
LoRA, Fine-Tune, Pre-Train
Frontier AI Drawings: 5 of 13

Library › Frontier AI Drawings
LoRA, Fine-Tune, Pre-Train

When Apple recently released their tech report, Apple Intelligence Foundation Language Models Tech Report, I wasn’t surprised to see LoRA mentioned.
By now, LoRA isn’t just a research curiosity — it’s everywhere. From startups running small models on edge devices to major players scaling frontier systems, parameter-efficient fine-tuning has become the standard toolkit.
What’s especially significant is that Apple highlights LoRA as a capability they want for their developers — “to integrate these capabilities with just a few lines of code.” That’s a strong signal of how mainstream LoRA has become.
Yet even though the idea behind LoRA is deceptively simple, many AI engineers have never looked at the math — beyond making a few library calls.
Not long ago, one company’s AI team leader reached out to me:
> “Can you help our team really understand LoRA?”
The company is deeply engaged in parameter-efficient fine-tuning, and they know that true understanding requires going beyond the API.
Drawings
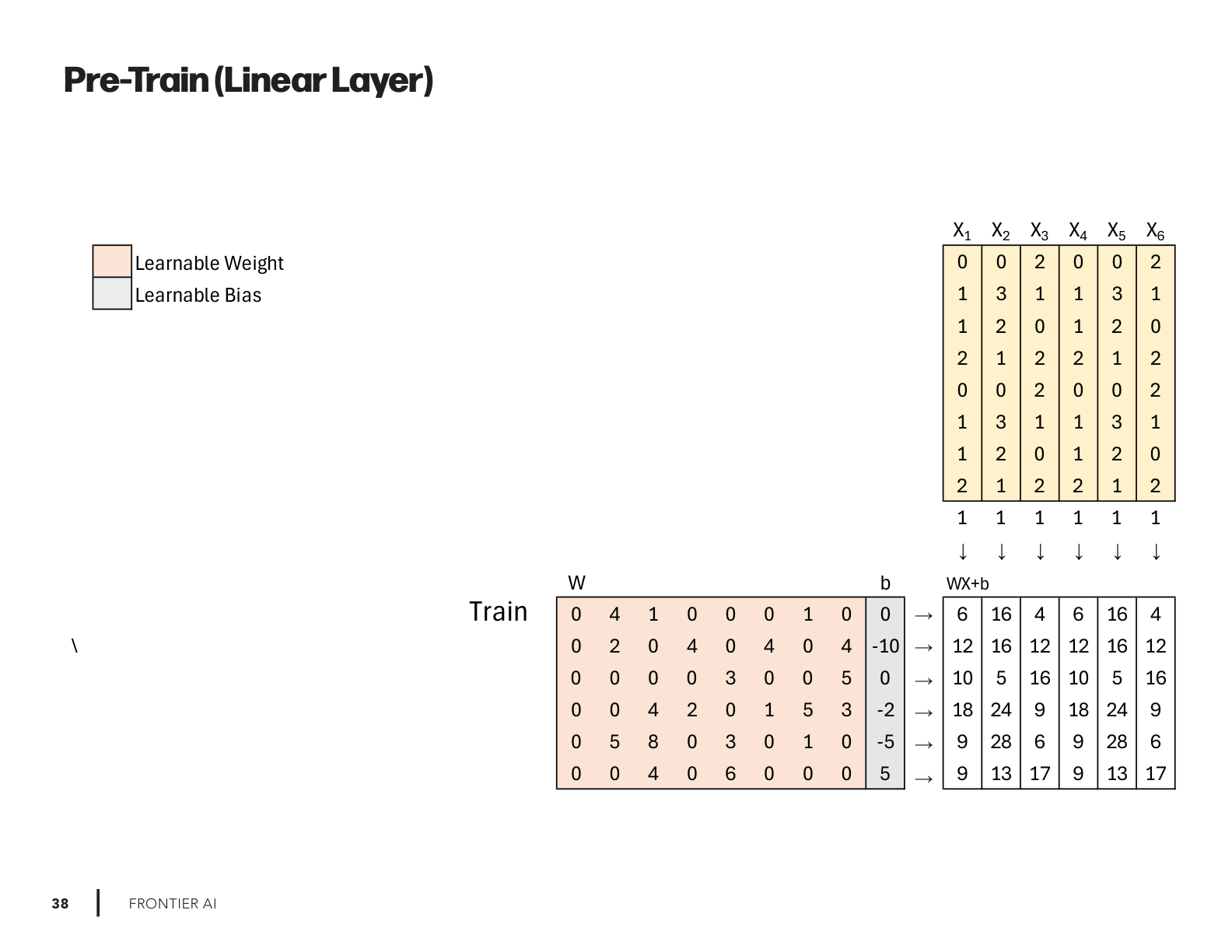
This issue comes with six new drawings on Pre-Train, Fine-Tune, and LoRA — shown side by side in both Linear Layer and Self-Attention (3 × 2 = 6). I built them to help you get straight to the math and intuition, skipping the equation slog.
The six new worksheets are:
Pre-Train (Linear Layer)
Fine-Tune (Linear Layer)
LoRA (Linear Layer)
Pre-Train (Self Attention Layer)
Fine-Tune (Self Attention Layer)
LoRA (Self Attention Layer)

Page 1 of 6
Become a member to access the rest of the drawings.