
Backpropagation by Hand ✍️
Calculating AI by Hand: 3 of 28

Library › Calculating AI by Hand ✍️
Backpropagation by Hand ✍️
Reinforcement Learning with Human Feedback (RLHF) by Hand ✍️
Backpropagation computes the gradient of the loss with respect to every weight, working backward layer by layer, so the network can learn.
Forward Pass
Step 1 of 11: Given
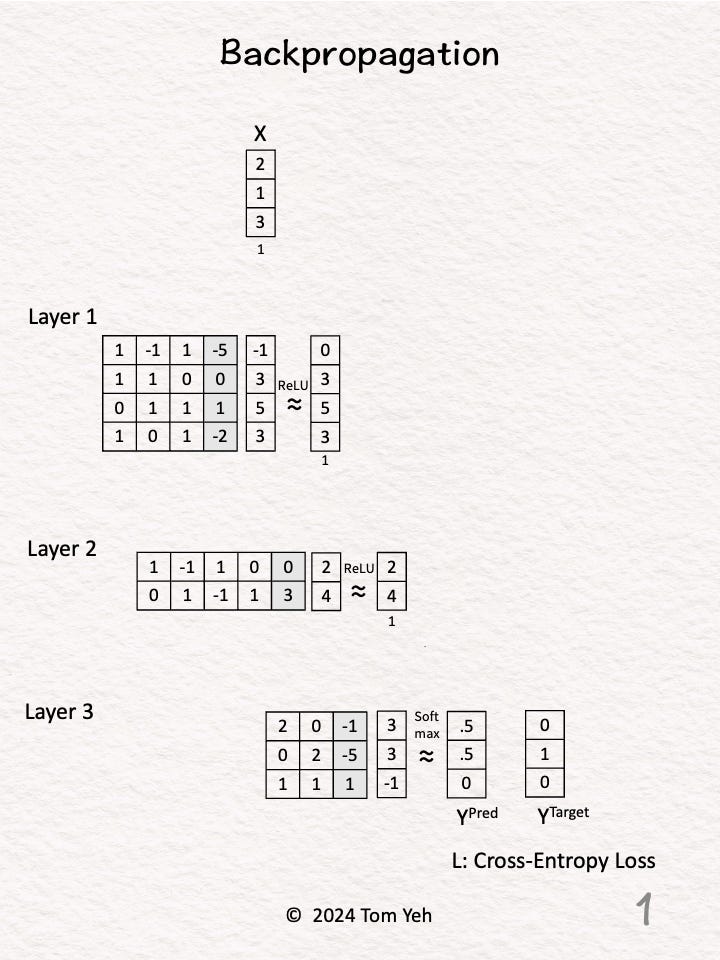
Given a multi layer perceptron (3 levels), an input vector X, predictions Y^{Pred} = [0.5, 0.5, 0], and ground truth label Y^{Target} = [0, 1, 0].
Backward Pass
Step 2 of 11: Insert Cells
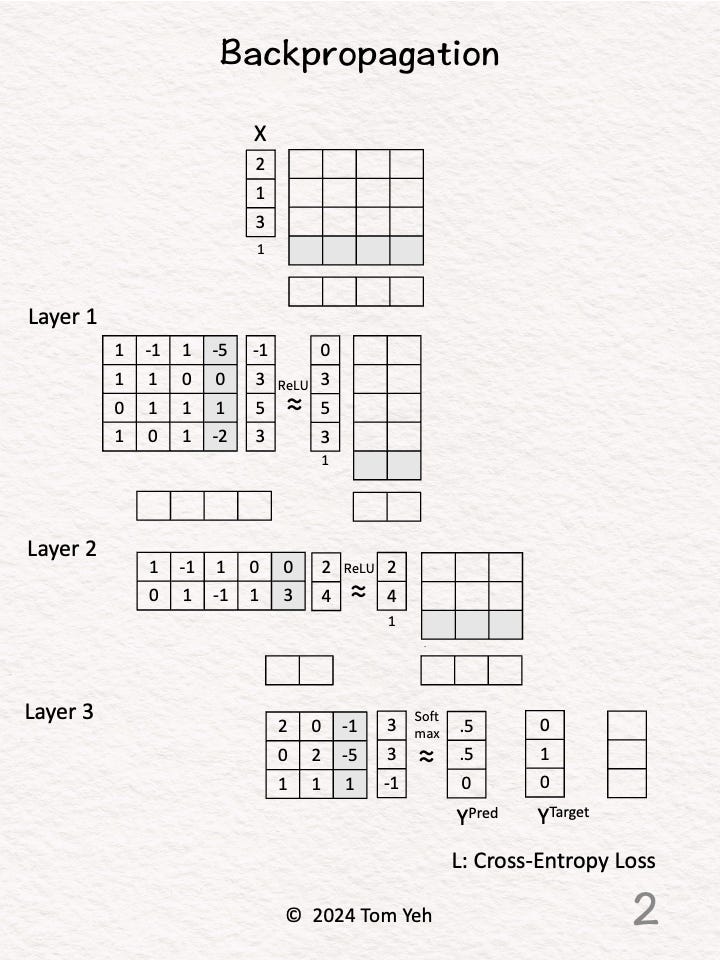
Insert cells to hold our calculations.
Step 3 of 11: Layer 3 Softmax
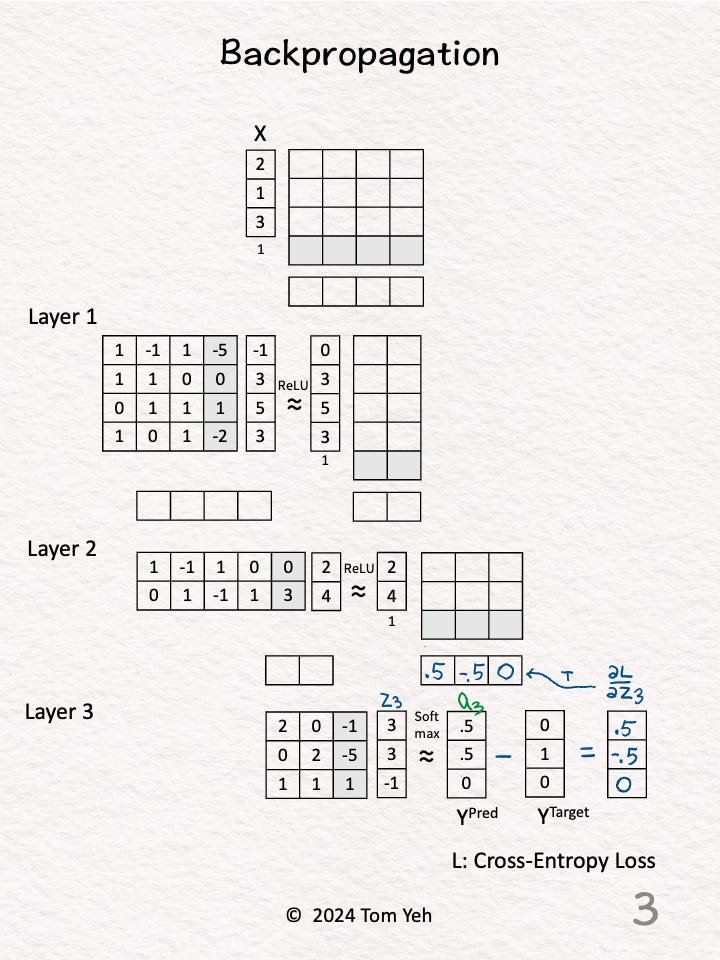
Calculate ∂L / ∂z3 directly using the simple equation: Y^{Pred} - Y^{Target} = [0.5, -0.5, 0].
This simple equation is the benefit of using Softmax and Cross Entropy Loss together.