
MXFP4, FP4, FP8
Frontier AI Drawings: 4 of 13

Library › Frontier AI Drawings
MXFP4, FP4, FP8

When OpenAI released gpt-oss, I noticed something small but important buried in their model card:
> “… quantization of the MoE weights to MXFP4 format …”
Almost right away, a leading AI company working on local inference reached out:
> “Our AI engineers need to understand MXFP4 …. they need to understand how it fits 120 billion parameters into 80GB GPU memory.”
Lesser-known players have experimented with MXFP4 in various parts of their pipelines. But seeing OpenAI adopt it in gpt-oss tells us this isn’t just a niche trick anymore.
The idea behind MXFP4 is simple, but it’s not explained well in materials you can find online. Existing materials are either papers with hard-to-understand equations or articles listing CUDA kernel code. Explaining it in a way where you can actually calculate it by hand ✍️ — that’s what we do here.
Drawings
For this Issue, I created four new drawings:
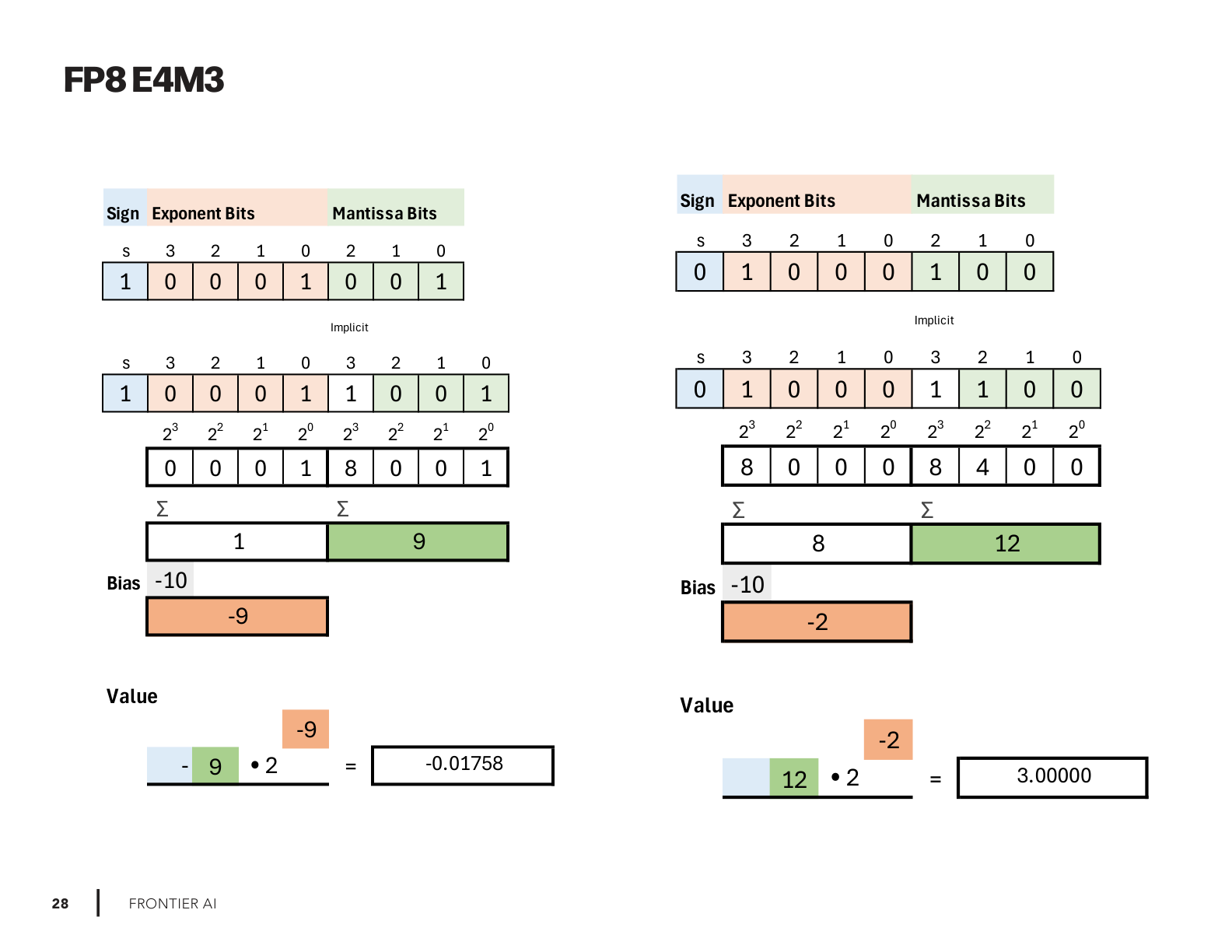
FP8-E4M3
FP8-E5M2
FP4-E2M1
MXFP4

Page 1 of 8
Become a member to access the rest of the drawings.