
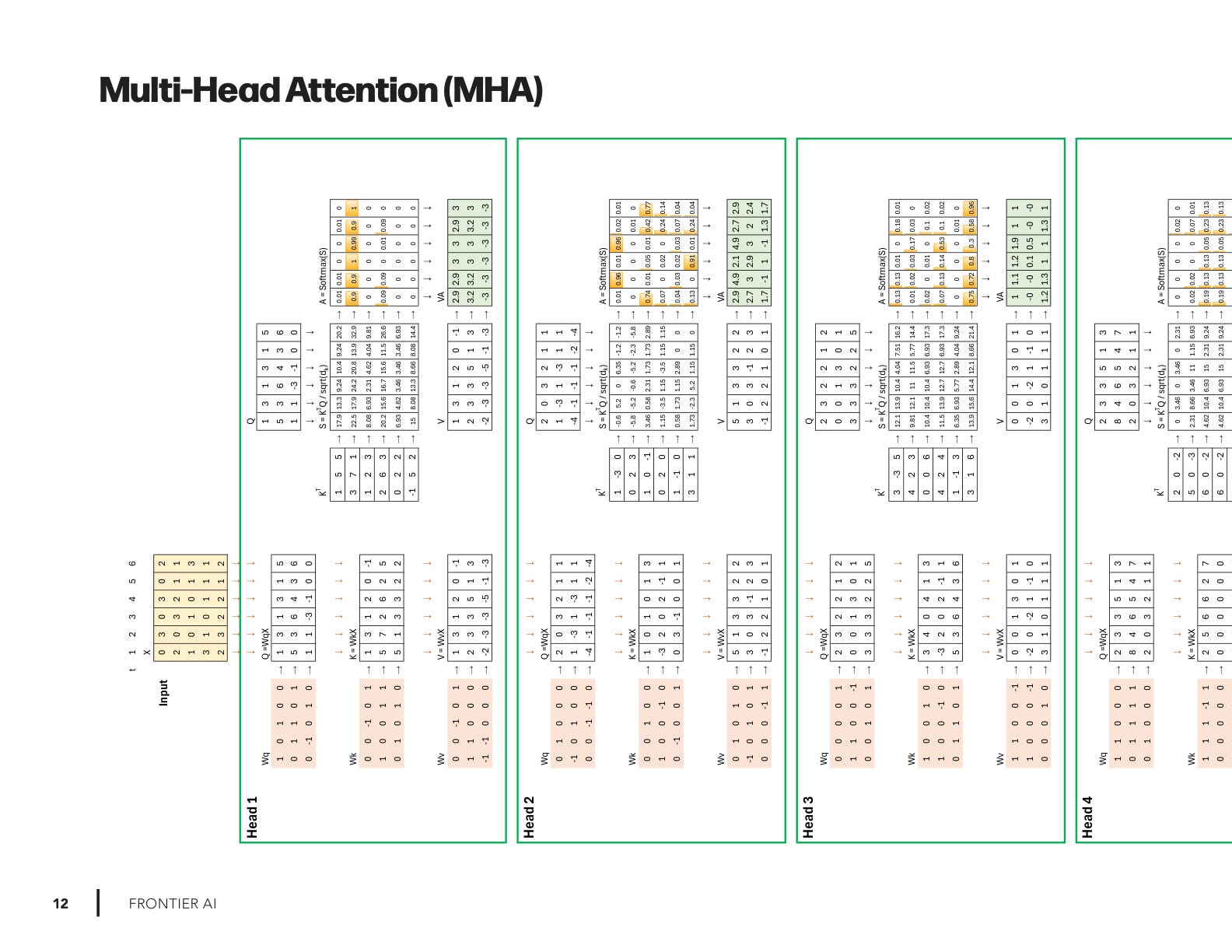
MHA, MQA, GQA, MoE-A: More Attention!
Frontier AI Drawings: 2 of 13

Library › Frontier AI Drawings
MHA, MQA, GQA, MoE-A: More Attention!
More attention for better attention.
This week we zoom out to the bigger picture: how attention itself has evolved.
GQA showing up in GPT-OSS is yet another sign of its wide adoption, mirroring trends we’ve seen in PaLM, LLaMA, and other large-scale models. These are no longer niche optimizations; they’re becoming standard in high-performance architectures.
Drawings
I’ve created four new drawings breaking down the math behind:
Multi-Head Attention (MHA) – the original transformer workhorse.
Multi-Query Attention (MQA) – shares keys and values across heads for speed.
Grouped-Query Attention (GQA) – the middle ground between MHA and MQA, used in GPT-OSS and increasingly in other frontier models.
Mixture-of-Experts Attention (MoE-A) – routes attention to specialized experts for scalability.

Page 1 of 8
Become a member to access the rest of the drawings.