
How Small Models Learn Tool Use (Jan 11, 2026)
AI by Hand ✍️ Seminars

Library › Seminar Series 2026
Manifold-Constrained Hyper Connections (mHC) from DeepSeek (Jan 9, 2026)
How Small Models Learn Tool Use (Jan 11, 2026)
Meta Superintelligence Labs vs Facebook AI Research (Jan 30, 2026)
It was a real pleasure to see hundreds of people join this Frontier seminar from around the world. Thank you to all the paid subscribers who came back, and to the many guests who joined for the first time. I really appreciate you being in my classroom.
Industry Insights
I was joined by a special guest, Xu Han from Amazon, my former PhD student, who now trains language models for one of Amazon’s key AI-powered products used by the hundreds of millions (you can probably guess which product).
During the seminar, I took a moment to ask Xu a question: “What are the biggest challenges in training production models at Amazon for a product used by a ton of customers?” The last time I questioned her like this was at her dissertation defense many years ago. 😉😊
Drawing directly from her experience training production models, Xu outlined three recurring challenges she encounters when building language models in industry:
Data quality dominates everything
> Model performance is rarely limited by architecture, it’s limited by data. More data is not necessarily better. Noisy labels, inconsistent annotations, distribution mismatches, and overconfident synthetic responses can overwhelm the learning signal. Poor-quality data can push models toward unsafe behaviors, such as giving long, confident answers when ambiguity or clarification would be more appropriate.
Benchmark metrics don’t match user experience
> Offline metrics like loss, accuracy, or preference scores often fail to reflect what users actually care about. Models can improve on paper while becoming less helpful, less trustworthy, or less aligned in practice. This creates a persistent gap between academic-style evaluation and real-world usefulness, requiring more behavior-driven evaluation frameworks.
Debugging failures is fundamentally hard
> Language models rarely fail in obvious ways. Issues surface subtly, through hallucinations, overconfidence, or inconsistent reasoning, and the root cause can lie anywhere: data pipelines, prompts, training stages, evaluation design, or interactions across components. Debugging therefore requires careful, hypothesis-driven analysis across the entire system, not just the model itself.
As an educator, it’s rewarding when a student becomes your teacher. That was absolutely the case when Xu came back to share her real-world experience she’s gained working on the core AI team at Amazon. I couldn’t be more proud.
Small Language Model & Agentic Tool Calling

One of the clearest engineering trends in agentic AI today is the growing use of small language models (SLMs) inside agent loops.
This is not because SLMs outperform large models across the board. Rather, many agent workloads place real constraints on latency, cost, deployment footprint, and controllability, constraints under which smaller models are often a practical choice, especially when the core task is tool invocation rather than long-form generation.
Last December right before many of us slowed down to enjoy the holidays with families, Amazon Web Services released a study examining how SLMs perform on tool-calling tasks.
What makes this study a big deal is not the headline numbers, but the fact that a major technology company chose to publicly document, in detail, how a small language model can be trained, stabilized, and evaluated for tool use in a production-oriented setting.
Outline
OPT-350M: What is OPT-350M, the small language model used by AWS?
DeepSeek OCR
Facebook OPT
SFT: What is ToolBench-style Supervised Fine Tuning?
ToolBench: How is ToolBench data turned into training examples?
Scenario to Token Sequence
Token Embeddings
Decoding
Loss: What loss is optimized during tool-use training?#
Stability: Why does this setup remain stable in a single epoch?
Single Epoch
Warmup
Selected Highlights
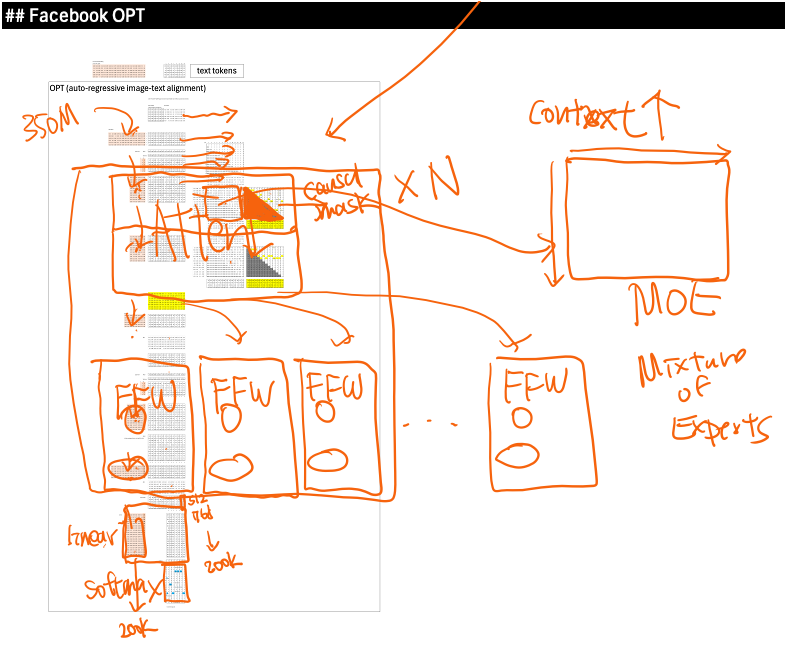
The paper uses OPT-350M, an open GPT-style reference model from Meta, to show how big tech might approach this problem in practice. We briefly revisited the OPT architecture, standard causal attention, feed-forward layers, and softmax decoding, and used it to explain why modern models became large in the first place: deeper stacks, Mixture-of-Experts, and huge vocabularies, not longer context windows.
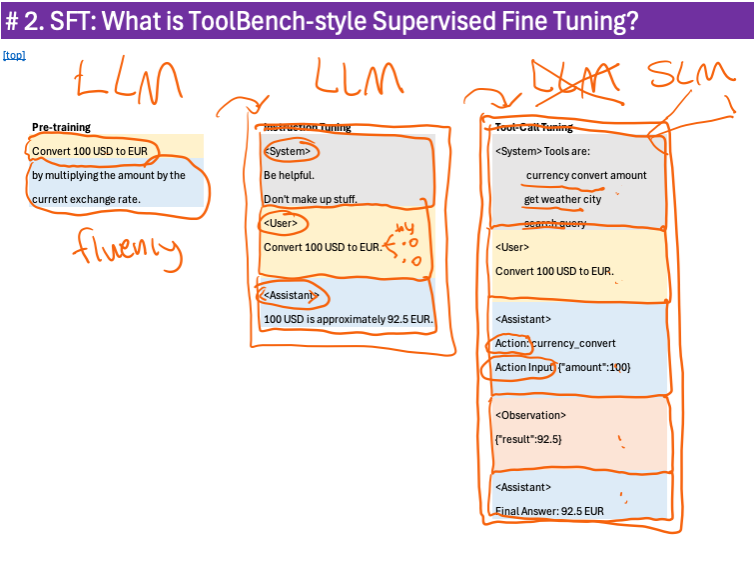
I walked through the training progression from pre-training, to instruction tuning, to tool-calling fine-tuning.
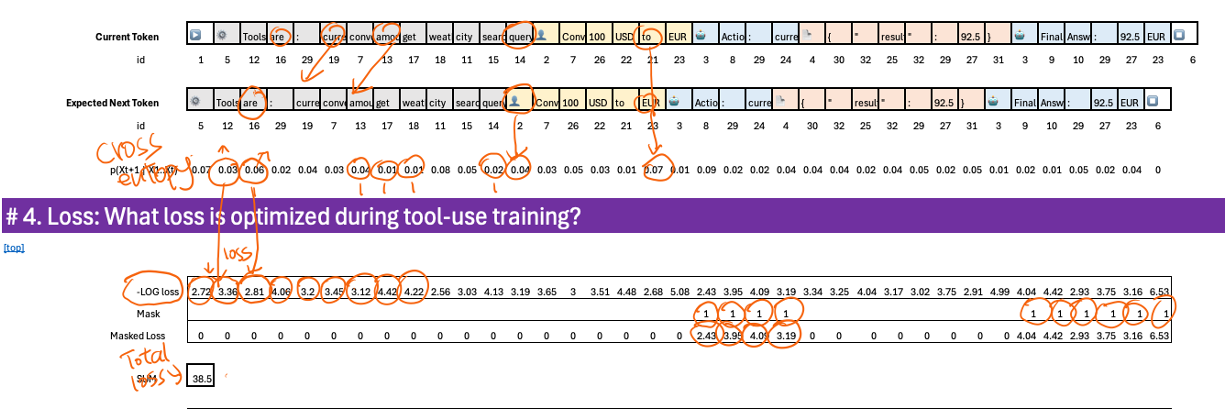
Tool calling is still next-token prediction, but now the “right” tokens represent actions and parameters. I illustrated the full pipeline, from flattening message trajectories into a single sequence, through embeddings, projections, softmax, and cross-entropy loss. The key technical insight is masking: during fine-tuning, loss is applied only to assistant tokens, the points where tool decisions are made. System and user tokens are ignored, which keeps training focused and efficient.
Recording & Workbook
Become a paid subscriber to access the full recording and the associated Excel workbook.