
CLIP by Hand ✍️
Calculating AI by Hand: 21 of 28

Library › Calculating AI by Hand ✍️
CLIP by Hand ✍️
Reinforcement Learning with Human Feedback (RLHF) by Hand ✍️
The CLIP (Contrastive Language-Image Pre-training) model, a groundbreaking work by OpenAI, redefines the intersection of computer vision and natural language processing. It is the basis of all the multi-modal foundation models we see today.
How does CLIP work?
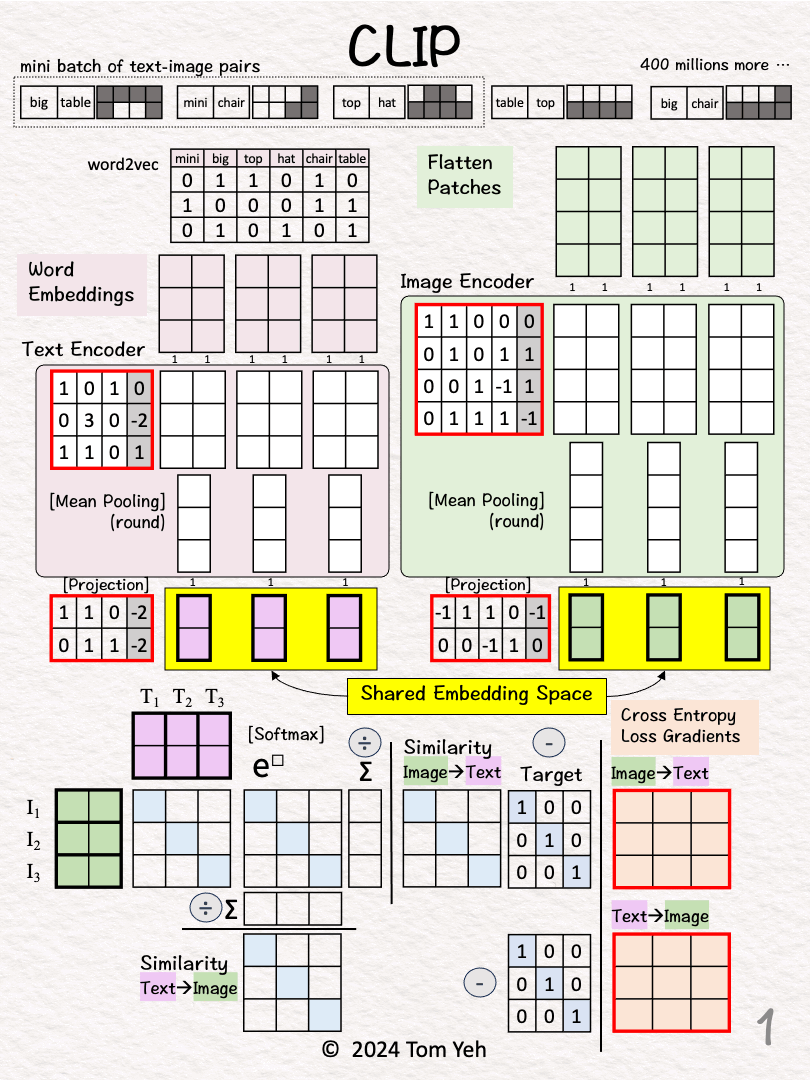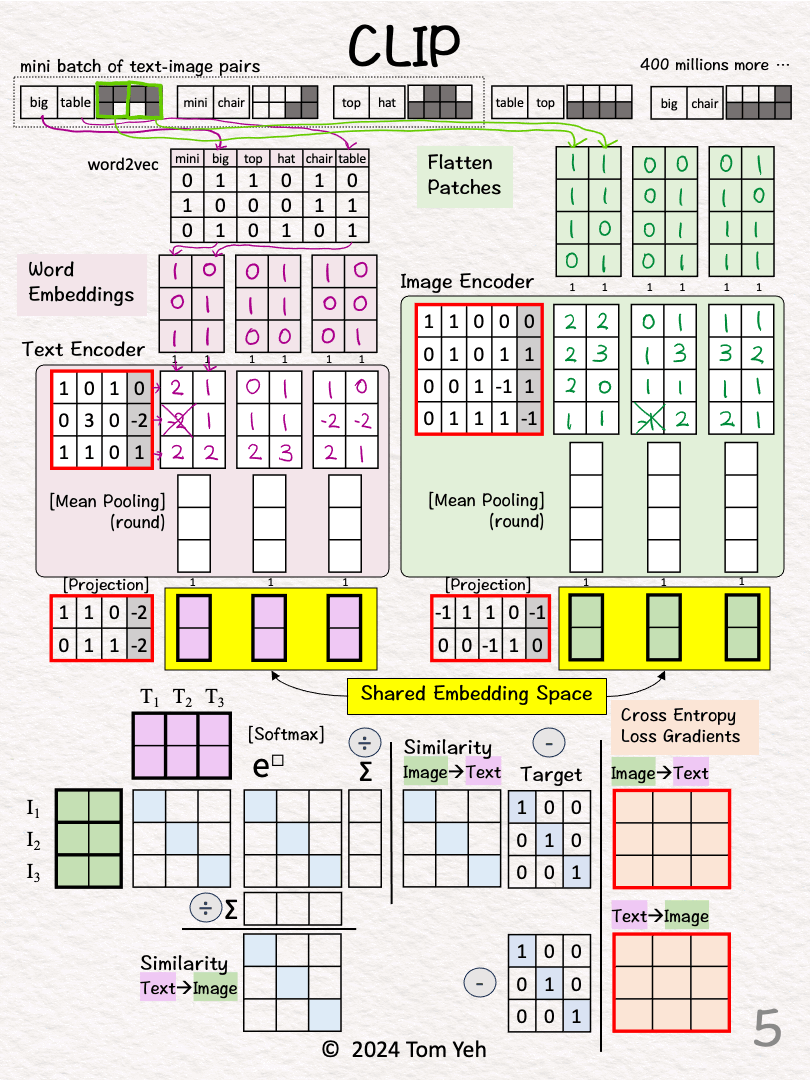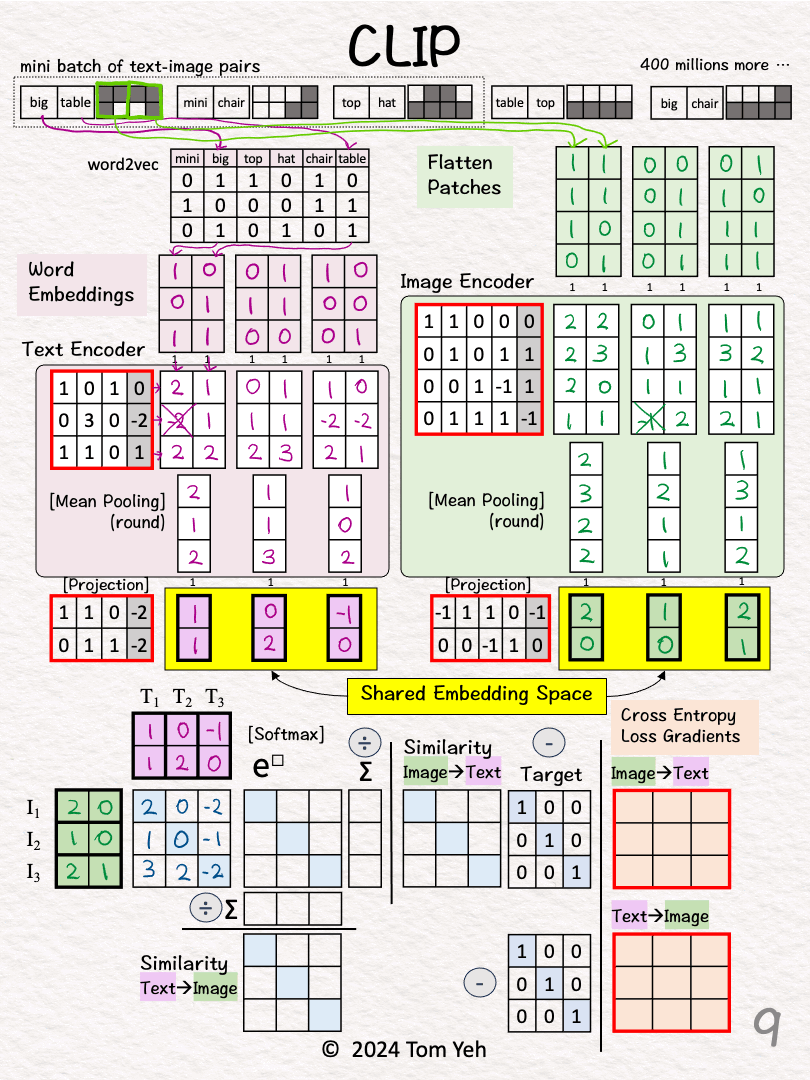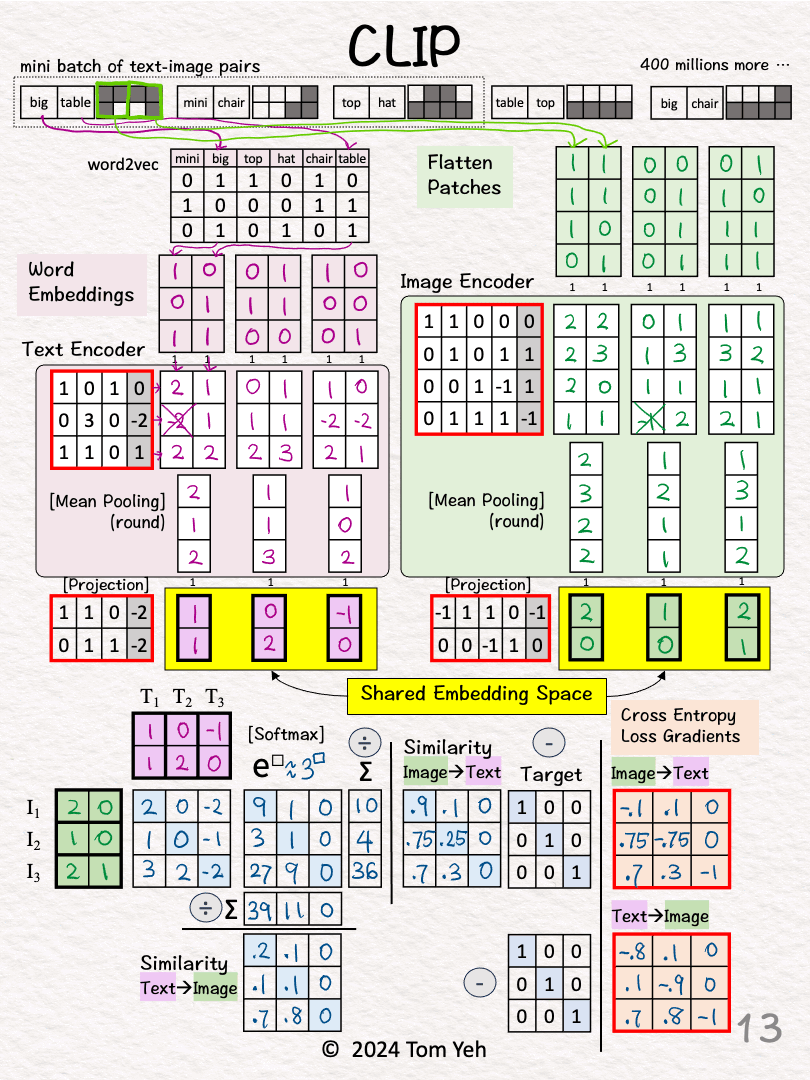
Goal: Learn a shared embedding space for text and image
Setup
Step 1 of 13: Given
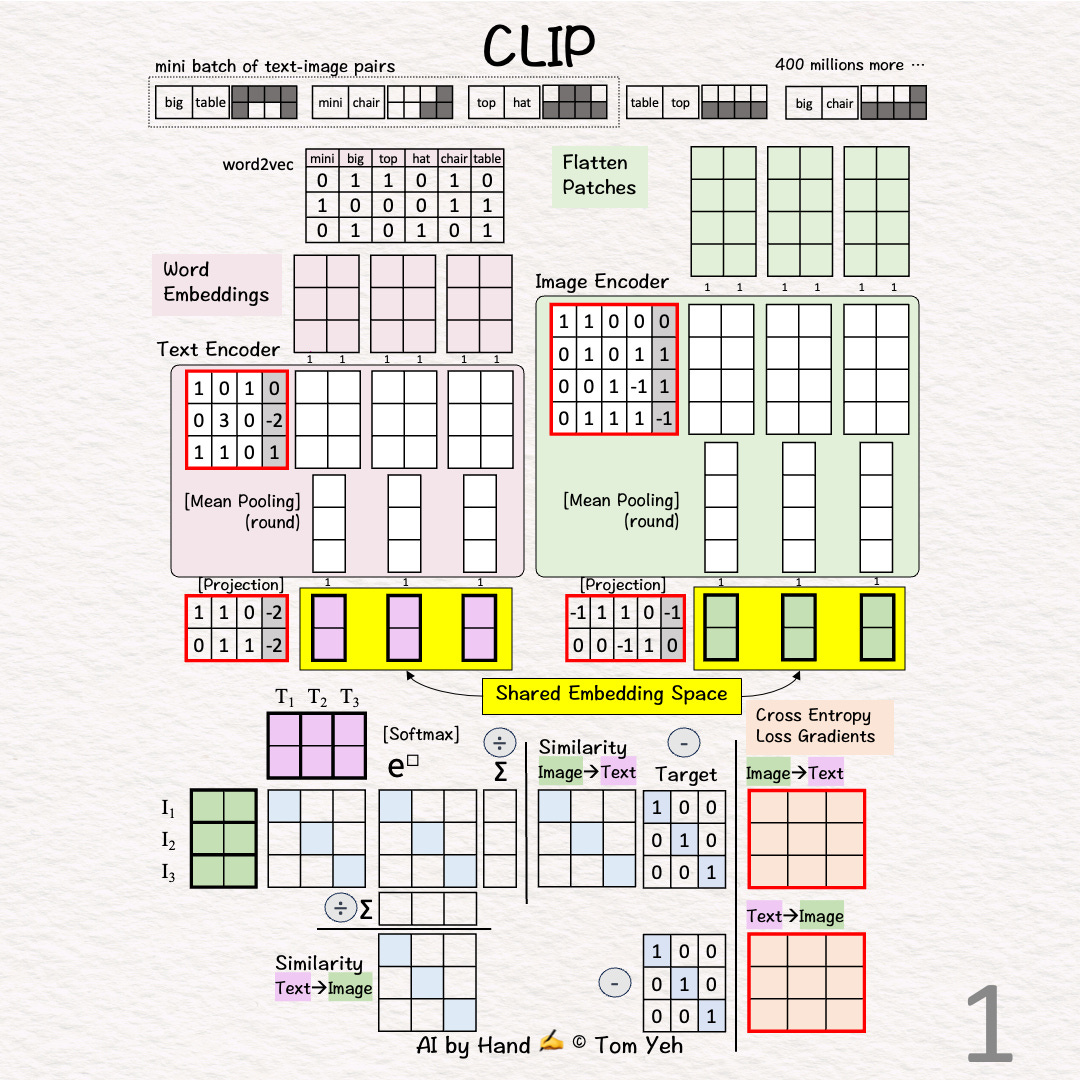
A mini batch of 3 text-image pairs
OpenAI used 400 million text-image pairs to train its original CLIP model.
Embeddings
Step 2 of 13: Text → Vectors
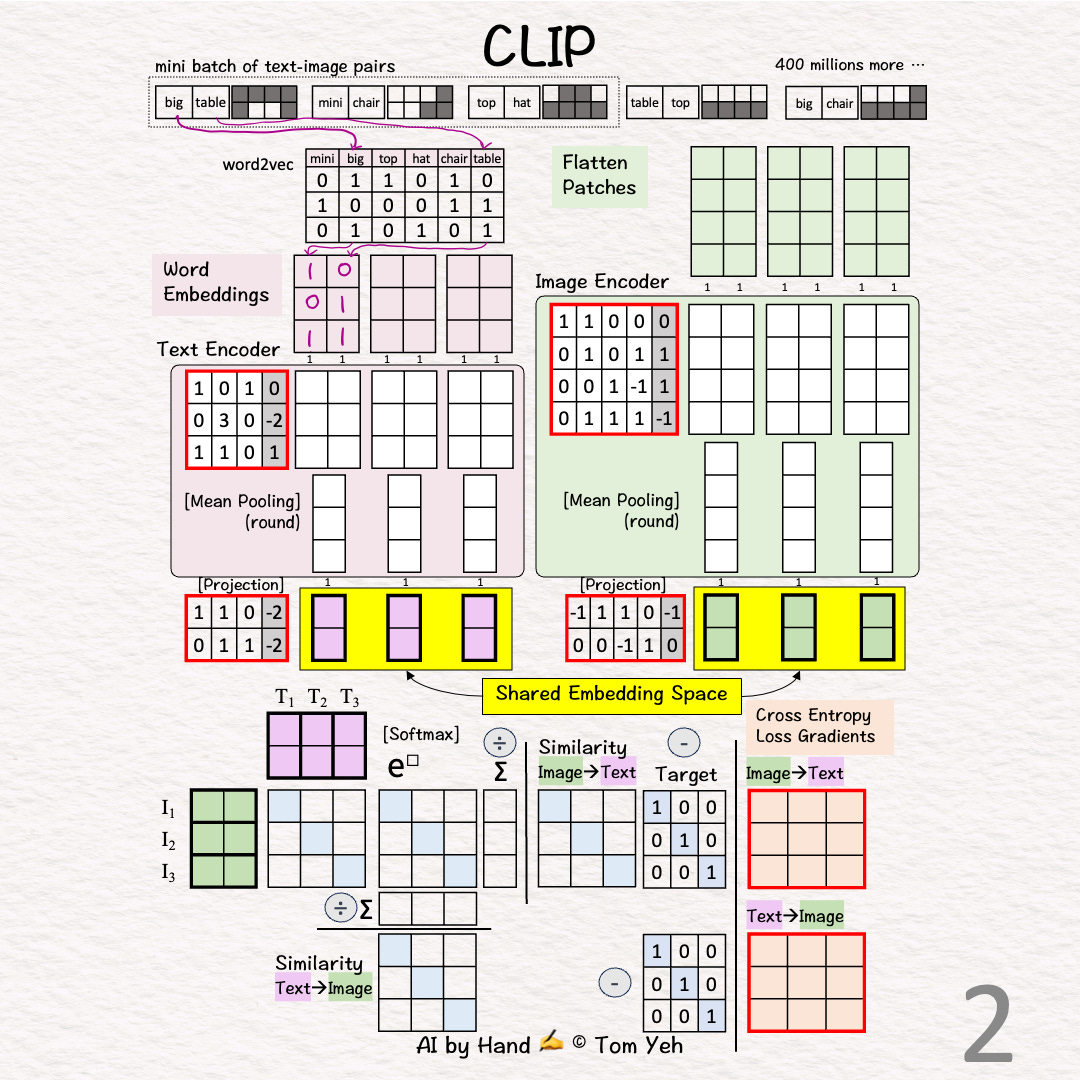
Look up word embedding vectors using word2vec.
Step 3 of 13: Image → Vectors
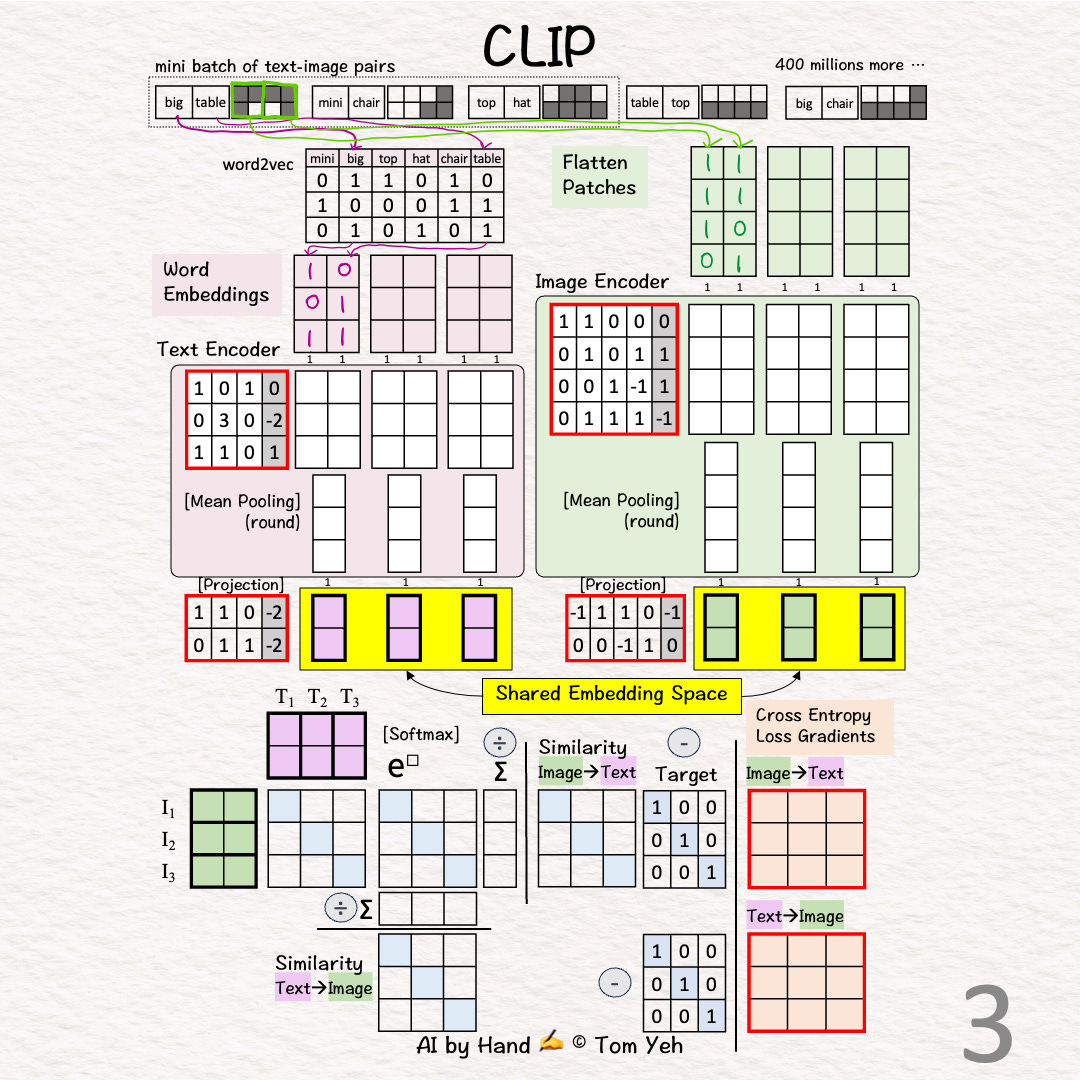
Divide the image into two patches.
Flatten each patch