
Batch Normalization by Hand ✍️
Calculating AI by Hand: 5 of 28

Library › Calculating AI by Hand ✍️
Batch Normalization by Hand ✍️
Reinforcement Learning with Human Feedback (RLHF) by Hand ✍️
Batch normalization is a common practice to improve training and achieve faster convergence. It sounds simple. But it is often misunderstood.
🤔 Does batch normalization involve trainable parameters? tunable hyper-parameters? or both?
🤔 Is batch normalization applied to inputs, features, weights, biases, or outputs?
🤔 How is batch normalization different from layer normalization?
This hands-on exercise can help shed some light on these questions.
Forward Pass
Step 1 of 7: Given
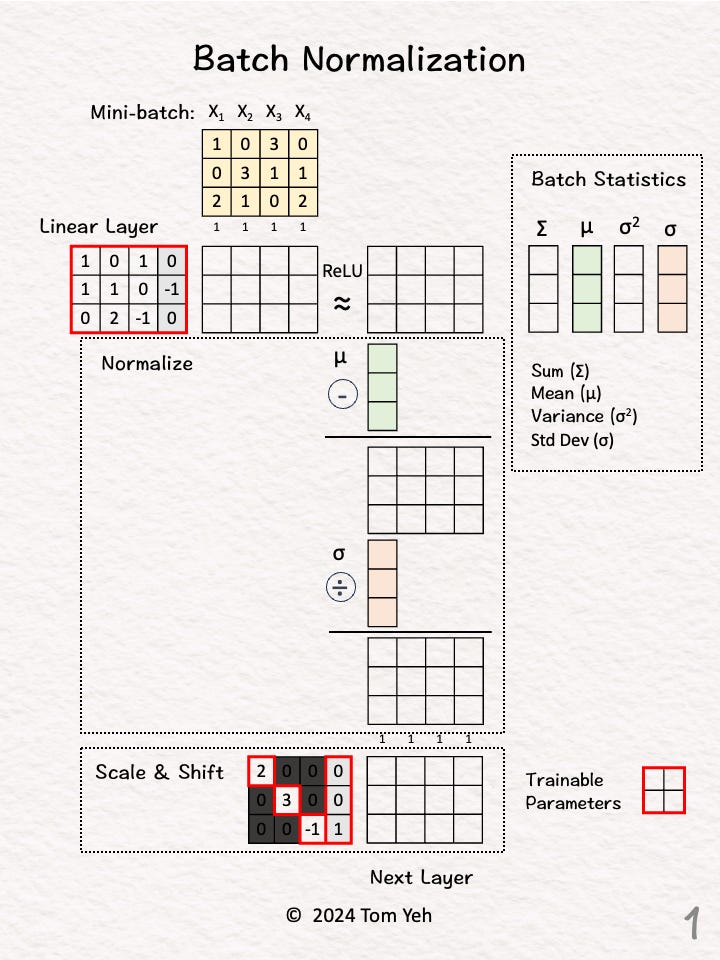
A mini-batch of 4 training examples, each has 3 features.
Step 2 of 7: Linear Layer
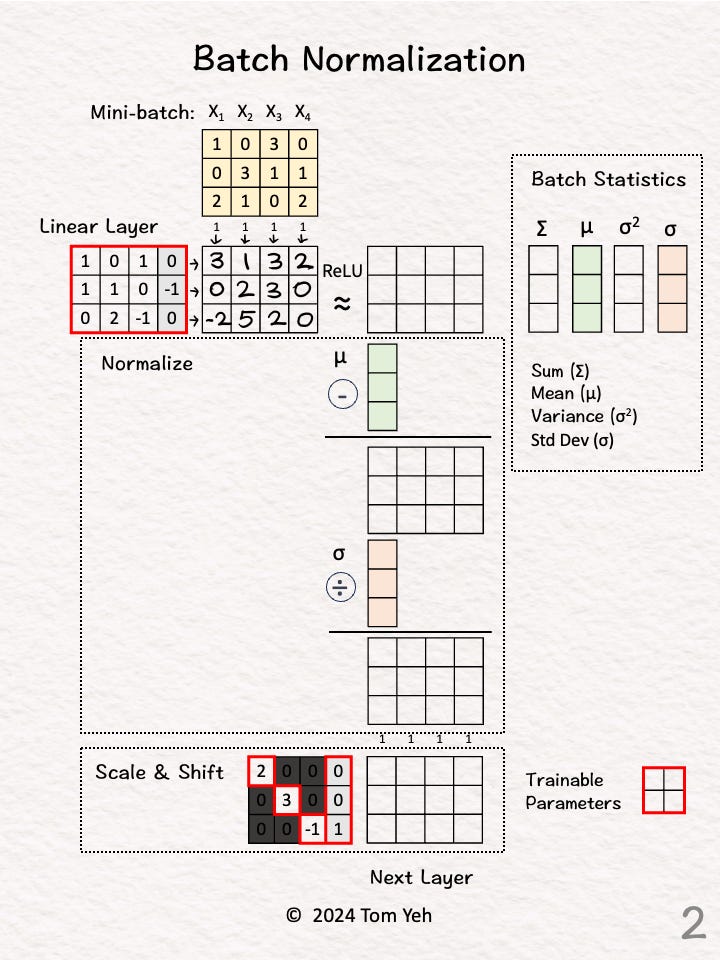
Multiply with the weights and biases to obtain new features
Step 3 of 7: ReLU
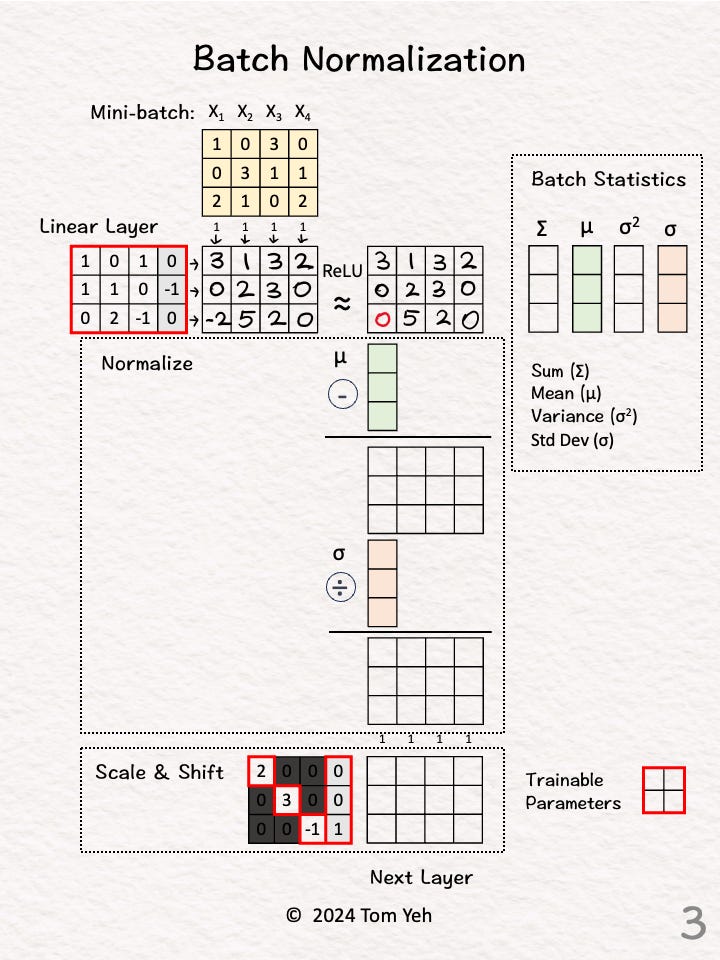
Apply the ReLU activation function, which has the effect of suppressing negative values. In this exercise, -2 is set to 0.