
PPO Clipped Policy Loss Algorithm
Frontier AI Algorithm Blueprint Series

I’m piloting a new series — Frontier AI Algorithm Blueprints — where I rebuild, from first principles in Python and Excel, the core algorithms that power today’s frontier AI models.
Introduction
You want to change your diet (policy). The goal is to increase the probability of foods (actions) that made you feel better than expected and decrease the probability of those that made you feel worse. But if you switch too drastically in one step (omnivore → vegan), your body can become unstable and your health may even collapse.
If this intuition makes sense, we can now state the same motivation more formally.
In the standard policy gradient formulation, we increase the probability of actions that are better than expected and decrease the probability of those that are worse by scaling the update with an advantage estimate and a probability ratio between the new and old policies. However, if the new policy moves too far from the old policy in a single update, training becomes unstable and performance can collapse.
Proximal Policy Optimization resolves this by introducing a clipping mechanism that limits how much the policy is allowed to change at each step (for example, no more than 15% of daily calories or ε =0.15 ). This is often called the PPO clipped policy loss.
Application Context
To calculate the PPO clipped policy loss, we need three ingredients: (1) the old log-probability of the sampled action, (2) the new log-probability of that same action under the updated policy, and (3) the advantage.
The first ingredient is obtained during a rollout with the old policy network. As the agent moves through a sequence of states (s0, s1, …), the old policy samples an action at each state, and we record the probability and log-probability of the selected action. These stored log-probabilities capture how the old policy actually behaved during data collection, and they are treated as fixed reference values during the subsequent update.
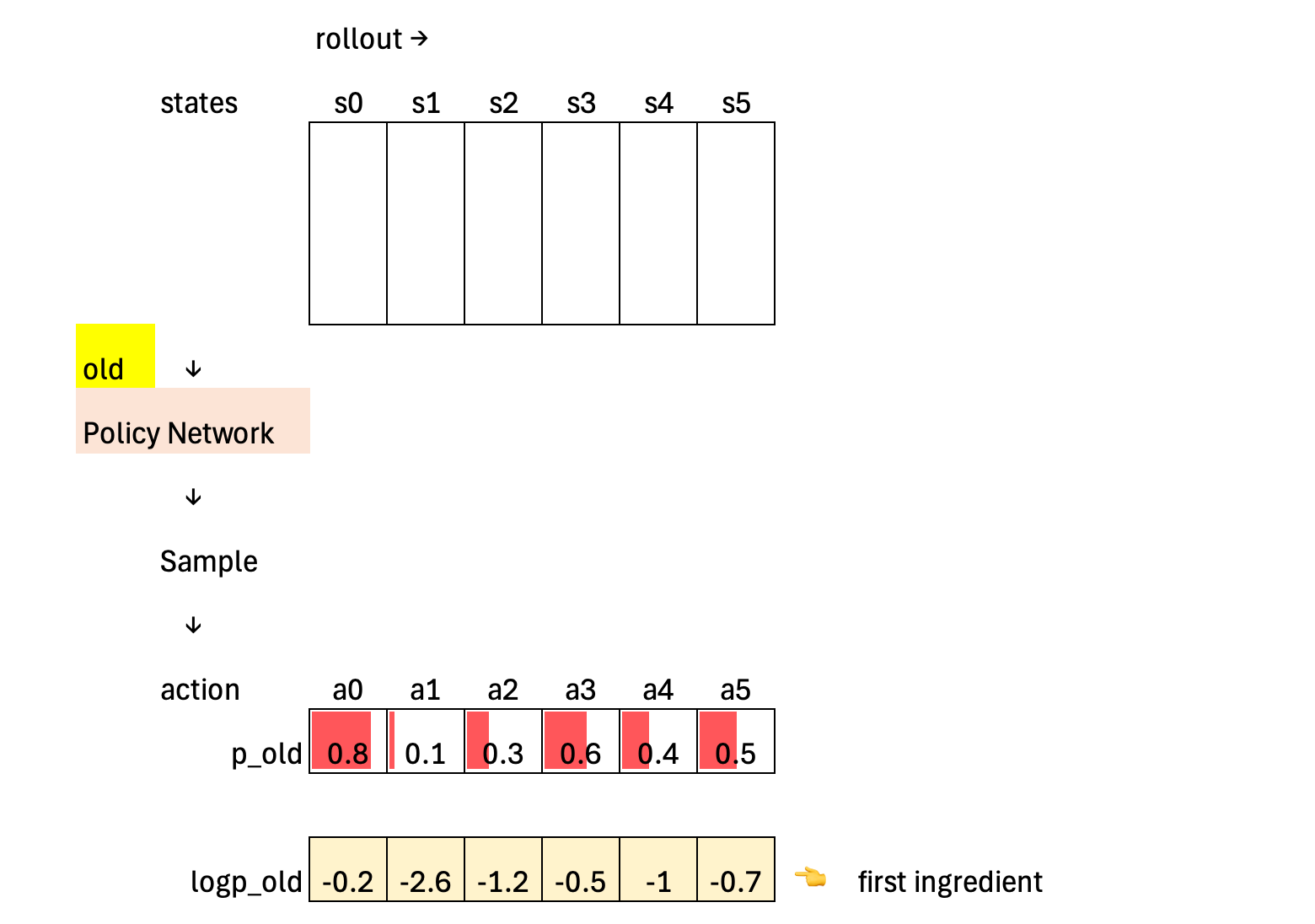
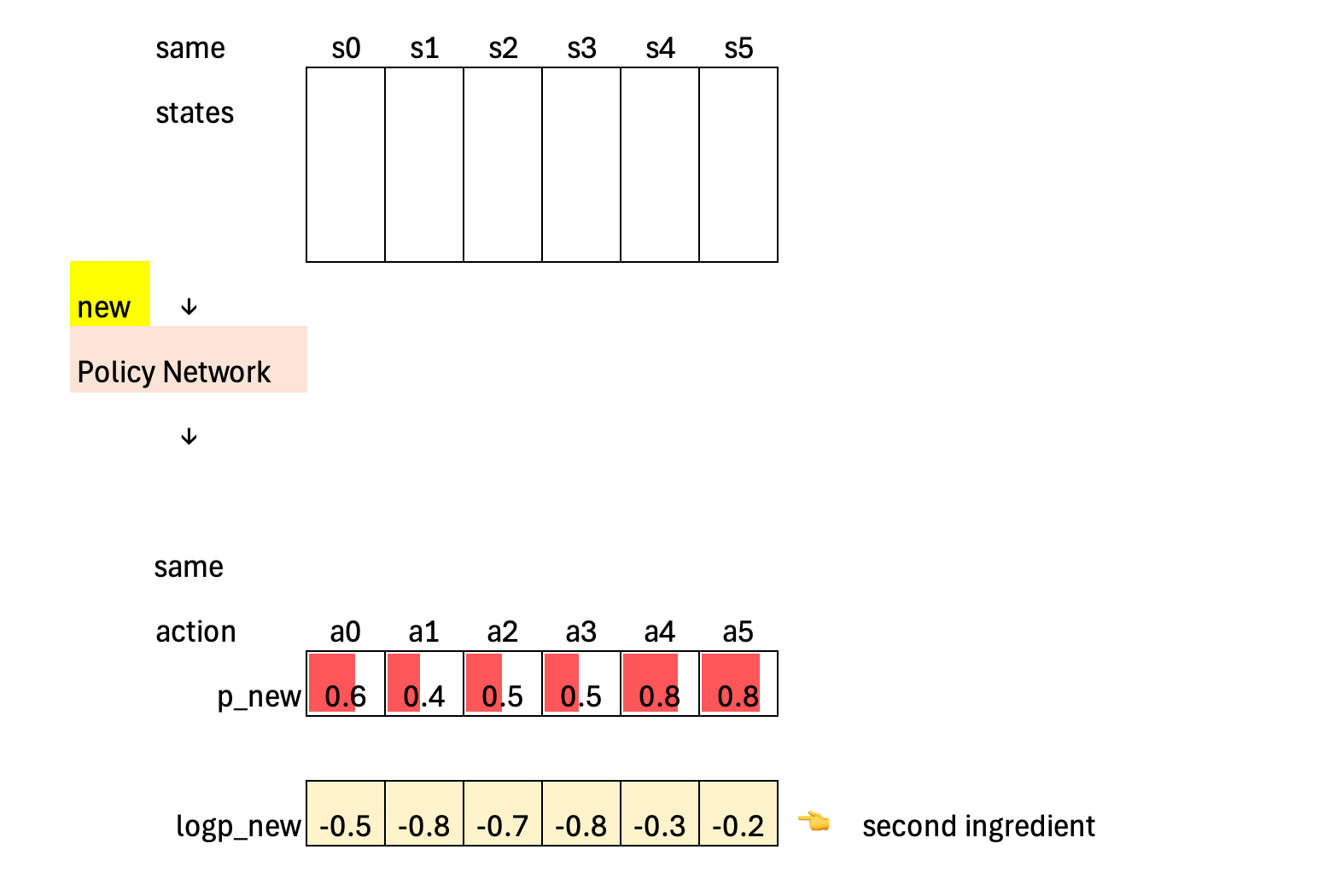
The second ingredient comes from the updated policy. The policy network is updated by computing the loss from the previous rollout and applying gradient descent to its parameters.

After the policy network parameters have been changed, we pass the same sequence of states through the new policy to compute the probabilities and log-probabilities of the exact same actions that were sampled earlier—no new actions are drawn. In this way, for every timestep we obtain a pair consisting of the old log-probability and the new log-probability for the same state–action combination, which allows us to measure how much the policy has changed.
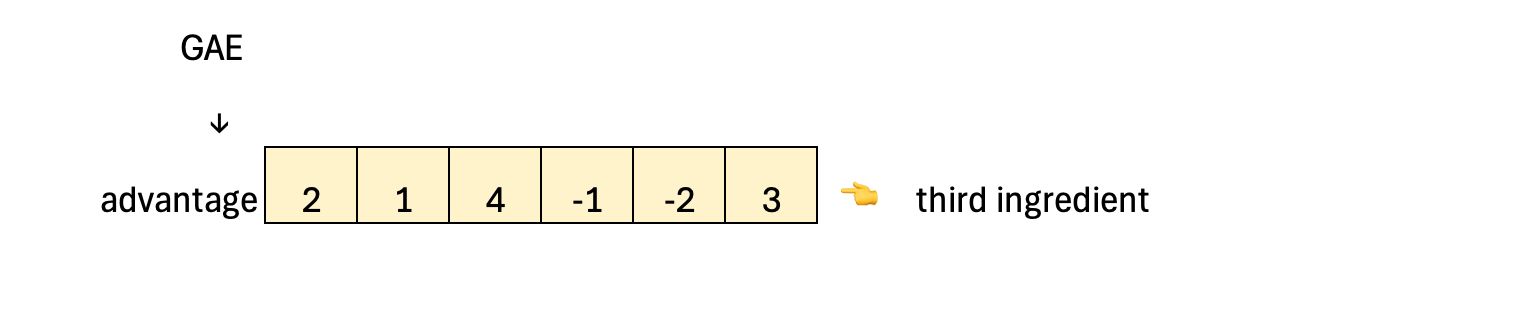
We then add the third essential ingredient: the advantage, which tells us whether that action turned out better or worse than expected. In practice, the advantage is most often computed using Generalized Advantage Estimation (GAE) (more details in another blueprint).
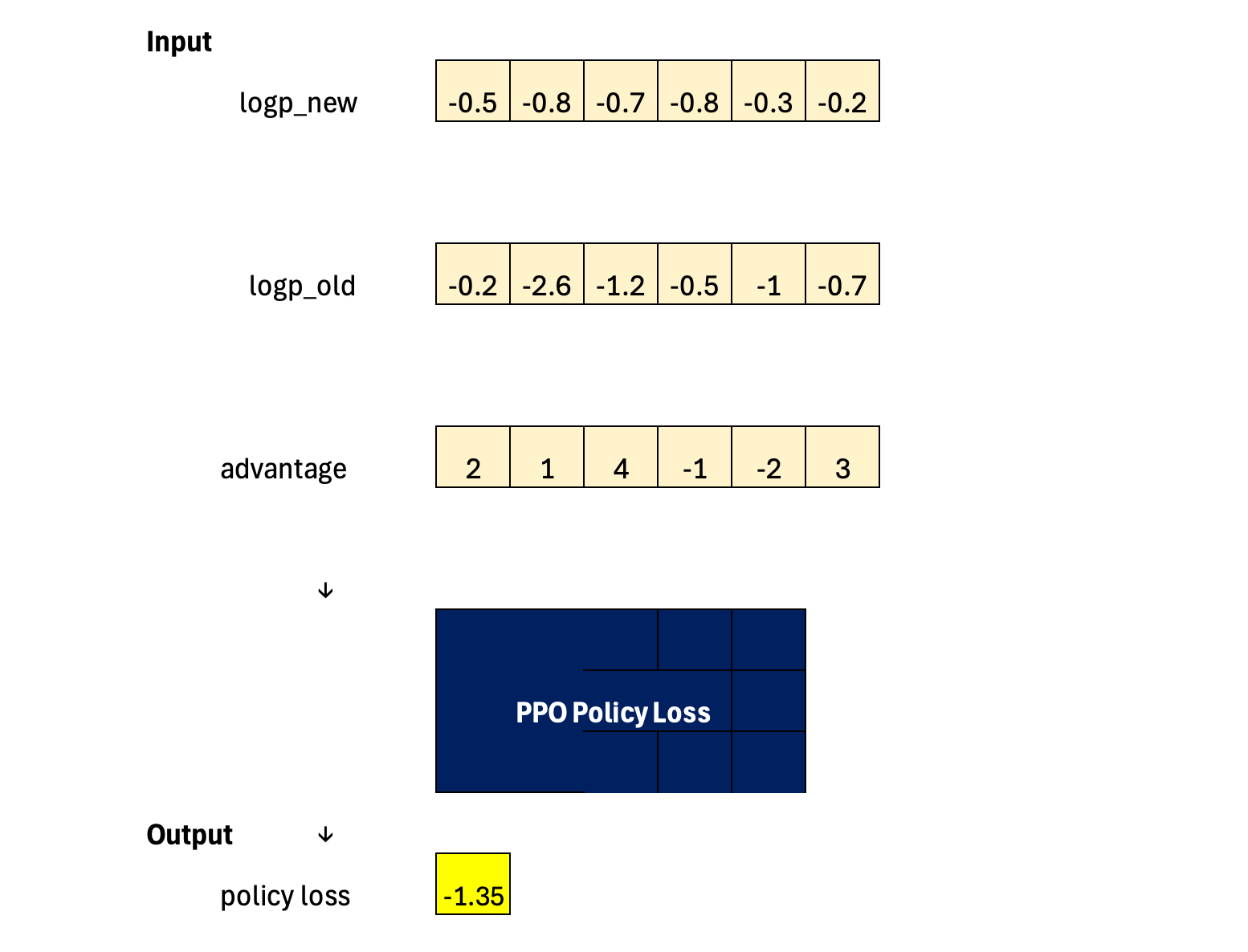
With these three ingredients—the old log-probability, the new log-probability, and the advantage—we have everything needed to evaluate the PPO clipped policy loss.
Hyperparameter
The hyperparameter ε controls how conservative the learning process is: smaller values lead to more cautious updates, while larger values allow more rapid but potentially less stable learning.

Algorithm
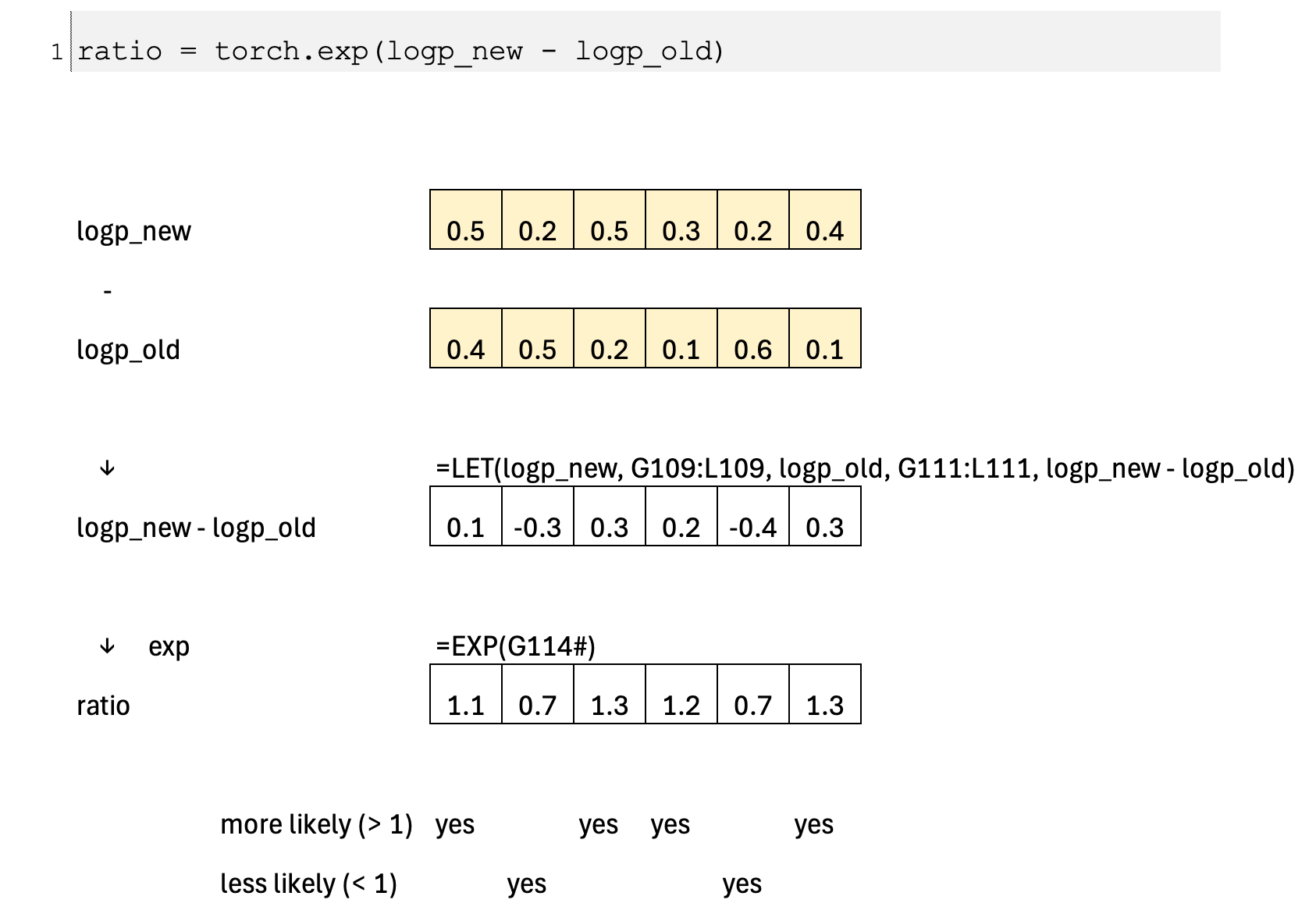
Calculate the ratio between new and old policy
We begin by computing the probability ratio between the new policy and the old policy for the same action. This ratio measures how much the new policy has changed: a value greater than one means the action has become more likely, while a value less than one means it has become less likely. This single quantity captures the direction and magnitude of the policy update and is the core signal used to adjust the policy.
Calculate the unclipped objective
Next, we form the unclipped objective by multiplying this ratio by the advantage. This is the same expression used in the vanilla policy gradient and represents the full, unconstrained update. When the advantage is positive, the objective encourages the probability of the action to increase; when the advantage is negative, it encourages the probability to decrease. On its own, this term would push the policy as far as possible in the direction of improvement.

Clamp ratio into the trust region
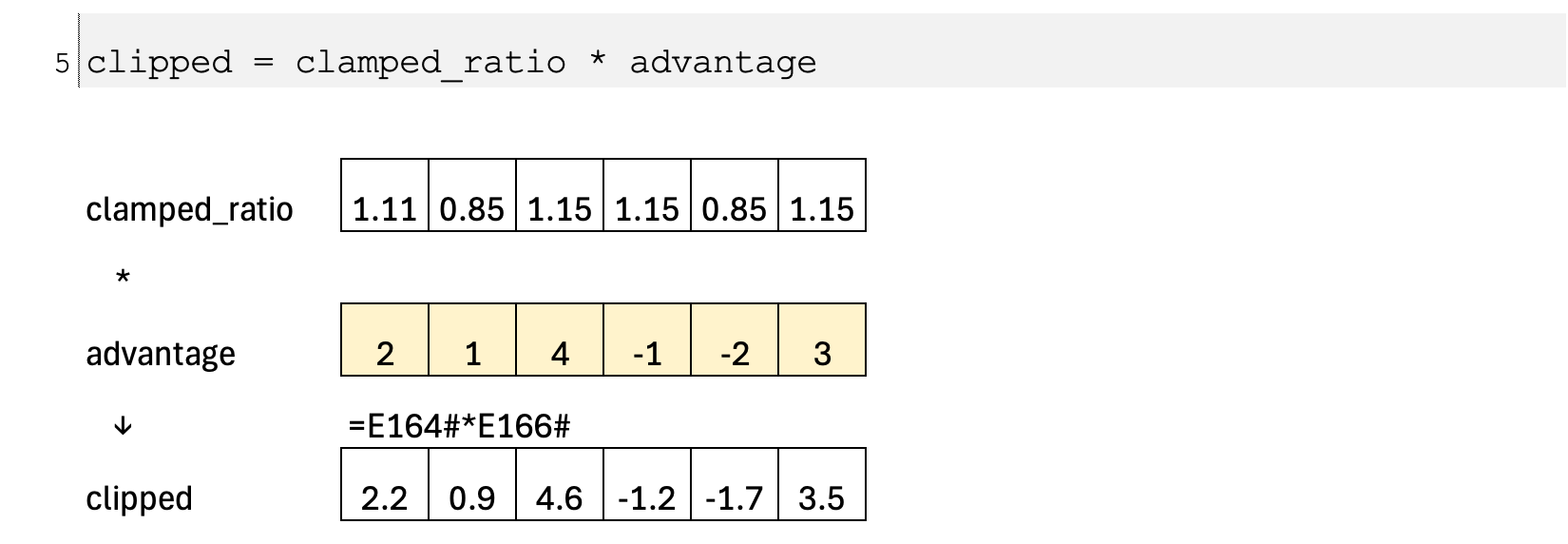
To prevent overly large updates, we define a trust region in the form of an interval [1−ε,1+ε]. This interval specifies the maximum amount by which the new policy is allowed to differ from the old one in a single update. We then clamp the ratio so that it cannot move outside this interval. If the new policy tries to increase the probability of an action too much, the ratio is capped at the upper bound; if it tries to decrease it too much, the ratio is raised to the lower bound. In this way, we construct a “safe” version of the policy change that respects the trust region.

Calculate the clipped objective
Using this clamped ratio, we compute a second objective—the clipped objective—which represents the best update we are willing to accept under the safety constraint. This term still follows the sign and magnitude of the advantage, but it no longer allows large deviations from the old policy.
Take the conservative objective
The key idea of PPO is to take, for each sample, the minimum of the unclipped and clipped objectives. This implements a conservative learning rule: we keep the full update when it is small and beneficial, but we switch to the clipped version whenever the update would otherwise be too large. As a result, the policy improves steadily while avoiding destructive jumps.

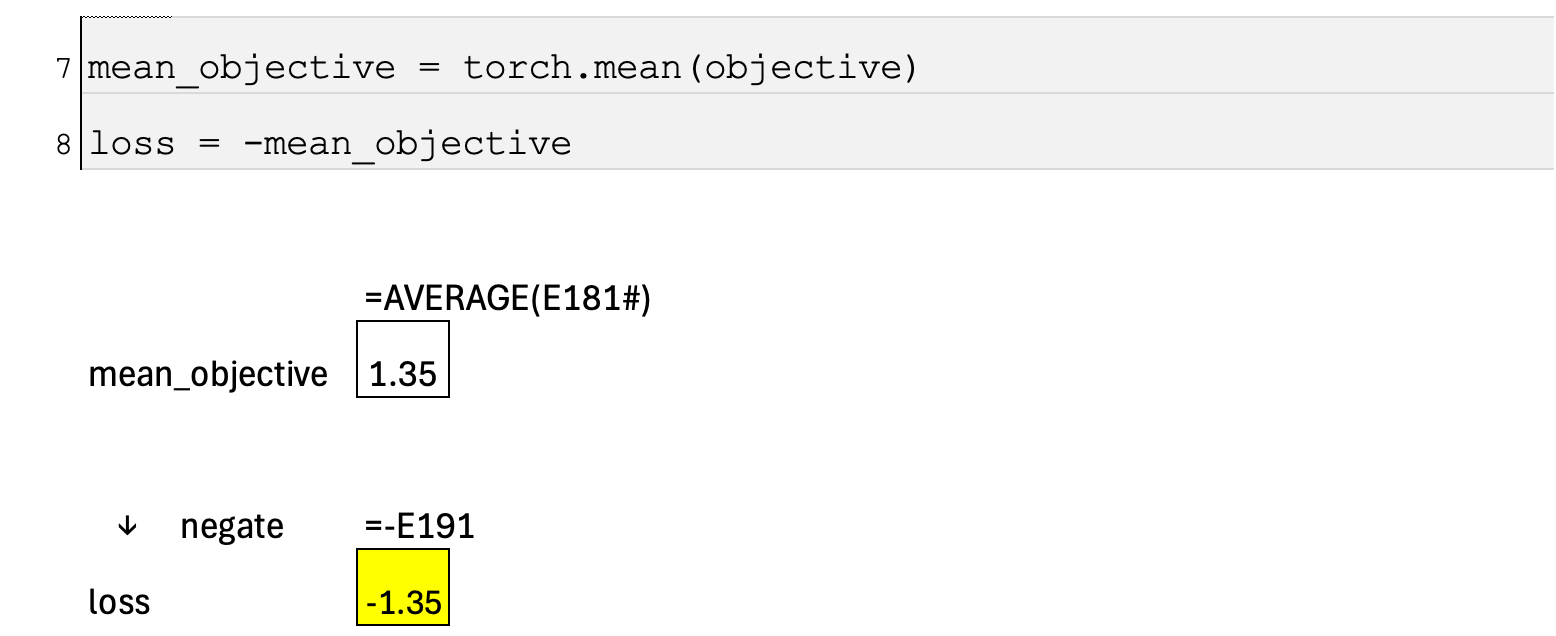
Averaging across the batch and converting to loss
Finally, we average the objective over the batch of collected timesteps to obtain a single scalar for optimization. Because the objective is defined in the direction of improvement (we want to maximize it), we negate it to convert it into a loss that can be minimized by gradient-based methods. The overall effect is an update that consistently moves the policy in the direction indicated by the advantage, but only as far as is considered safe in a single step.
Excel Blueprint

(p.s., limited time preview)
This Excel Blueprint is available to AI by Hand Academy members. You can become a member via a paid Substack subscription.
Where is this applied?
Can we include cases for TSp where objective is to minimise distance which will flip advantage?