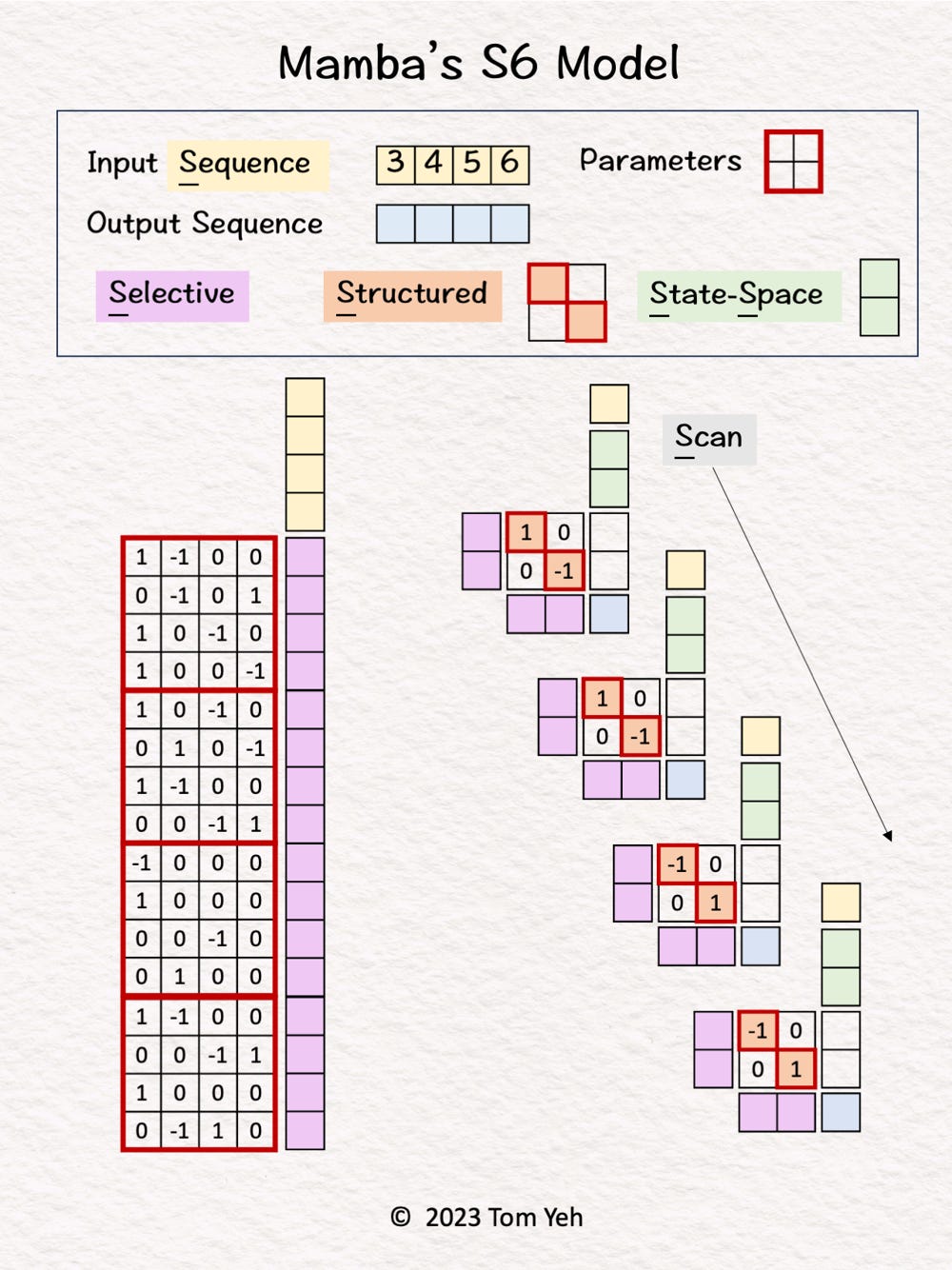
An input sequence of 4 tokens (1D), with 2 hidden states.
The parameters that drive the S6 model.
Linear Layer
Step 2 of 10: Predict Weights
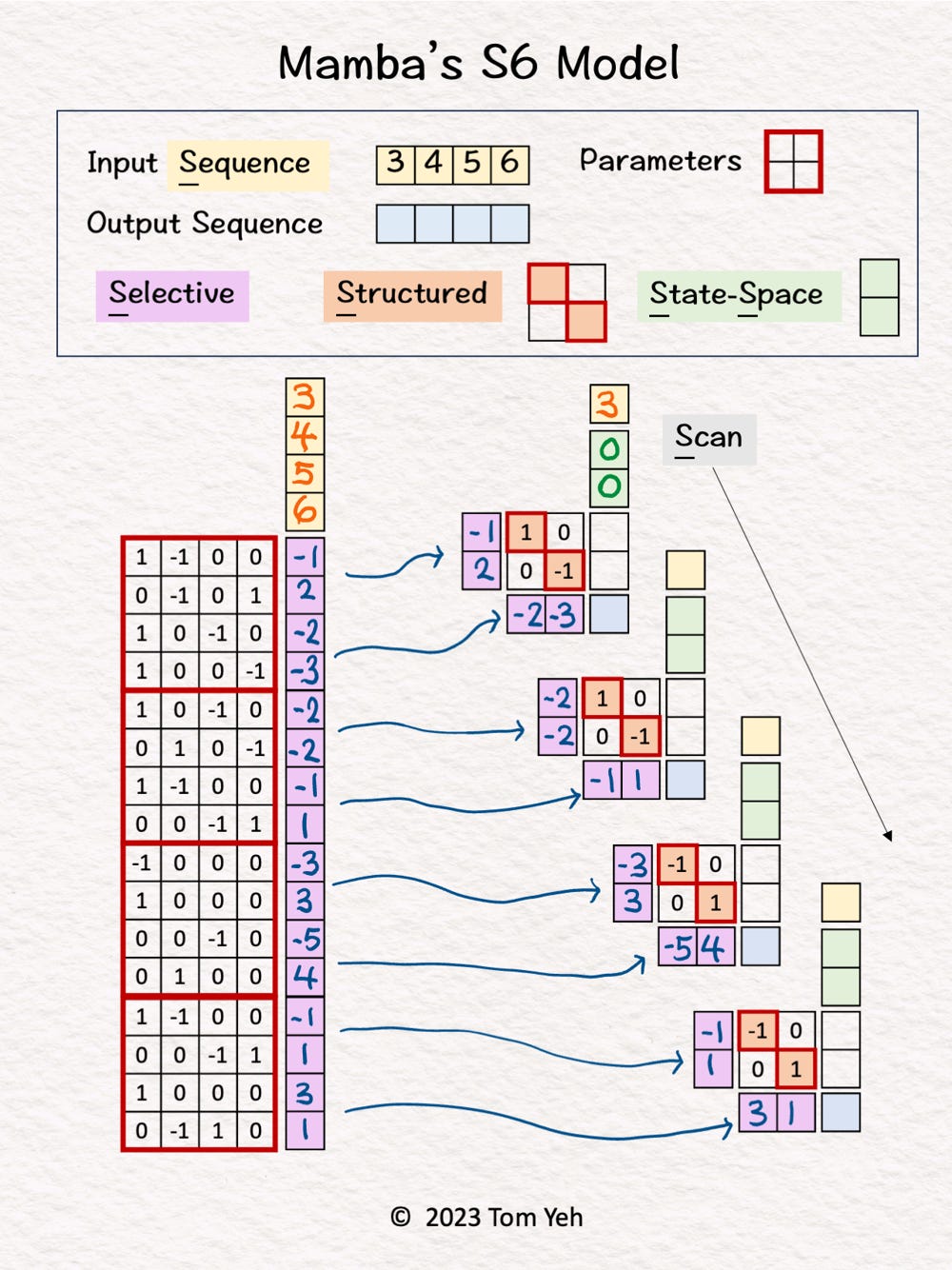
All four tokens are processed by a linear layer to predict a per-token set of weights A, B, and C.
These weights drive an RNN-like network (right).
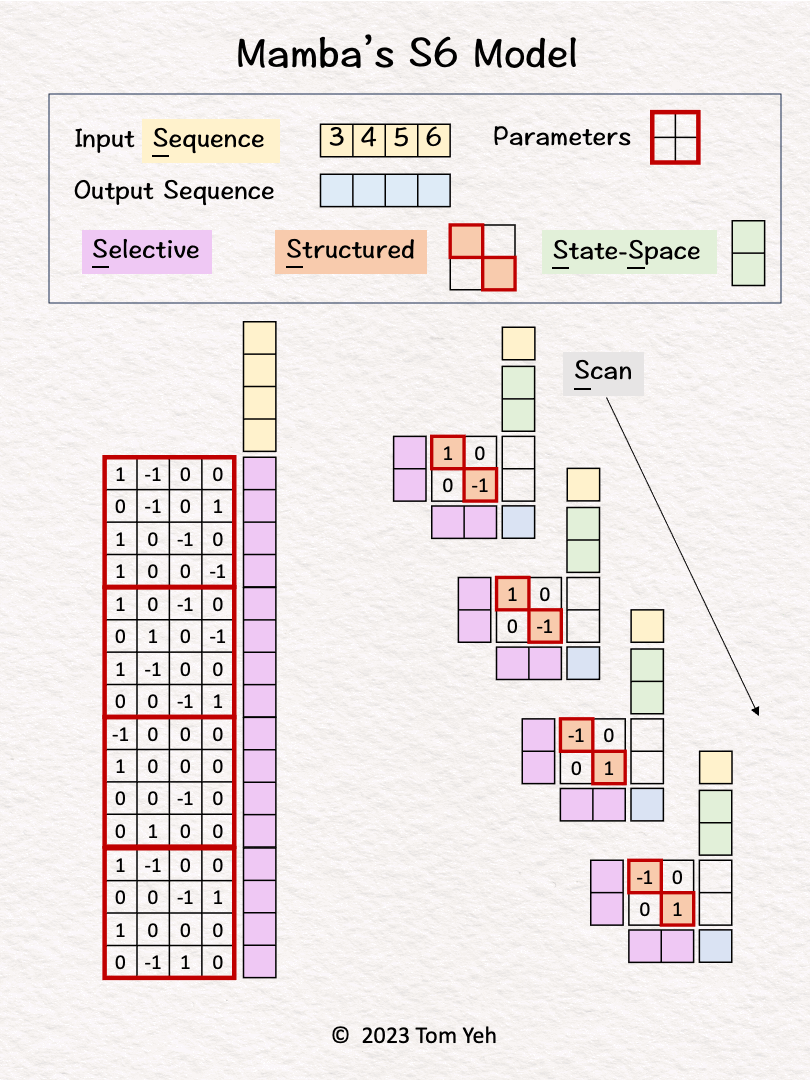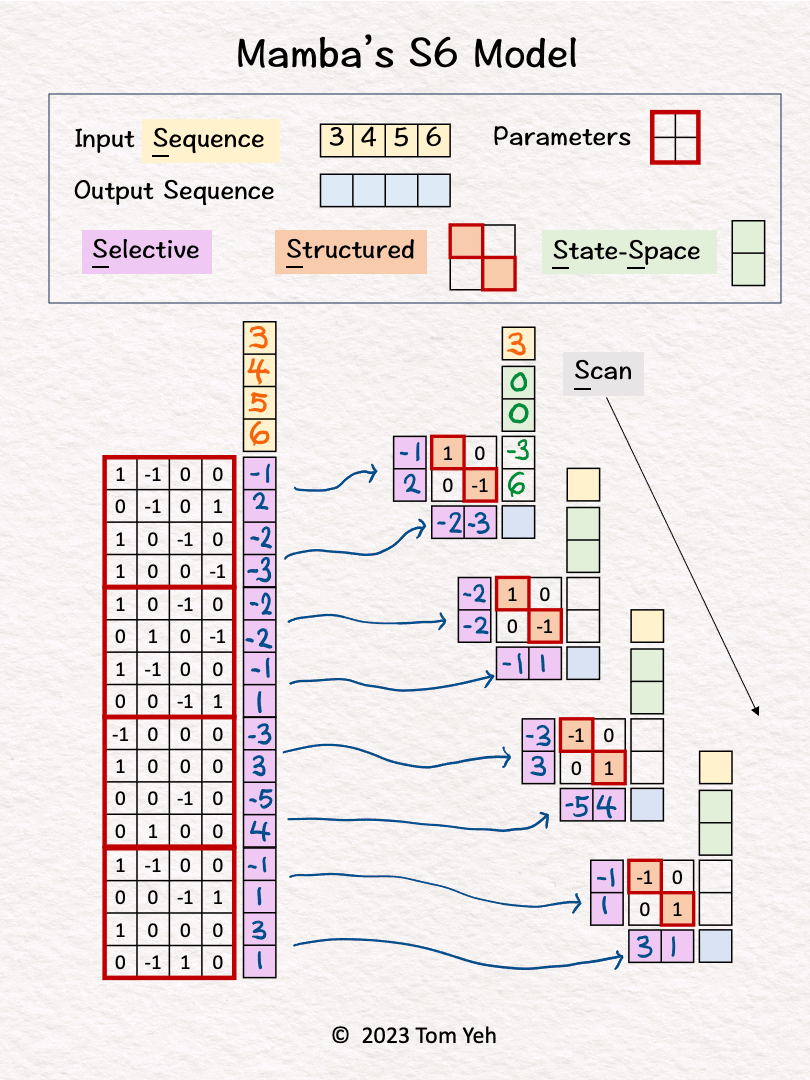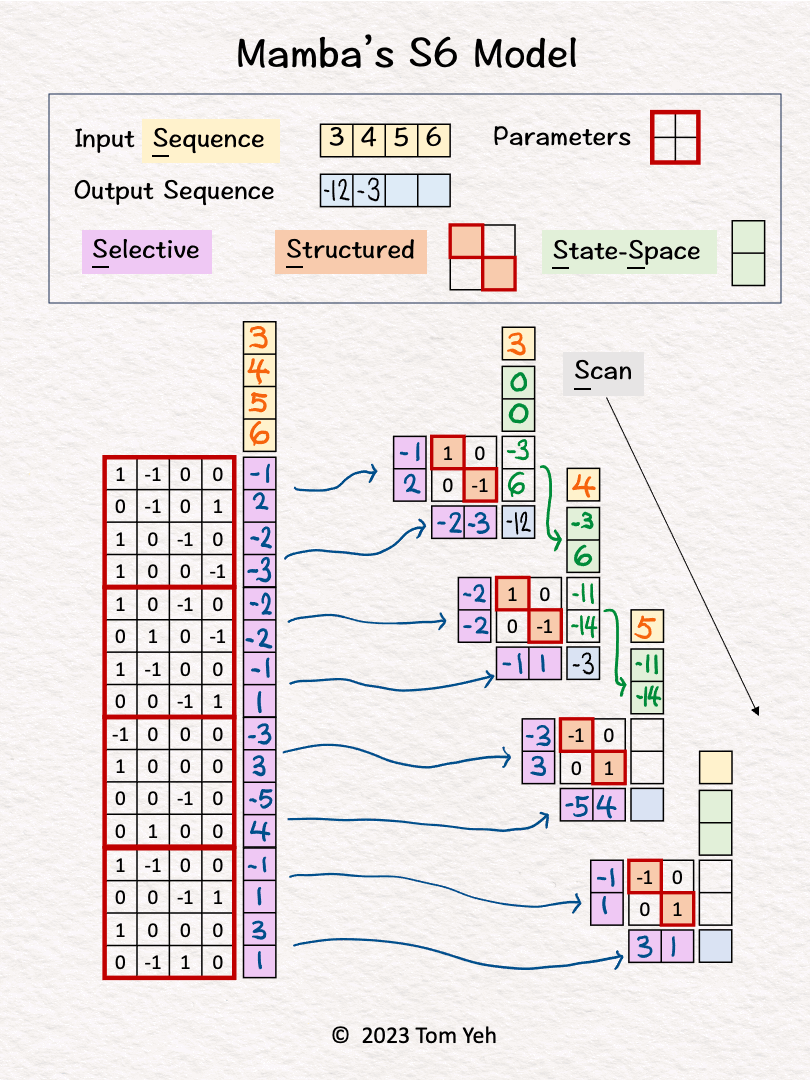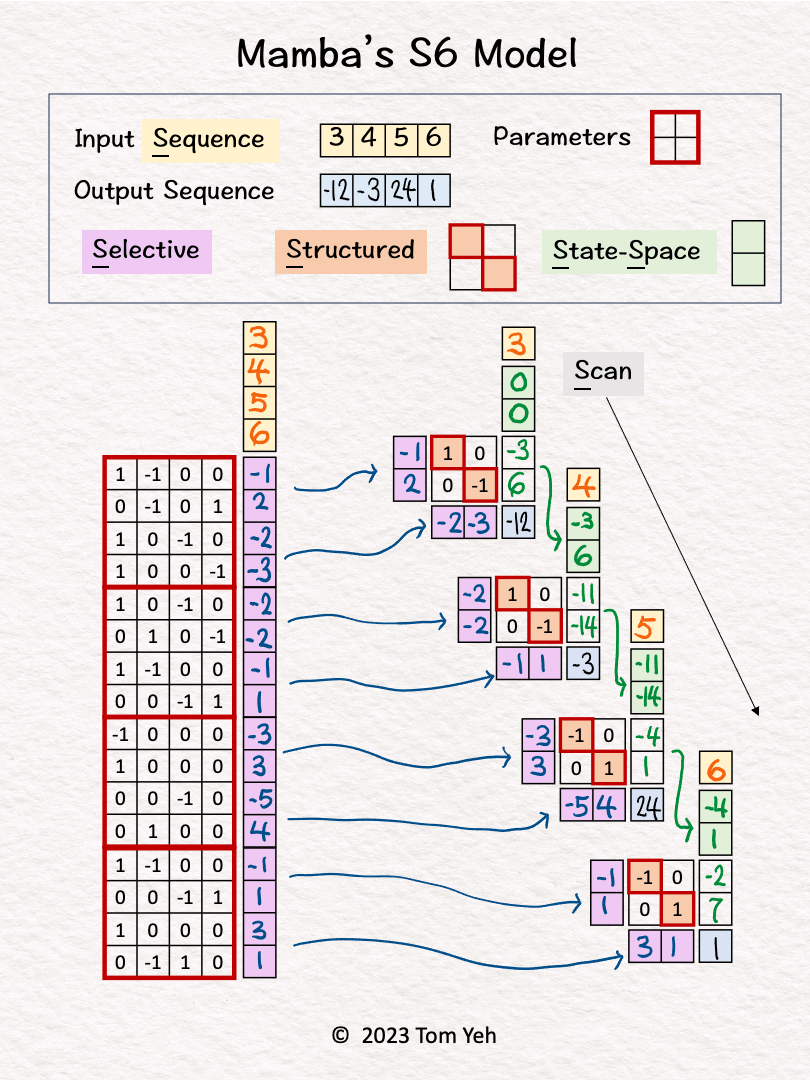
Selective Scan
Step 3 of 10: Token 1 Hidden States
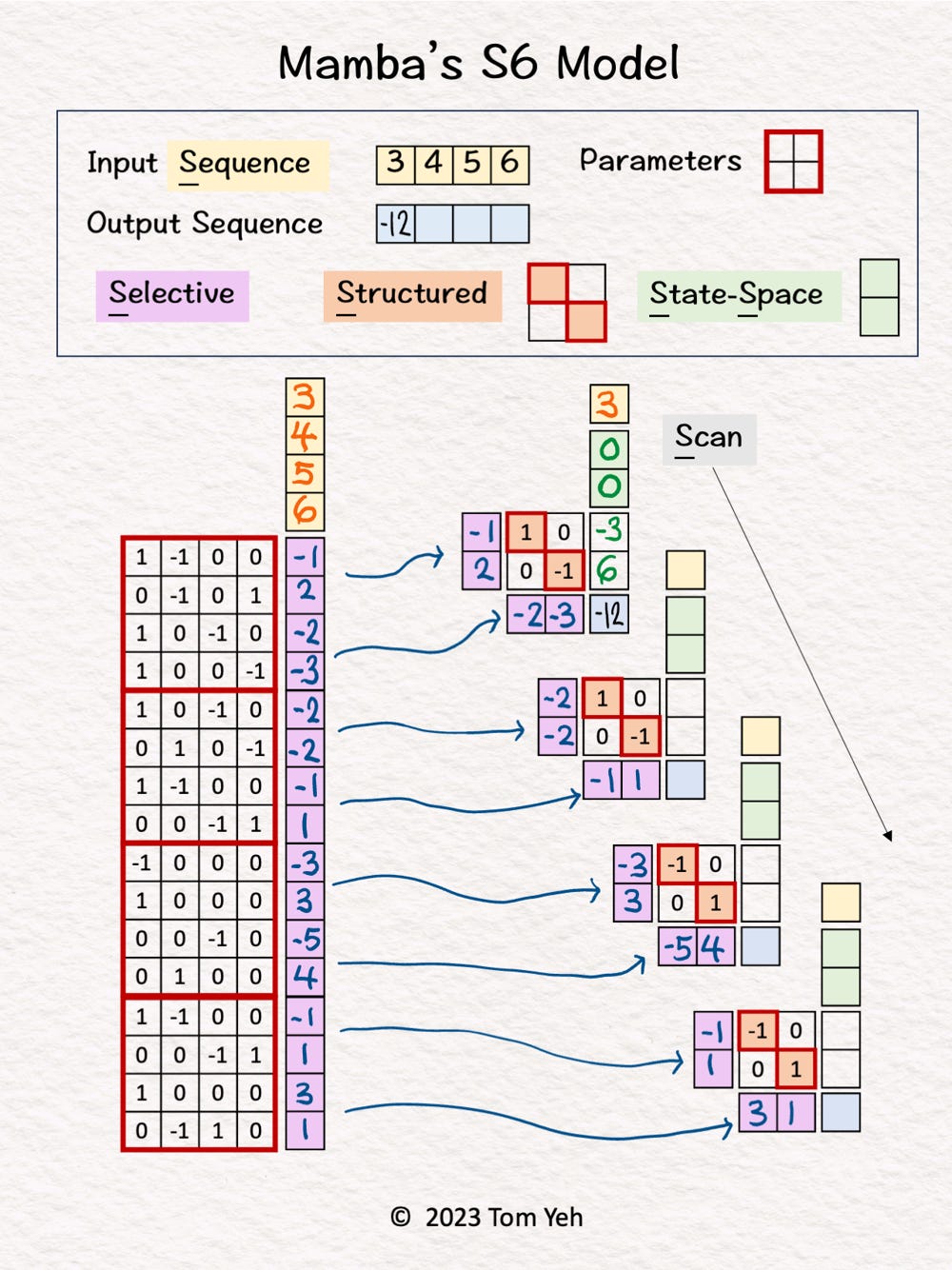
Linearly combine the first input [3] and the hidden states [0, 0] using B = [-1; 2] and A = [1, 0; 0, -1] to obtain new hidden states [-3, 6].
No non-linear activation function is involved.