
Inference Batching, Request-vs-Token Level
Frontier AI Drawings: 9 of 13

Library › Frontier AI Drawings
Inference Batching, Request-vs-Token Level
")
Lately I have been helping an inference startup check whether their batch inference implementation really matches the math in the paper. In conversations with their engineers, I learned that one of the most confusing questions is why some operations can be “batched” and run in parallel across many requests, while others must be executed in strict sequence.
Can QKV projections be parallelized? What about the scaled dot product attention, or the feedforward layer? These are not minor implementation details — they determine whether the system is both correct and efficient.
Inference has become a billion-dollar battleground, with companies like Together, Anyscale, and Fireworks attracting huge VC bets. It is hard. Very few truly understand it, and those who do command the highest-paying jobs in the industry.
Drawings
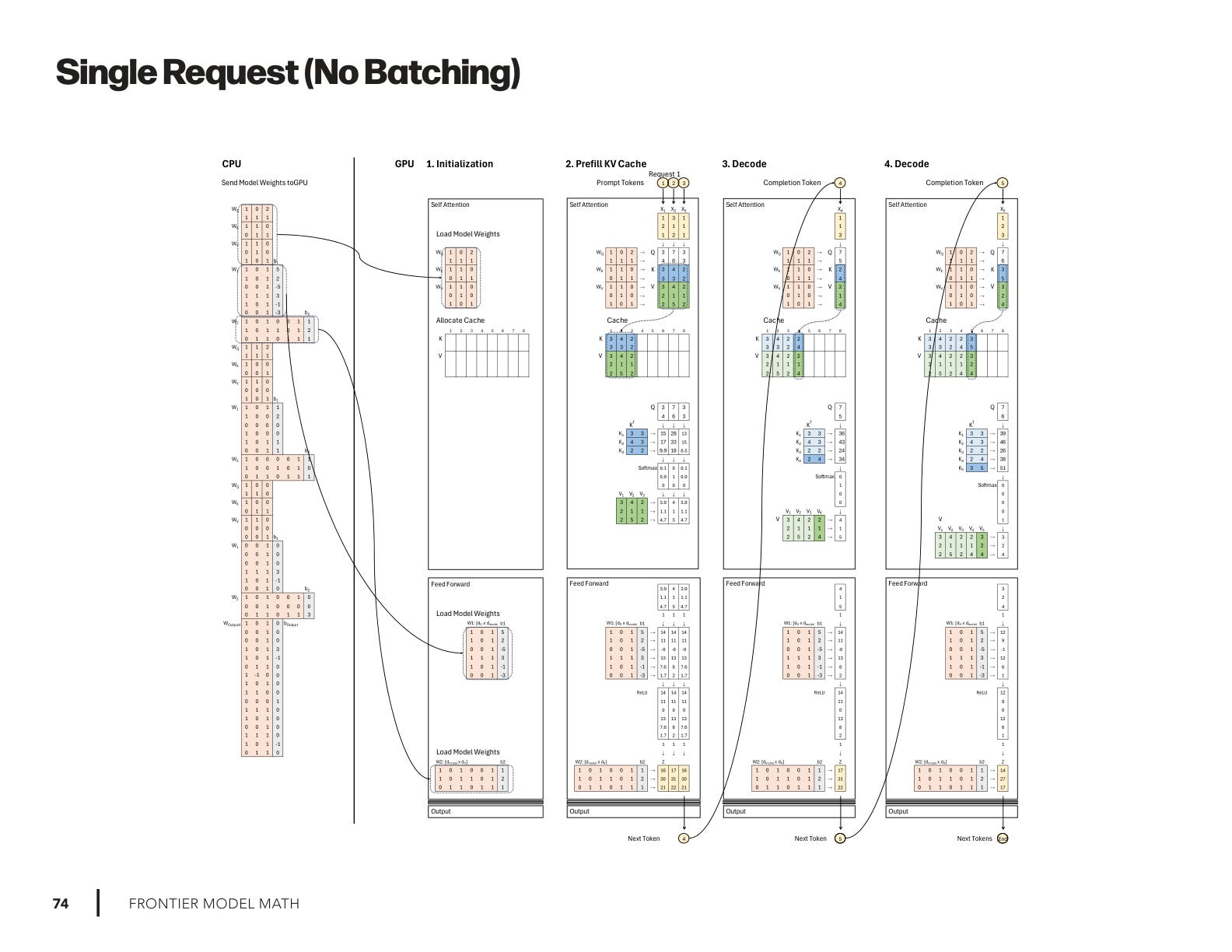
Two weeks ago we looked at the KV cache and the contrast between prefill and decode for one request. I was laying the foundation so that I can extend the story to multiple requests, and how they can be “batched” to run efficiently.
I created four new drawings:
Single Request (no batching)
Request-level Batching
Token-level Batching (a.k.a., continuous batching)
Decoding at different positions, the defining property of continuous batching
Work through these step by step, and you will see the answer to the question we started with: which parts of the inference pipeline can be combined and run in parallel across requests, and which must be executed in sequence. That clarity is the key to understanding why batching is the true secret sauce of inference startups!

Page 1 of 4
Become a member to access the rest of the drawings.