
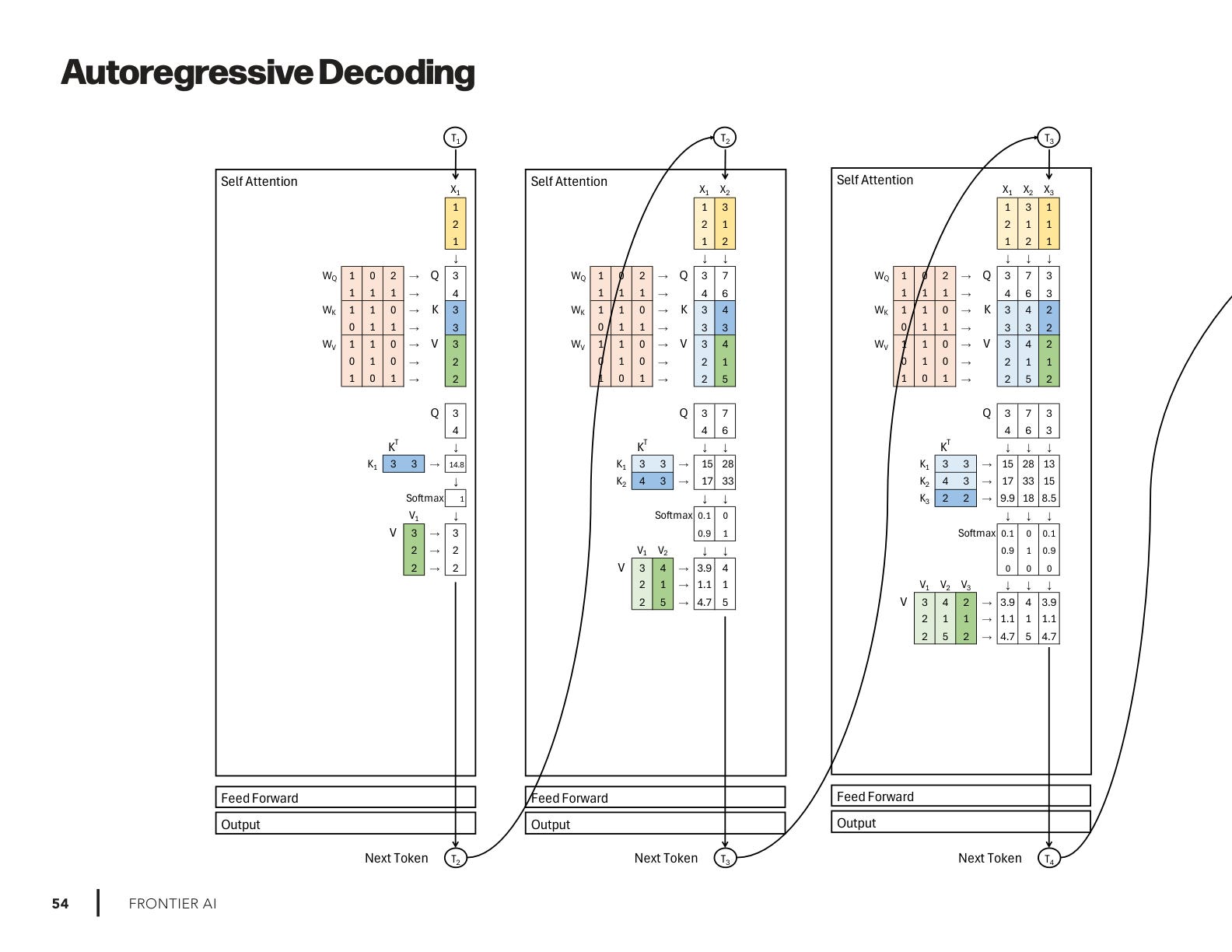
KV Cache, Prefill, Decode
Frontier AI Drawings: 7 of 13

Library › Frontier AI Drawings
KV Cache, Prefill, Decode

Back in March, Google dropped Gemma 3. In the abstract, one line jumps out to me: “reduces KV cache memory.” Not benchmarks—cache math. That’s the headline.
The trick? Alternating attention. Instead of every layer attending globally, Gemma 3 runs five local layers (~1K sliding window) for every one global layer. Result: This local–global design significantly reduces KV-cache memory growth, making long-context inference feasible in production.
One month later, Meta shipped Llama 4. I asked a friend there about the tech report. I was told: “Couple of weeks.” That was April. The report never came.
But the thing about open source? Even without a tech report, I can open the repo and see the alternating layers for myself.
Then in August, OpenAI came back to the open-source party with GPT-OSS. This time, the alternating pattern wasn’t hidden. It’s spelled out right in the model card: “attention blocks alternate between banded window and fully dense.”
In other words: the same playbook.
Three flagship models, three different teams, one common theme: KV cache efficiency.
Here’s the twist: 9 out of 10 AI engineers flip on KV caching without the faintest idea how it works. To them, it’s just a magic flag: kv_cache=True. Not to mention having little appreciation for what it means to reduce KV cache load.
But you can’t blame them. Nobody teaches this stuff. Not even myself in my grad AI course. Attention math? Sure. But inference efficiency, KV caching, prefill, batching, that’s invisible.
These are the building blocks. Without them, you can’t appreciate why “billion-dollar” startups like Together (popularizing continuous batching), Fireworks (extending FlashAttention to FireAttention), and Anyscale (vLLM with PagedAttention) are able to differentiate.
Drawings
So I created new drawings on KV cache, comparing decoding vs. caching vs. prefill, side by side:
Decoding one token at a time, no cache (slow).
With KV caching (fast).
With prefill (prompt first, then cache).
This is important groundwork. From here we’ll climb into the advanced techniques: PagedAttention, Continuous Batching, FlashAttention, Speculative Decoding.
But none of that sticks unless you first see how decoding, caching, and prefill actually work.

Page 1 of 6
Become a member to access the rest of the drawings.