
EmbeddingGemma, MRL, InfoNCE, Embed vs. Decode
Frontier AI Drawings: 8 of 13

Library › Frontier AI Drawings
EmbeddingGemma, MRL, InfoNCE, Embed vs. Decode

In last week’s issue, I opened with Gemma 3 to motivate KV Cache. The same week, Google announced EmbeddingsGemma.
Coincidence? Perhaps. 😉
One key feature highlighted is customizable output dimension. This means you can pick the embedding size that best fits your application.
For example, you might choose smaller vectors to speed up product search in e-commerce or FAQ retrieval in customer support, and larger vectors to maximize accuracy in legal document ranking, scientific literature search, or medical record clustering.
How is this flexibility achieved? It is achieved through Matryoshka Representation Learning (MRL). Matryoshka is the Russian word for Russian dolls. In the same way that dolls nest inside each other, embeddings are learned in nested layers of different scales, so a large embedding contains progressively smaller ones inside.
Both Qwen3 Embedding (released back in June) and EmbeddingsGemma now come with baked-in MRL, which means this approach is no longer experimental. It’s becoming the mainstream frontier for Transformer embeddings.
Drawings
For this issue, I have created five new sets of drawings.
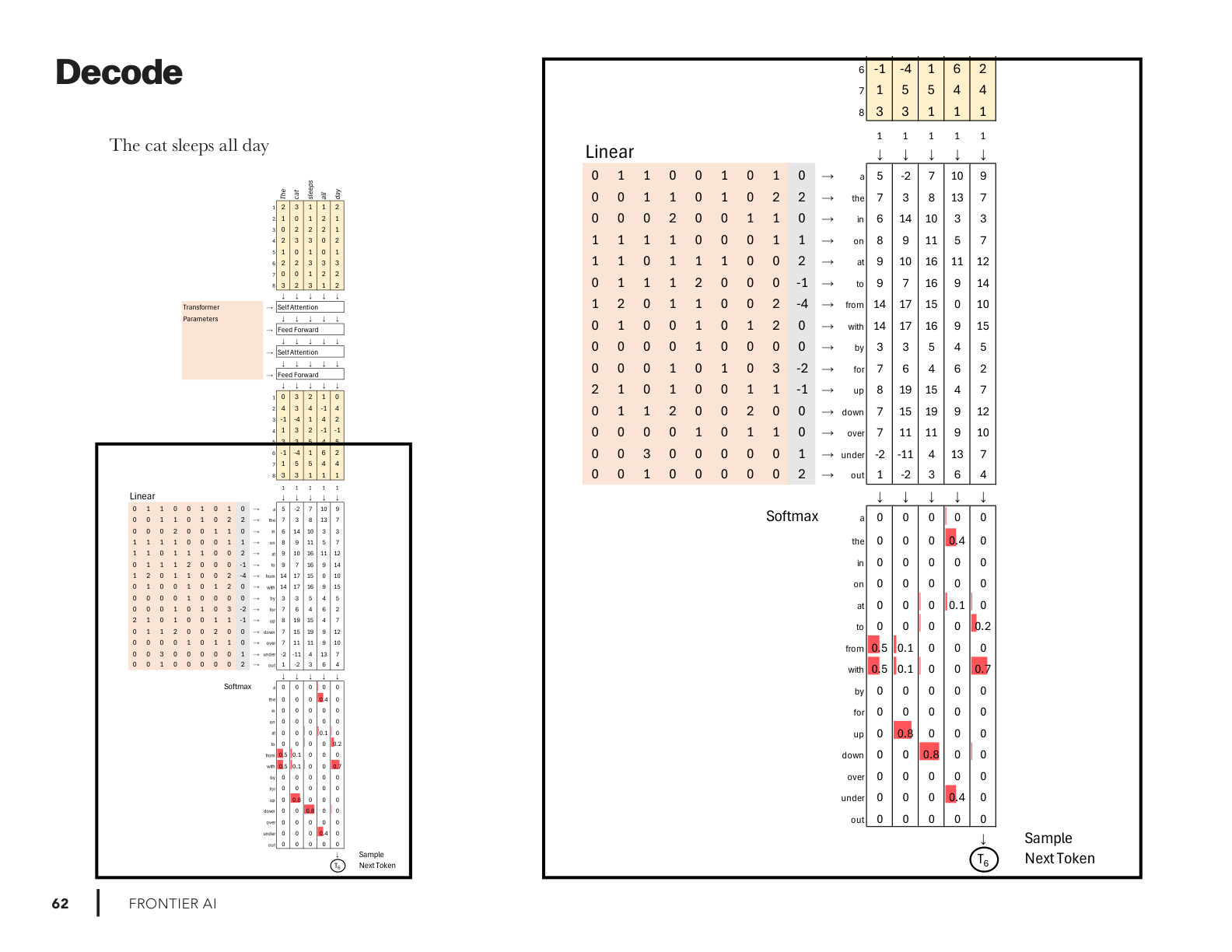
Decode
Embed
Information Noise Contrastive Estimation (InfoNCE)
Matryoshka Representation Learning (MRL)
Fine-tune Embedding Model by MRL
You can see contrasts between
Decode vs. Embed
InfoNCE vs. MRL
Finally, the last set of drawings brings everything together. You fine-tune an embedding model from pairs of text anchors and their respective positive examples, but this time you train with MRL so the model learns embeddings at multiple dimensions (i.e., 8, 4, 2) in one shot.

Page 1 of 8
Become a member to access the rest of the drawings.