
Expert Choice Mixture of Experts (MoE)
Frontier AI Drawings: 1 of 13

Library › Frontier AI Drawings
"Expert Choice" Mixture of Experts (MoE)
Mixture of Experts (MoE) is one of the most important architectural ideas in frontier AI today. Models like Mistral, DeepSeek, and Qwen all use it. The core idea: instead of running every parameter on every token, you route each token to a small subset of "experts" and activate only those.
Summary
Q: Why Expert Choice routing?
A: Because traditional MoE (Token Choice) suffers from load imbalance: some experts get overloaded with tokens while others stay idle, wasting capacity.
Q: How does Expert Choice fix this?
A: By letting experts select their top tokens, it prevents any expert from being overloaded and keeps computation balanced.
Q: Who invented Expert Choice routing?
A: Researchers at Google.
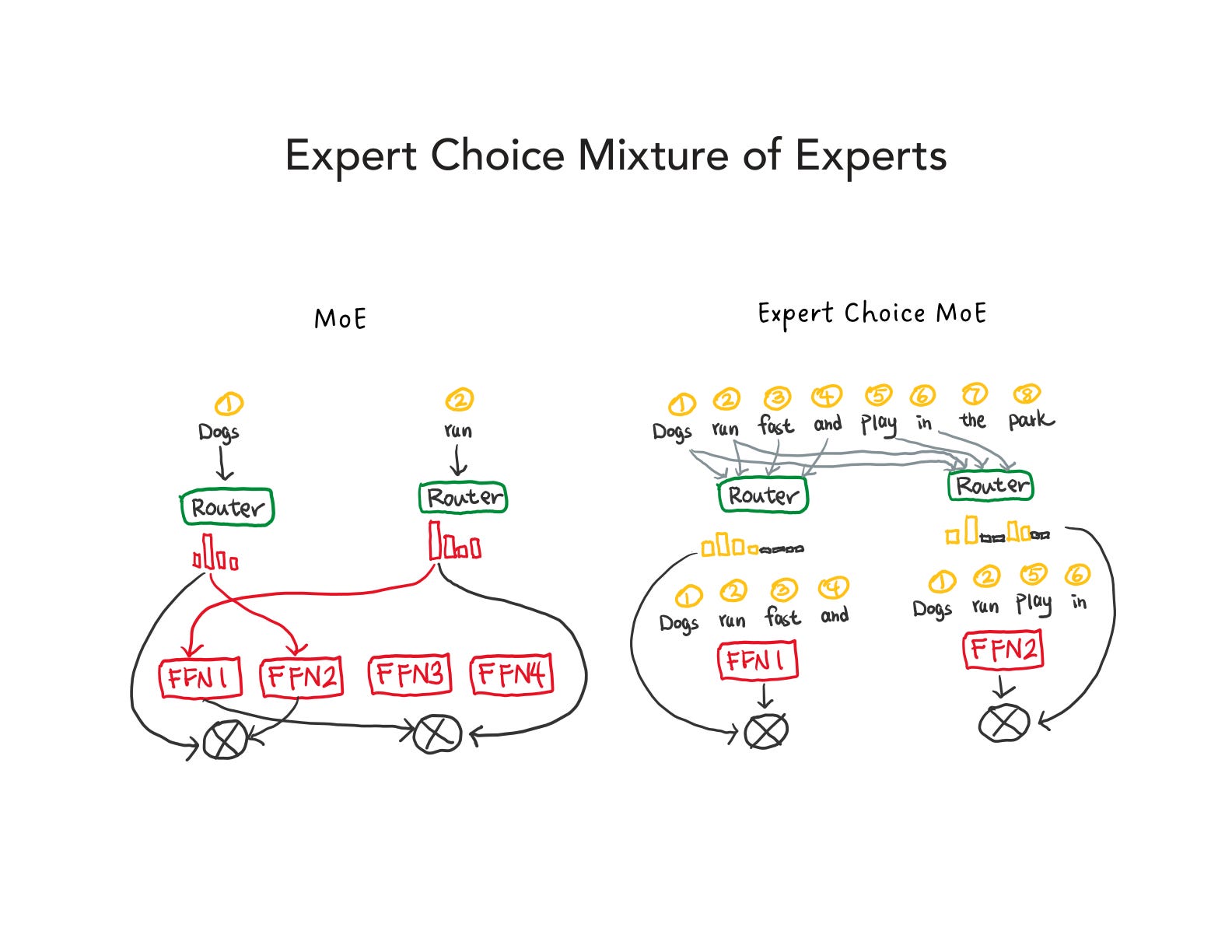
In Token Choice routing, each token picks its favorite expert. The problem is popularity: some experts attract too many tokens and get swamped, while others receive none and sit idle. Expert Choice flips the direction. Each expert selects its top K tokens. Because every expert selects the same number of tokens, load is perfectly balanced and no capacity is wasted.

Drawings

Token Choice vs Expert Choice (overview): side-by-side diagram showing how the routing direction differs between the two approaches.
Token Choice: full numerical example: 5 experts, 6 tokens. Walks through the expert embeddings, affinity scores, softmax, sorted gating matrix, and routing table step by step.
Expert Choice: per-expert FFN computation (part 1): Experts 1 and 2 each select their top 2 tokens and run them through W1, ReLU, W2, and gating.
Expert Choice: routing setup (5 experts, Top 2): token vectors, expert embeddings, affinity matrix A, sorted gating matrix, and sorted token index matrix.
Expert Choice: full computation and aggregation (5 experts, Top 2): all 5 experts compute in parallel, results are summed and combined into the final output tokens.
Expert Choice: routing setup (3 experts, Top 2): same walkthrough scaled down, useful for tracing the math by hand.
Expert Choice: full computation (3 experts, Top 2): per-expert FFN for all three experts, with final aggregation.
Expert Choice: routing setup (5 experts, Top 3): shows what changes when each expert selects more tokens.
Expert Choice: full computation (5 experts, Top 3): all five experts each pick three tokens, demonstrating how Top K controls capacity and compute.
Page 1 of 9
Become a member to access the rest of the drawings.