
DeepSeek Attention (DSA)
Frontier AI Excel Blueprint

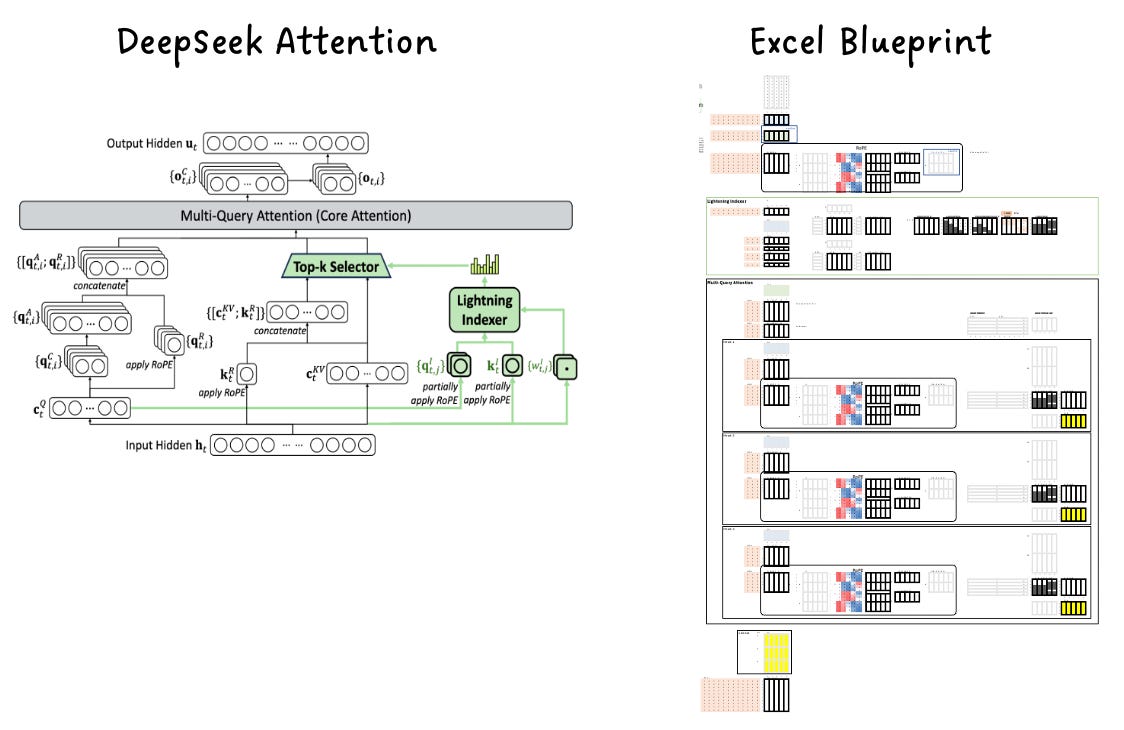
In this issue, I’m releasing the Excel Blueprint of the DeepSeek Attention layer, which I originally created while consulting for a company.
Why do I call it a blueprint? Because its purpose is to help an AI/ML team trace every algorithmic step, verify the math, and translate it into their own codebase using their preferred programming language.
While I can’t share the company’s implementation code, I can share my blueprint. The beauty of this blueprint is that it’s framework-agnostic — once you follow the operations, you can re-implement them in PyTorch, JAX, C++, or any language of your choice.
What is DeepSeek Attention?
A few weeks ago, DeepSeek released version 3.2, introducing a new mechanism called DeepSeek Attention (DSA), which adds a component known as the Lightning Indexer — a key innovation that improves attention efficiency and scalability.
Why?
DeepSeek’s core goal was simple: improve efficiency. That means two things—save time and save memory.
But time and memory often work against each other. For example, we cache keys and values (KV cache) to avoid recomputing them repeatedly. That saves time, but it costs memory. DeepSeek attacked this tradeoff on both sides: how to use less memory without increasing computation time, and how to reduce computation time without introducing accuracy loss.
Let’s walk through how.
KV Cache: Trading Space for Time
In the attention mechanism, every new query must be compared against all past keys and values. Without caching, we would need to recompute all past keys and values every time. That’s too slow.
So we cache them.
But as the context window grows—from 100K tokens to 200K—the KV cache also doubles. Even if the growth is linear, doubling KV memory usage becomes unsustainable at million-token scale.
So the question becomes: how do we shrink the KV cache without losing its time-saving benefit?
Reduce KV Cache Copies with Multi-Query Attention
In standard Multi-Head Attention, each head computes and stores its own set of keys and values. If there are 3 heads as in this example, we store 3 separate KV caches.
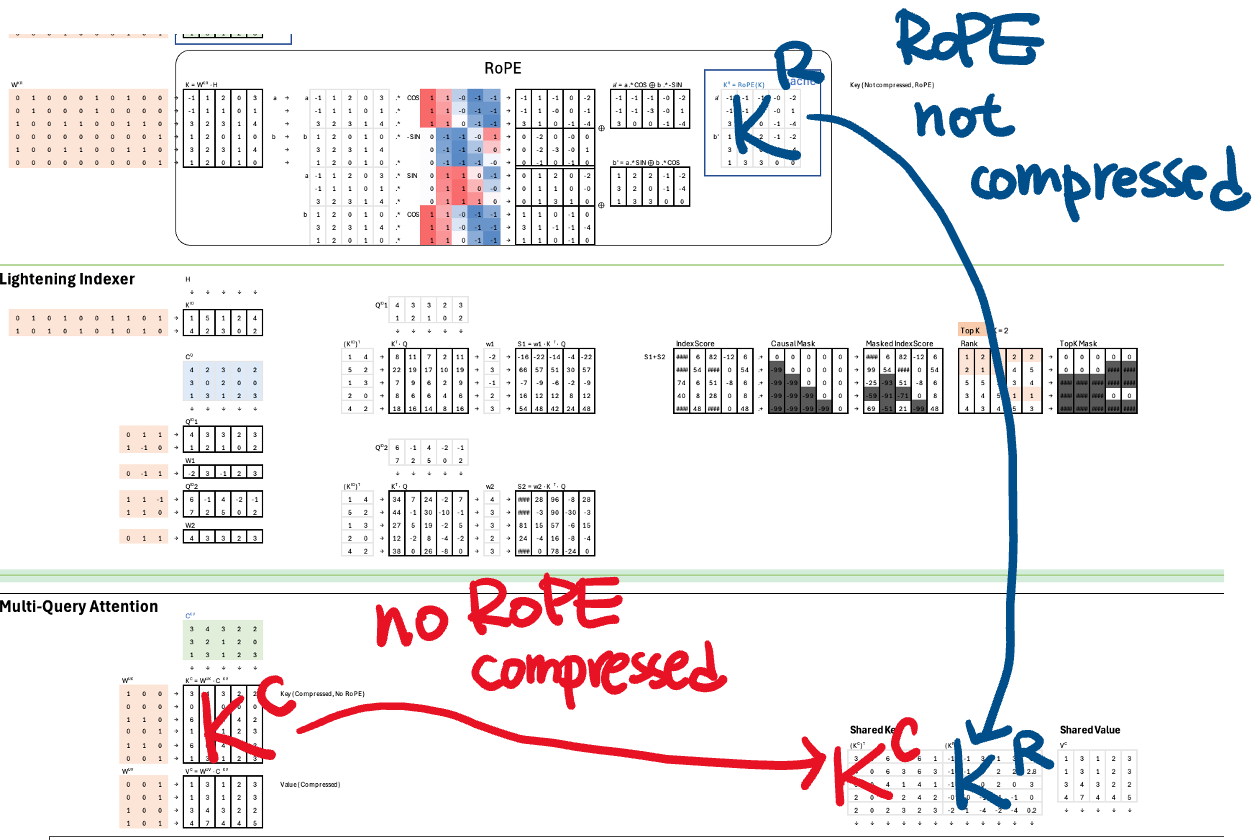
DeepSeek Attention switches to Multi-Query Attention (MQA). Here, all heads share the same keys and values, but queries remain head-specific.
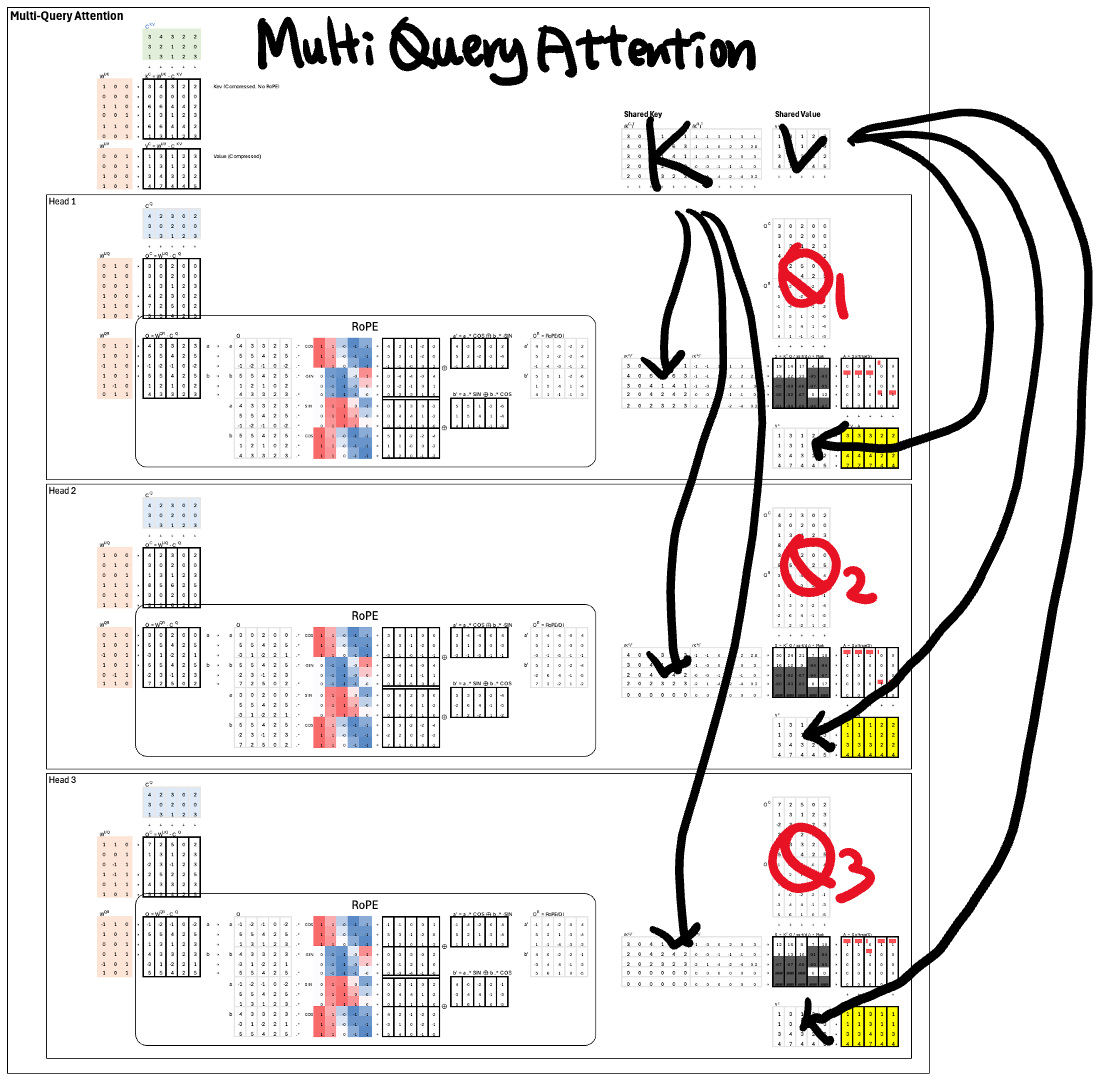
That immediately reduces KV storage from 3 copies to just 1.
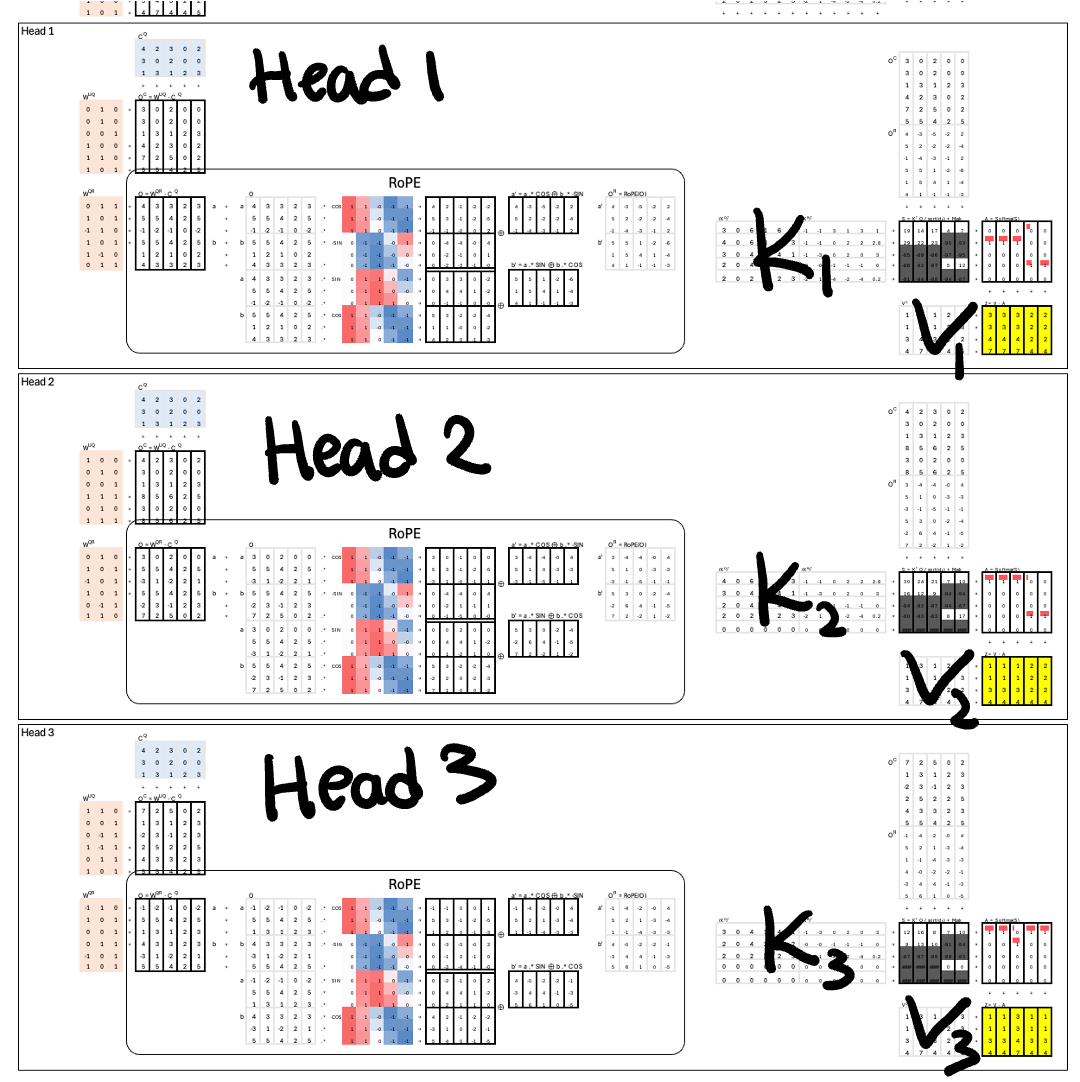
Compress KV Vectors
After reducing the number of KV sets from 3 to 1, the next target is reducing the size of each key and value vector.
Example:
Original key vector: 12 dimensions → split into two halves of 6.
Only one half is compressed.
Value vector (e.g., 4 dimensions) is fully compressed.
Total compressed input: 6 (from key) + 4 (from value) = 10 dims.
Projected into a lower-dimensional space (e.g., 3 dims) using a projection matrix.
This results in roughly 70% reduction in per-token KV storage.
Sparse Attention
Reduce Computation with Sparse Attention
Even with smaller KV vectors, full attention is still quadratic: an N×N matrix for N tokens. A 5×5 matrix looks small, but at 1M tokens it becomes 1M × 1M, which is intractable.
A common approach is to mask large parts of the matrix, reducing which key positions each query attends to. One simple masking strategy is to only look back at the last K tokens. That reduces memory (only K KV vectors are needed) and reduces compute (attention becomes O(NK) instead of O(N²)).
But this strategy is static: it ignores important tokens that may appear earlier, such as system prompts or core instructions at the beginning.
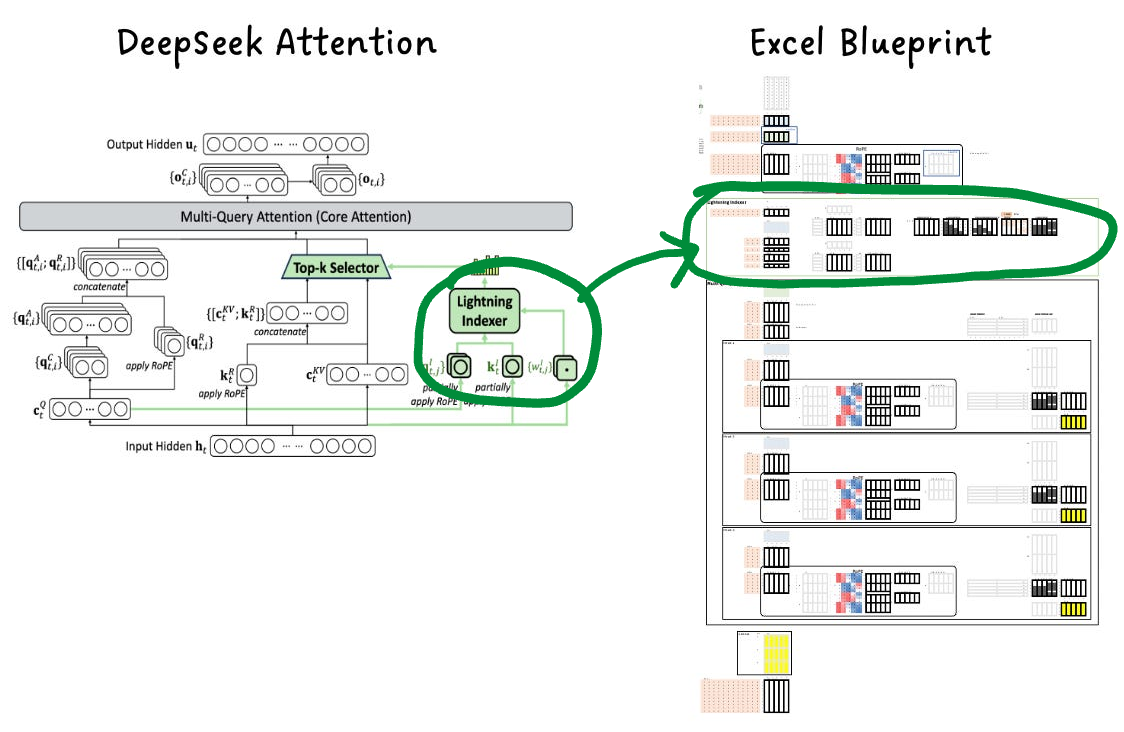
Use a Trainable Lightning Indexer for Dynamic Sparsity
DeepSeek Attention uses a lightweight module called a Lightning Indexer to dynamically select which past tokens are relevant.
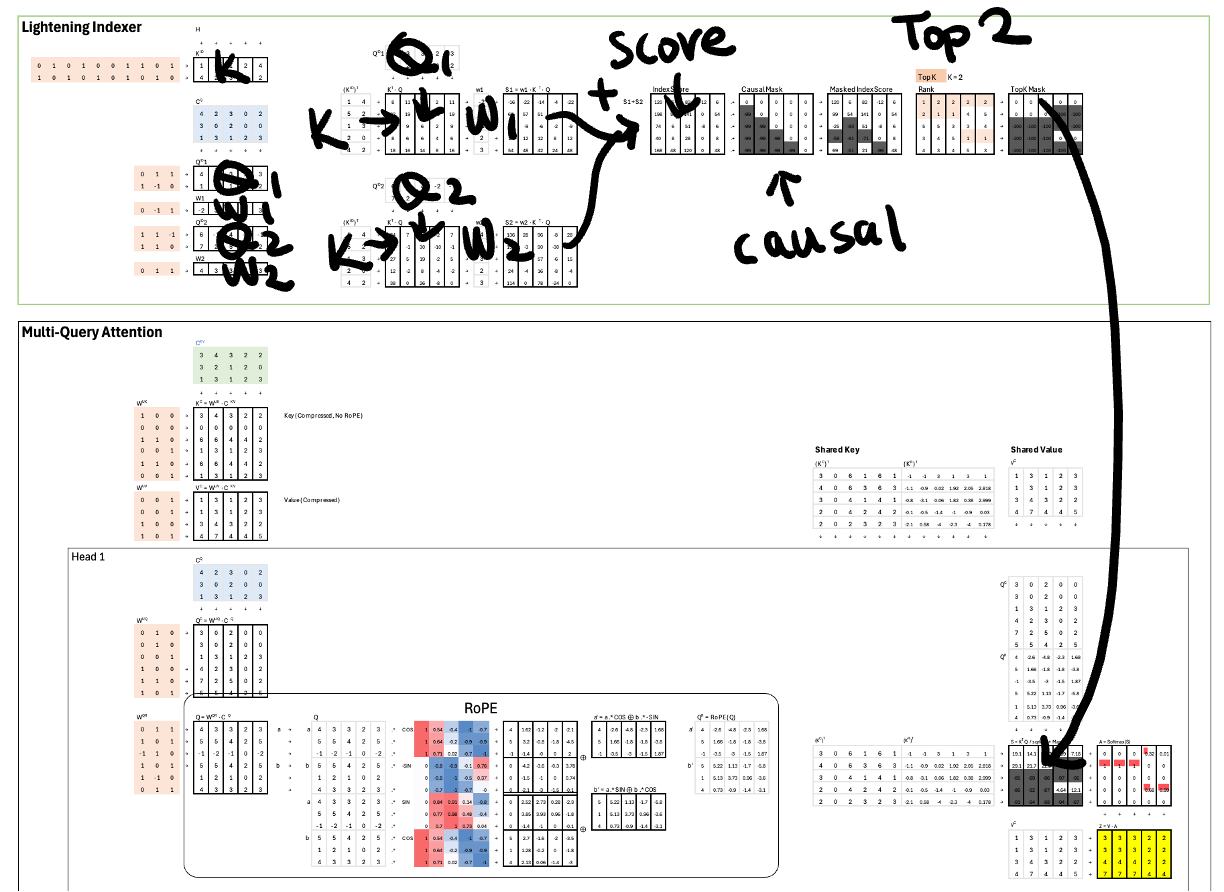
Here’s how it works:
It takes in a small, compressed version of the current query.
It quickly computes a relevance score for each past key.
It applies learned weighting.
It aggregates across heads.
It applies the causal mask.
It selects the Top-K entries.
The result is a learned mask that picks the most relevant K past tokens. These K positions are then used in the actual attention computation for all heads. Here K is 2.
Now, if the context window is 1M tokens and K is 1024, attention only compares against 1024 keys instead of 1M, keeping computation linear in K.
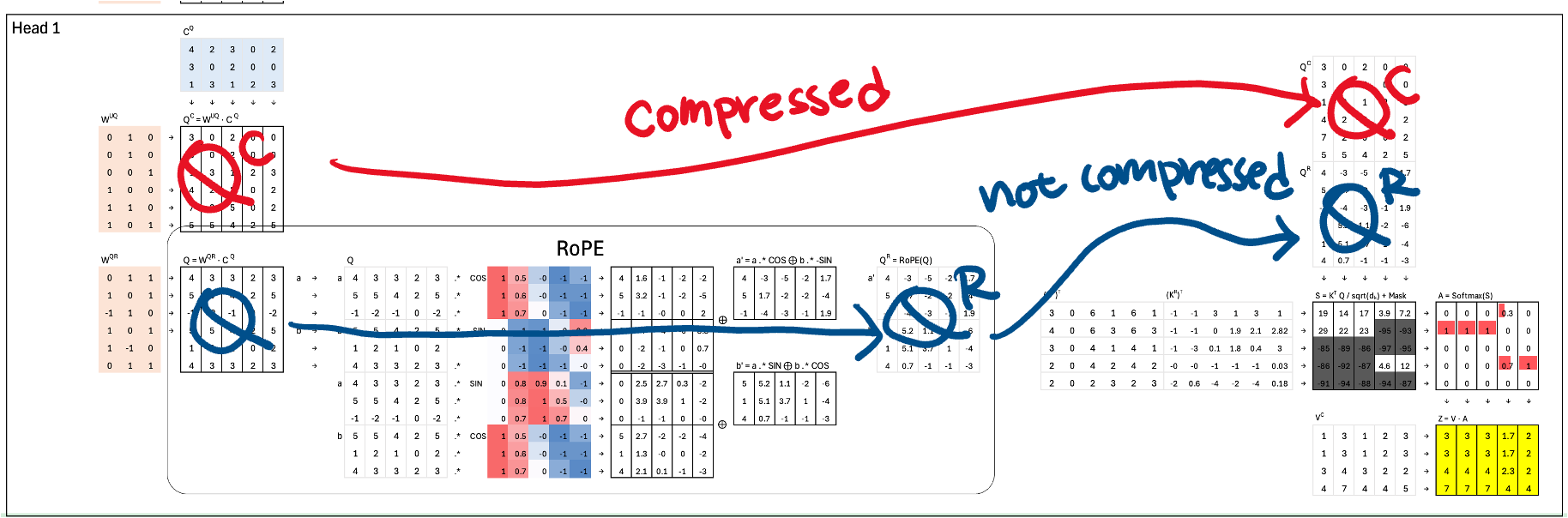
Why Split the Keys for RoPE?
DeepSeek splits the key into two halves: one half is compressed, the other remains unchanged. The reason is positional encoding. Rotary Positional Embedding (RoPE), which was covered in a previous issue, must be applied to the full, uncompressed vector. If we apply RoPE and then compress, the positional information may be lost or distorted.
The solution: apply RoPE to the uncompressed half and compress only the other half. This preserves positional structure while still saving space.
As I am writing to conclude this issue, thinking I was finally caught up with DeepSeek—then they dropped a new OCR model just to keep me humble.
Download
This Frontier AI Excel Blueprint is available to AI by Hand Academy members. You can become a member via a paid Substack subscription.