
New GPT-OSS Trick to Ignore Tokens
Frontier AI Drawings: 3 of 13

Library › Frontier AI Drawings
New GPT-OSS Trick to Ignore Tokens
Big news this week: OpenAI released its latest open-source model, GPT-OSS, along with a tech report, likely a prelude to the long-awaited GPT-5.
Instead of one early-access issue per week, here’s a bonus issue to respond quickly to what may become a reference point in future architectures.
Over the next few issues, I’ll prioritize architectures and techniques cited in the OpenAI tech reports.
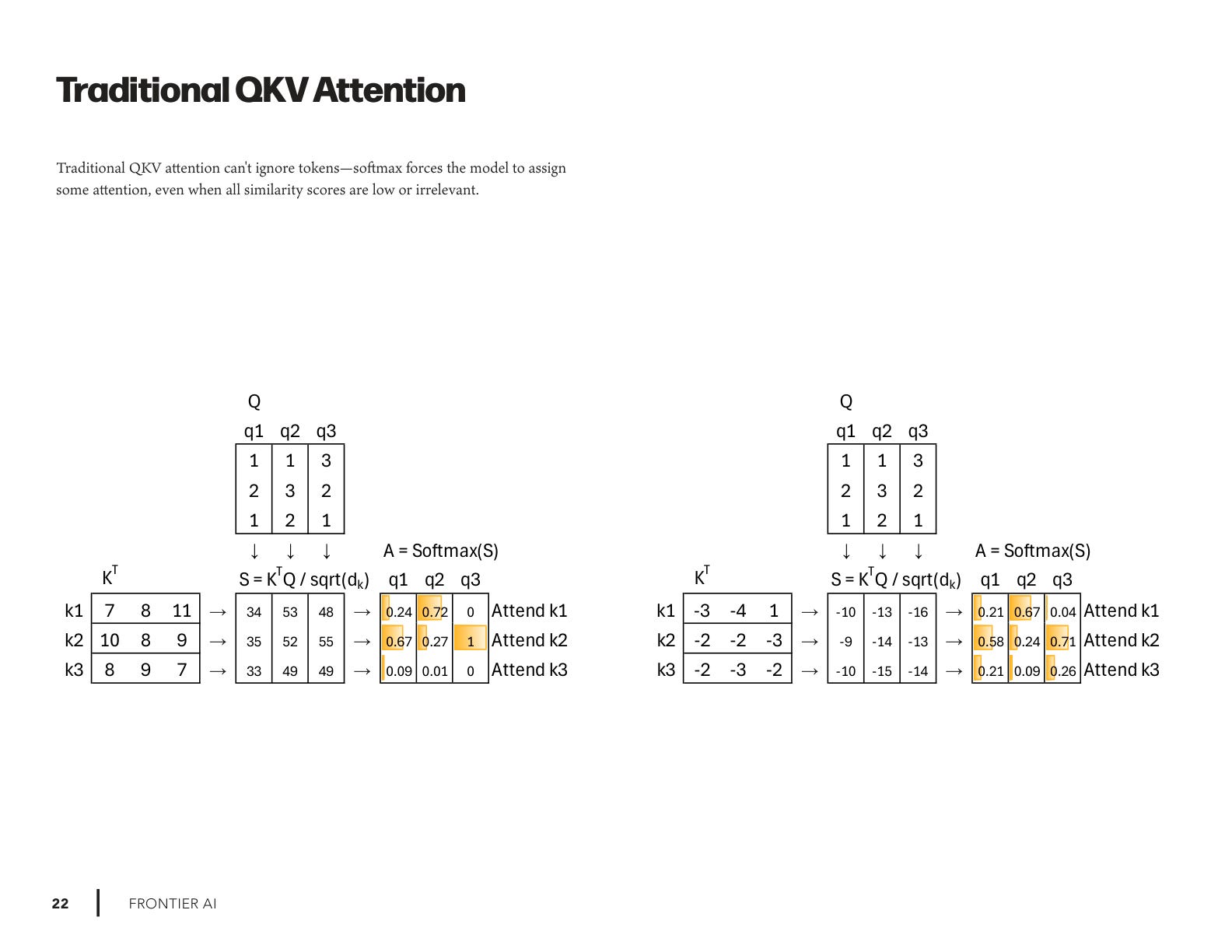
We’re starting with: how transformers can ignore tokens.
Drawings
I created four new drawings to explore different approaches to handling irrelevant tokens in attention:
Baseline Attention — the standard Softmax formulation, which always assigns some attention to every token.
Learned Bias in the Denominator — the new method used by OpenAI to allow true “ignoring.”
Off-by-One Softmax — adds a fixed bias to suppress weak matches.
Sink Tokens — introduces a special token to absorb low-similarity attention.

Each one solves the same limitation, each in a different way. You’ll learn how they work, why they matter, and what tradeoffs they introduce.
Page 1 of 4
Become a member to access the rest of the drawings.