
Gated Attention ~ NeurIPS 2025 Best Paper (Dec 18, 2025)
AI by Hand ✍️ Seminars

Library › Seminar Series 2025
Gated Attention ~ NeurIPS 2025 Best Paper (Dec 18, 2025)
Recently, I delivered a Frontier AI Seminar diving deep into **Gated Attention**, winner of the NeurIPS 2025 Best Paper Award.
When a paper wins Best Paper at NeurIPS, where the world’s top AI researchers gather every year, it’s not optional reading. It’s a must-study paper. These are the works that set the research agenda, and skipping them is how you quietly fall behind.
Here’s the outline of this seminar
Introduction
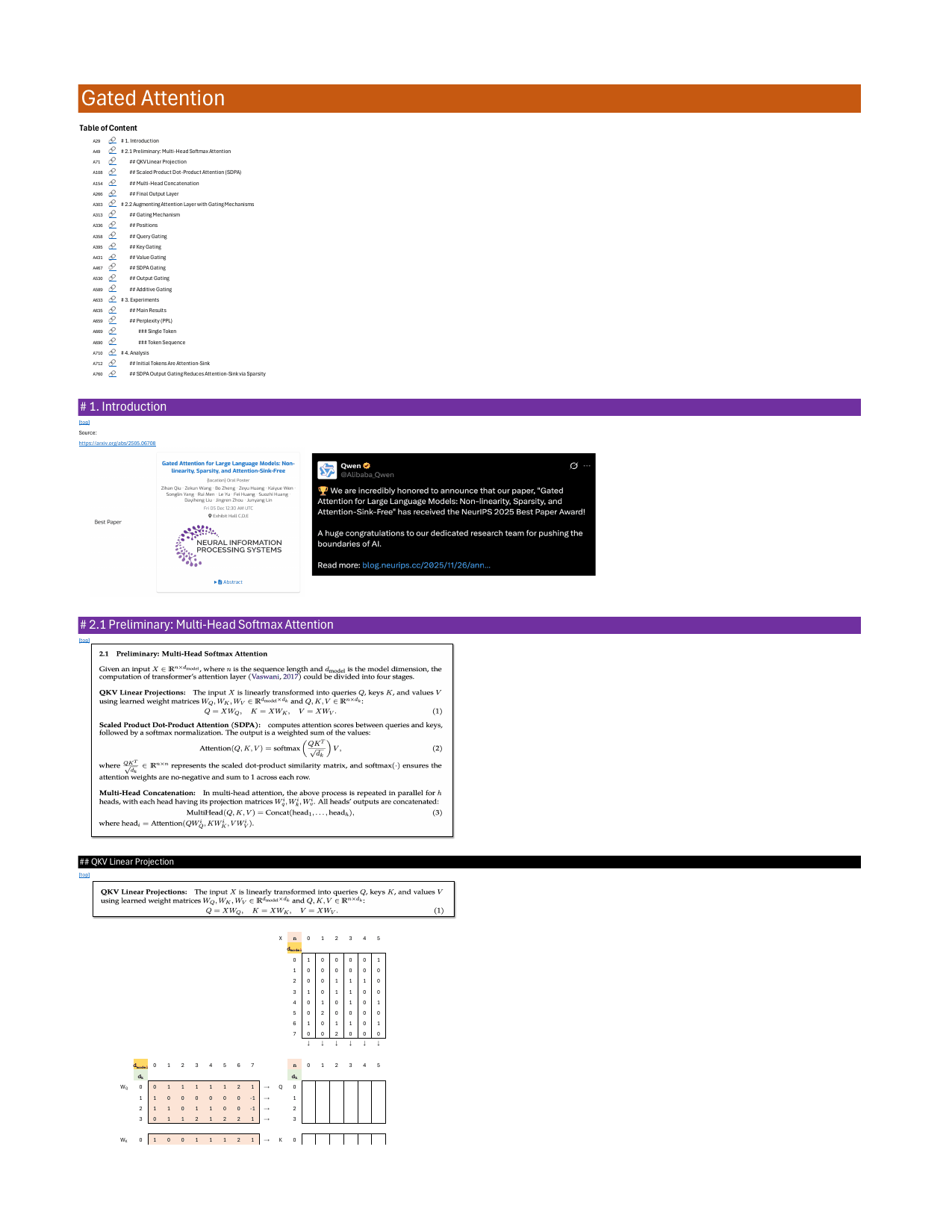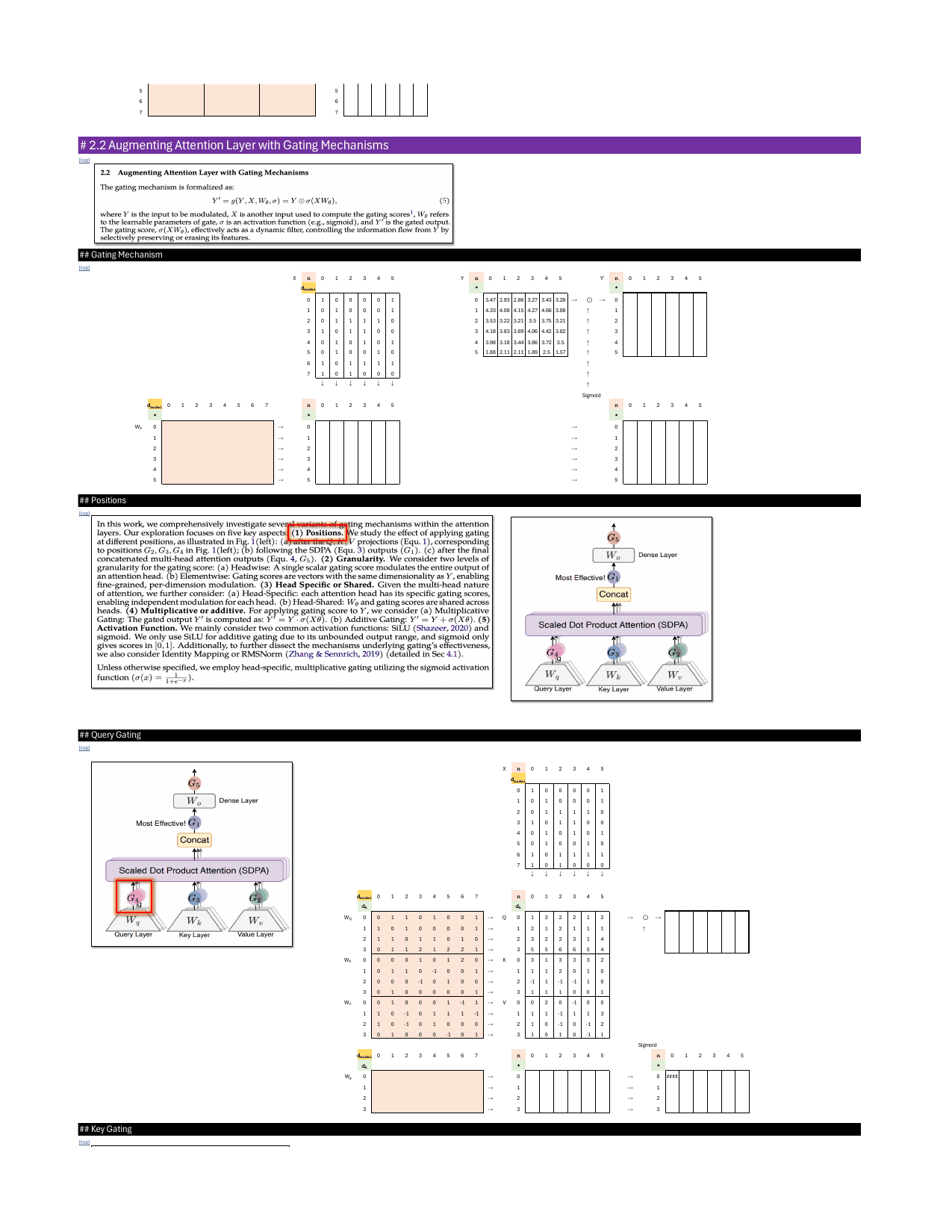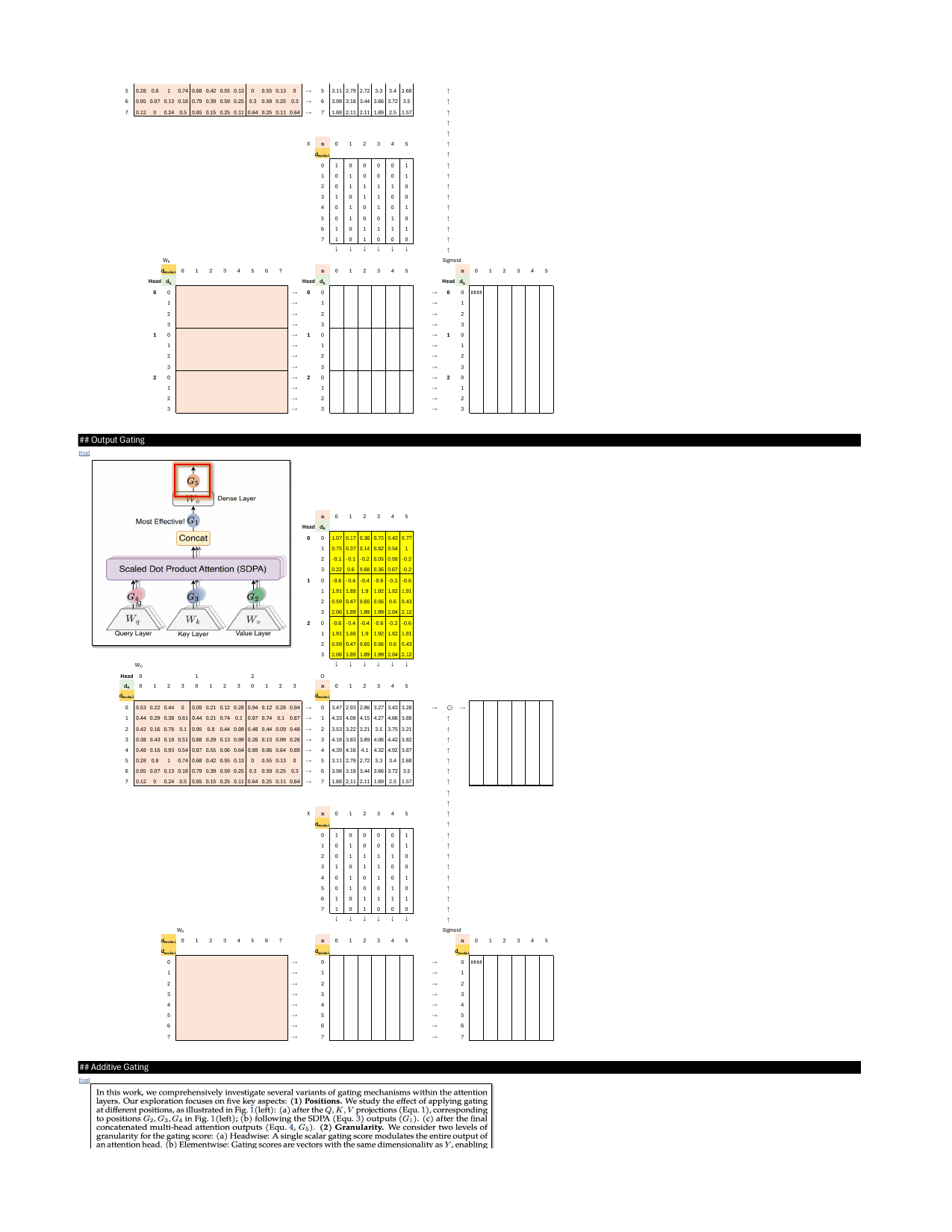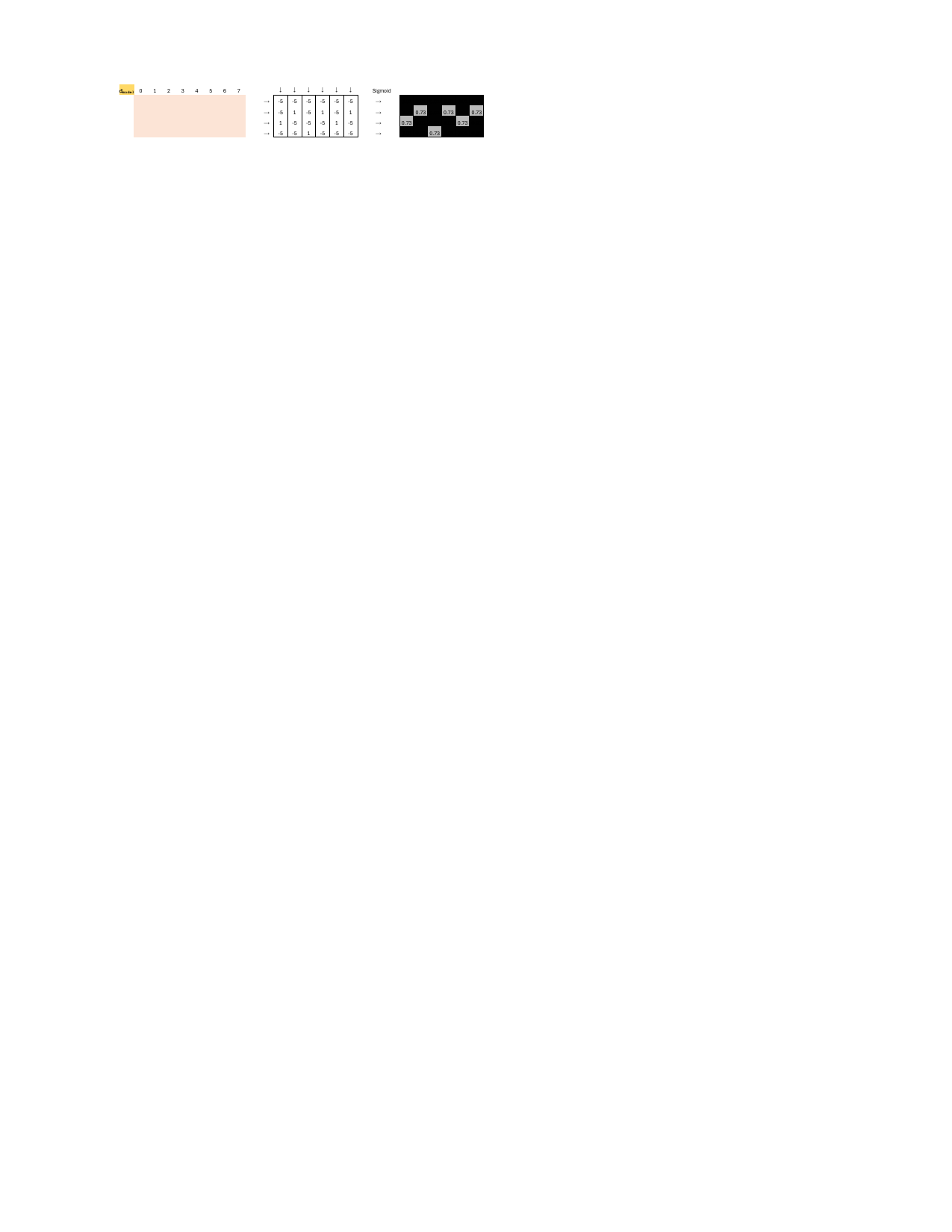
Preliminary: Multi-Head Softmax Attention
Augmenting Attention Layer with Gating Mechanisms
Experiments
Analysis
Recordings
Scaled Dot Product Attention
I used the opportunity to review foundation topics, such as the Scaled Dot Product Attention. In this video clip, I break down scaled dot-product attention from first principles, showing how queries (Q) are compared against keys (K) to produce attention scores. We then walk step by step through scaling, softmax, and value weighting, with careful attention to matrix shapes, transposes, and where each number actually comes from.
Perplexity (PPL)
Since Gated Attention evaluates performance using Perplexity (PPL), I finally got to demystify this perplexing metric, pun intended. In this video clip, I framed perplexity as a measure of how many choices a model believes it has at each step. We walk through how softmax turns scores into probabilities, why a perfect perplexity of 1 means zero uncertainty, and how different choice distributions directly affect PPL and model performance.
Gated Attention
Recording & Workbook
Become a paid subscriber to access the full recording and the associated Excel workbook.