
QLoRA, DoRA, BitFit, NF4 vs INT4
Frontier AI Drawings: 6 of 13

Library › Frontier AI Drawings
QLoRA, DoRA, BitFit, NF4 vs INT4

My very first class at MIT was with the legendary Robert Tappan Morris (yes, the same Morris behind the Morris Worm that brought down parts of the early Internet in 1988). He was the first person ever indicted by the FBI under the Computer Fraud and Abuse Act.
In that same class, I met Luke Zettlemoyer. Luke is now a professor at the University of Washington, and published the impactful QLoRA paper — a breakthrough that showed how to fine-tune giant language models with just 4-bit NormalFloat (NF4) quantization. The result: state-of-the-art performance made accessible on a single GPU.
I feel very happy for Luke. Seeing an old friend continue to make such big contributions to our field is inspiring.
Drawings
Last week, we worked through six drawings on Pre-Train, Fine-Tune, and LoRA, shown side by side in Linear Layers and Self-Attention. That set built the foundation: how low-rank adaptation naturally fits into the training pipeline.
This week, we turn to LoRA’s extended family: qLoRA, DoRA, and BitFit. With it comes a new challenge: quantization.
qLoRA: LoRA with 4-bit NormalFloat (NF4) quantization, enabling fine-tuning on a single GPU.
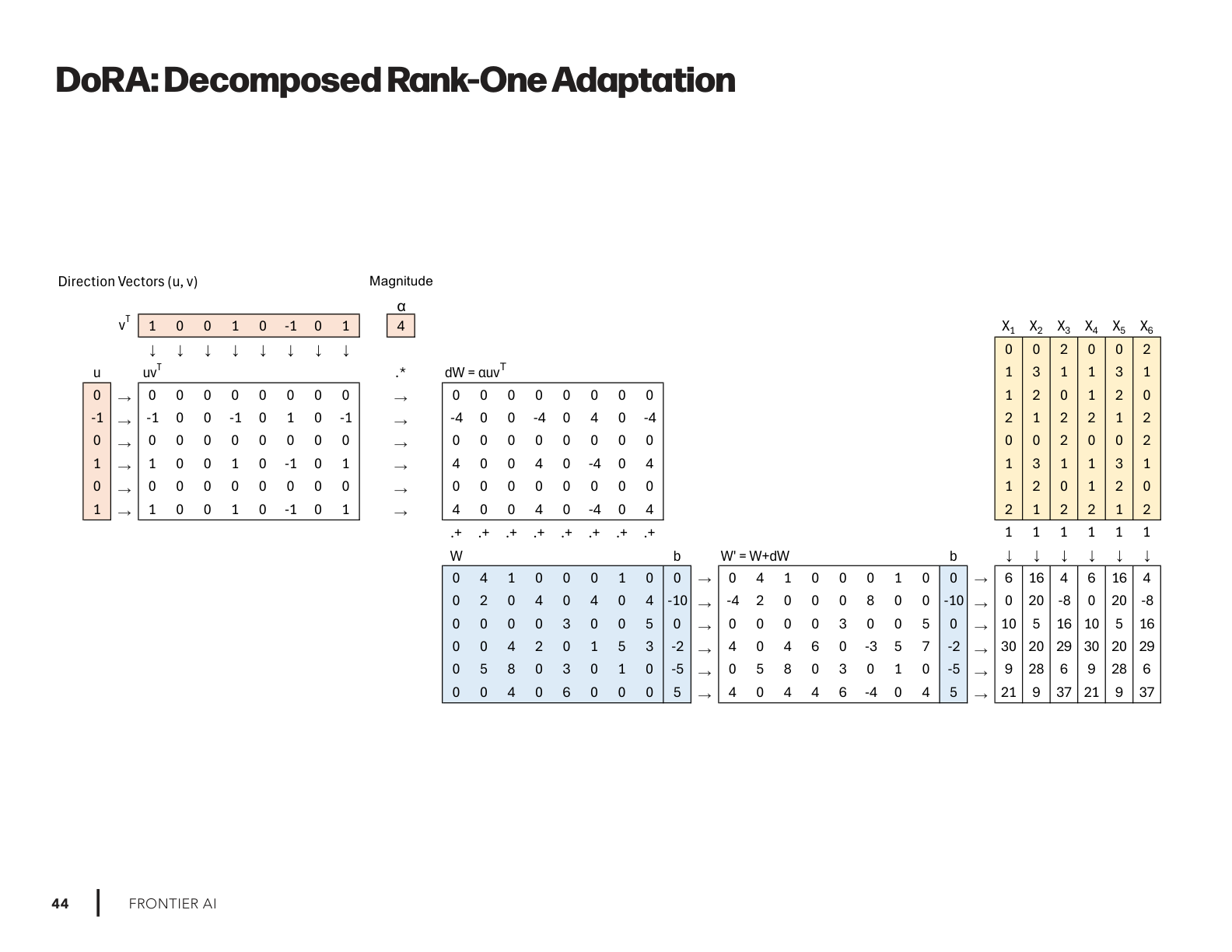
DoRA: A variation that updates only directions in weight space instead of full matrices.
BitFit: The simplest of all—fine-tune just the bias terms and still see gains.
Also, I created a new drawing comparing NF4 and INT4. Both use 4 bits (16 levels), but they distribute them very differently:
INT4: Splits the range evenly, wasting many levels where no weights actually live.
NF4: Places bins according to a normal distribution, concentrating levels where weights are dense.
The result? INT4 throws away resolution, while NF4 preserves it. This single design difference explains why qLoRA with NF4 achieves near full-precision accuracy, while INT4 falls short.

Page 1 of 7
Become a member to access the rest of the drawings.