
Self Attention vs Cross Attention
Attention: 5 of 11

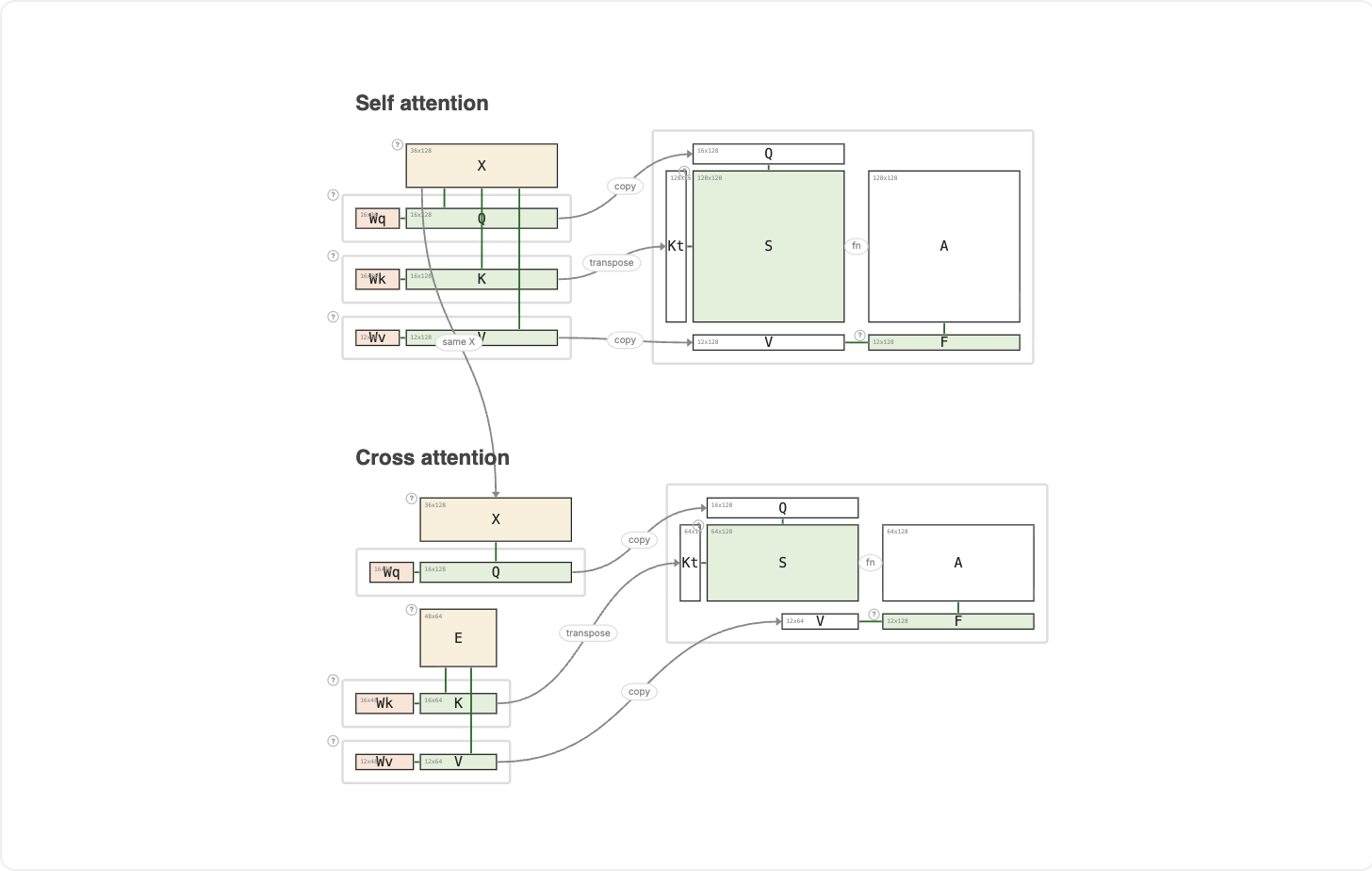
This is a review of the two previous articles, shown side by side.
Top: self-attention. Midnight. N neighbors are awake, every one of them asking "whose dog is barking?" Each neighbor queries every other neighbor. The score matrix is square: the queriers and the answerers are the same N people.
Bottom: cross-attention. Saturday morning. N neighbors are going on trips, asking M teens "who can sit my dog?" Each neighbor queries every teen, but not each other. The score matrix is rectangular: the queriers and the answerers are two different groups.
Both use the same X for queries. The only difference is where K and V come from. In self-attention, K and V are drawn from X itself. In cross-attention, K and V come from a second sequence E. That single change is what shifts the matrix from N × N to N × M.
Notice what stays the same in both: Q and K must share the same key dimension, because the dot product Kᵀ × Q only works when they land in the same space. V is free to have its own dimension in either case.