
Sampling a Sentence by Hand ✍️

In my course, I go over how exactly each pixel in an image or each word in a sentence is sampled from a probability distribution. The most common visualization of a probability distribution of images or sentences is a cloud. But some students found the cloud representation still too "cloudy." Thus, I made this by-hand exercise, using concrete numbers to dispel any lingering cloud in their understanding.
-- 𝗪𝗮𝗹𝗸𝘁𝗵𝗿𝗼𝘂𝗴𝗵 --
1. Given a sequence of input embeddings, represented as yellow column vectors.
2. Feed the input embeddings to the LLM.
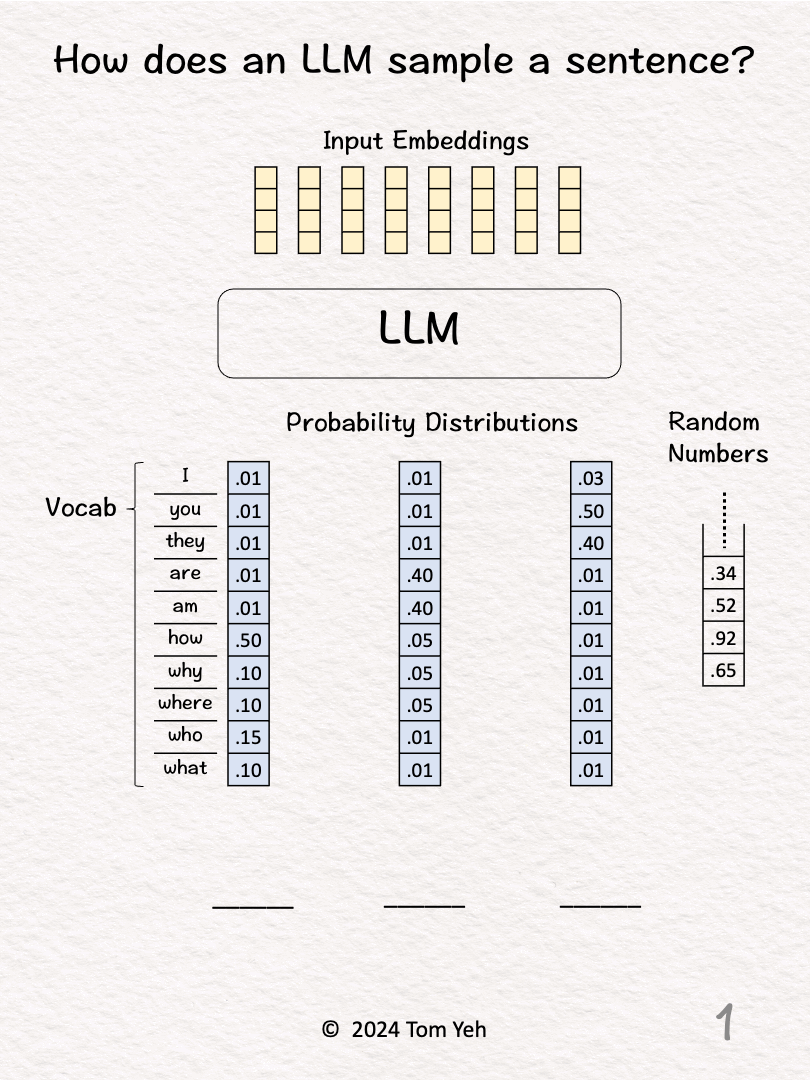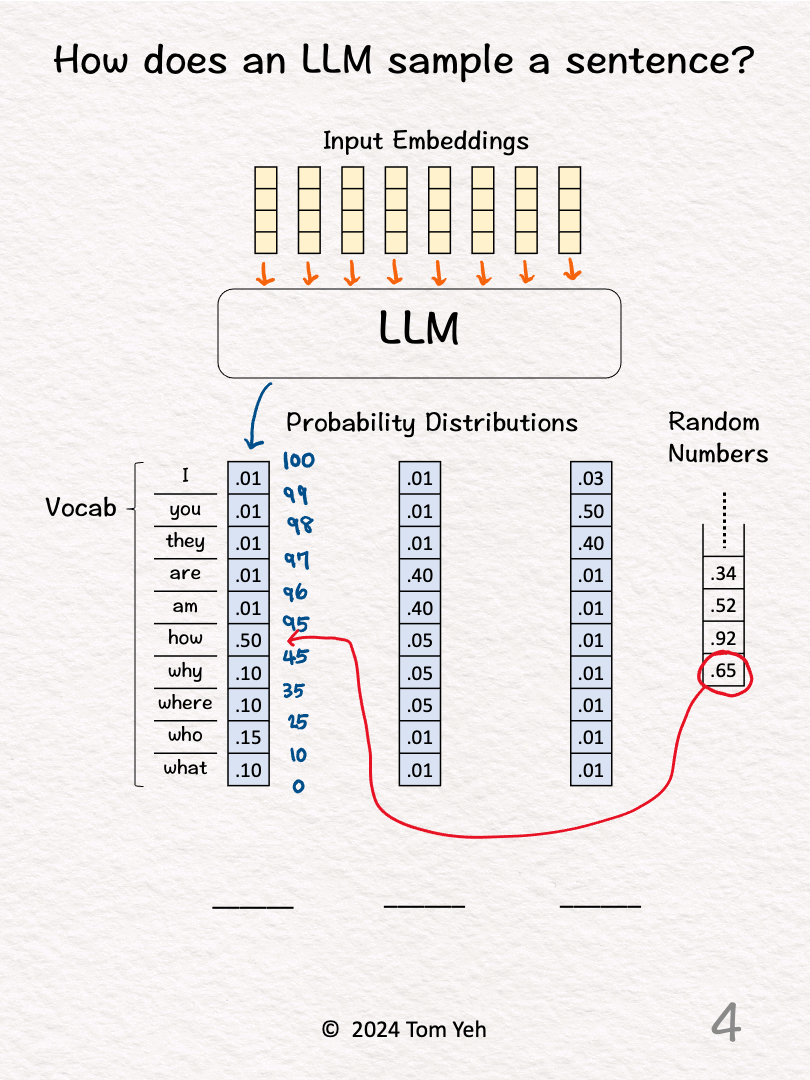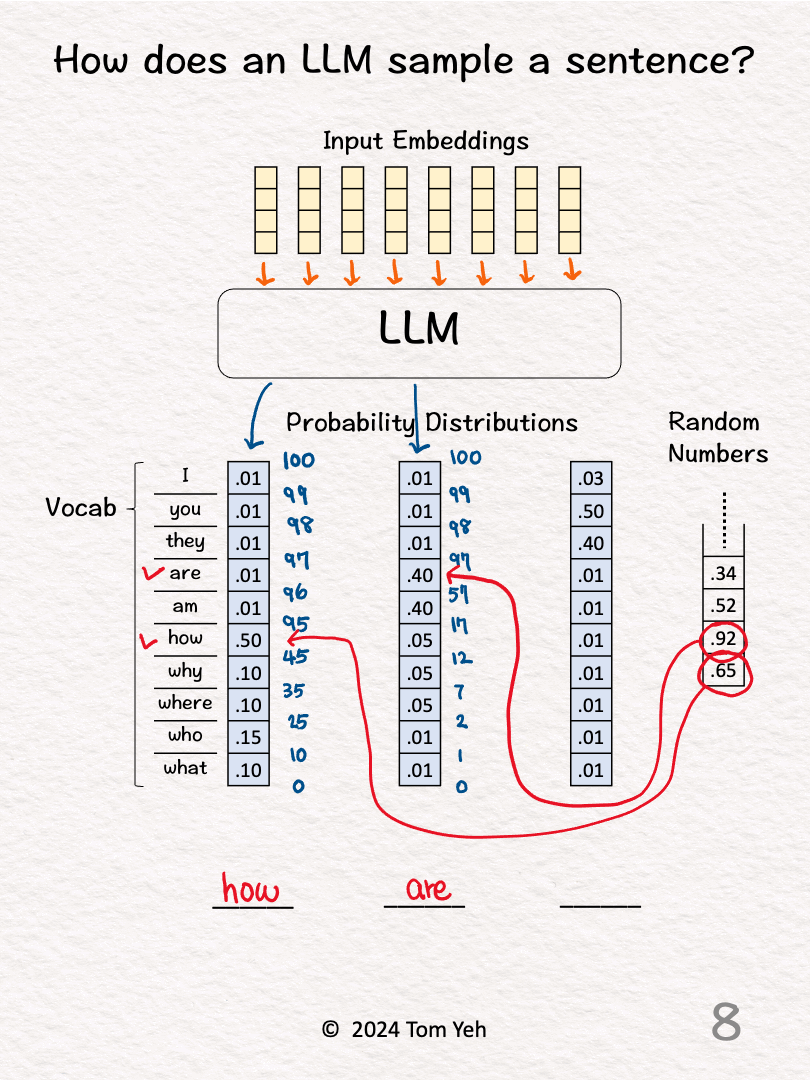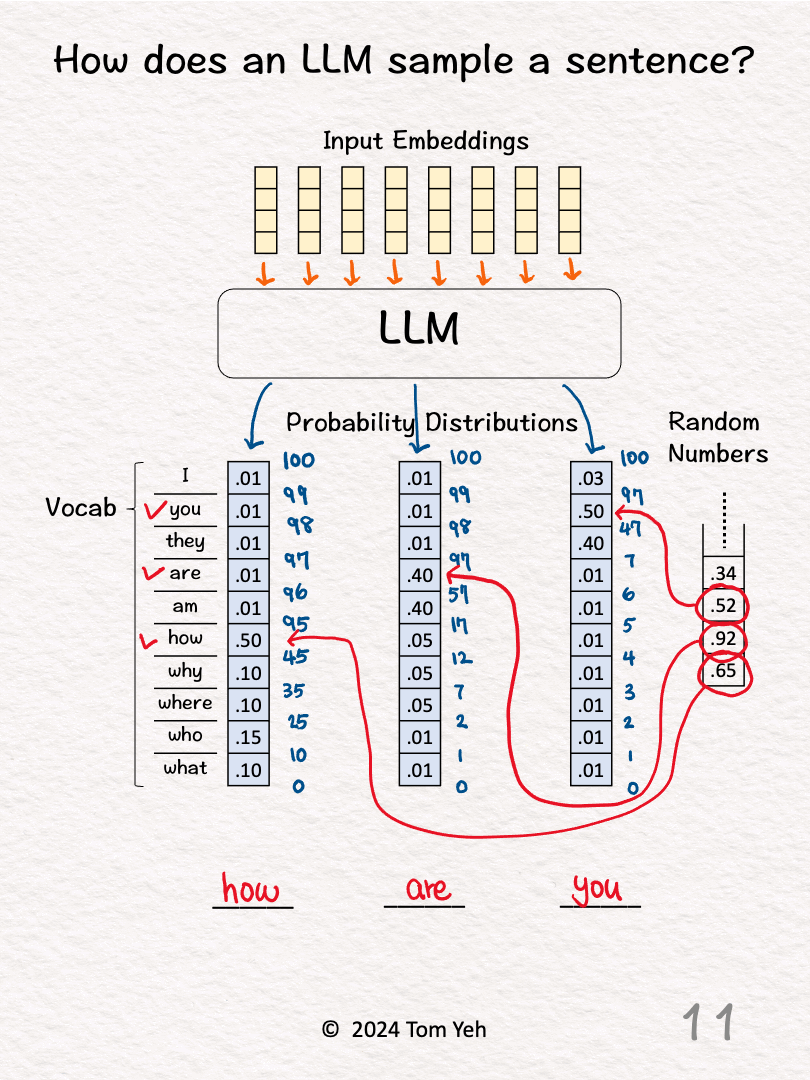
3. The LLM predicts the probability distribution of the next output word over a vocabulary of 10 words, which is represented as a column vector shaded in blue. Then, we calculate the cumulative distribution by hand and write the results in blue. To do so, we start with zero at the bottom, add the number in each cell as we go up, until we reach 100 at the top. Note that for a valid probability distribution, they should add up to 100 (percentage).
4. Draw the next random number (.65) and lookup the range in the cumulative distribution in which this random number falls (.45 < .65 < .95).
5. Lookup the corresponding word (how) and fill that word in the first blank.
6. Repeat step 3 for the next output word
7. Draw the next random number (.92) and lookup the range in the cumulative distribution in which this random number falls (.57 < .92 < .97).
8. Lookup the corresponding word (are) and fill that word in the second blank.
9. Repeat step 3 for the next output word
10. Draw the next random number (.52) and lookup the range in the cumulative distribution in which this random number falls (.47 < .52 < .97).
11. Lookup the corresponding word (you) and fill that word in the third blank.
-- 𝗞𝗲𝘆 𝗖𝗼𝗻𝗰𝗲𝗽𝘁𝘀 --
💡 𝗥𝗮𝗻𝗱𝗼𝗺𝗻𝗲𝘀𝘀: The randomness of LLM's outputs come from a random number generator. To draw a random number is like randomly throwing a dart at a dart board. The outcome is random. The dart will land somewhere. We can't guarantee where. But we can say it's likely to land in areas that are larger and less likely to land in areas that are smaller.
💡 𝗗𝗶𝘃𝗲𝗿𝘀𝗶𝘁𝘆: This randomness is what gives diversity to LLM's outputs.
💡 𝗧𝗲𝗺𝗽𝗲𝗿𝗮𝘁𝘂𝗿𝗲: This hyper-parameter is often used to control the degree of diversity. In this basic exercise, temperature is omitted. Later I will share a more advanced exercise to see the effects of temperature.
💡 𝗜𝗻𝘃𝗲𝗿𝘀𝗲 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺 𝗦𝗮𝗺𝗽𝗹𝗶𝗻𝗴: If you are familiar with probability theory, you can see this exercise is a simplified version of inverse transform sampling.