
Qwen 3
Frontier AI Drawings: 13 of 13

Library › Frontier AI Drawings
Qwen 3
I know many of you have been waiting for this: the full, step-by-step breakdown of Qwen3, presented in the AI by Hand ✍️ way so you can see every tensor and how they click together.

Why Qwen 3?
I chose to breakdown Qwen 3 because it brings together nearly every frontier concept we’ve studied so far, from RoPE and RMSNorm to sparse MoE. It sets the stage for Qwen 3-Next, which adds a state-space model layer, blending two powerful paradigms.
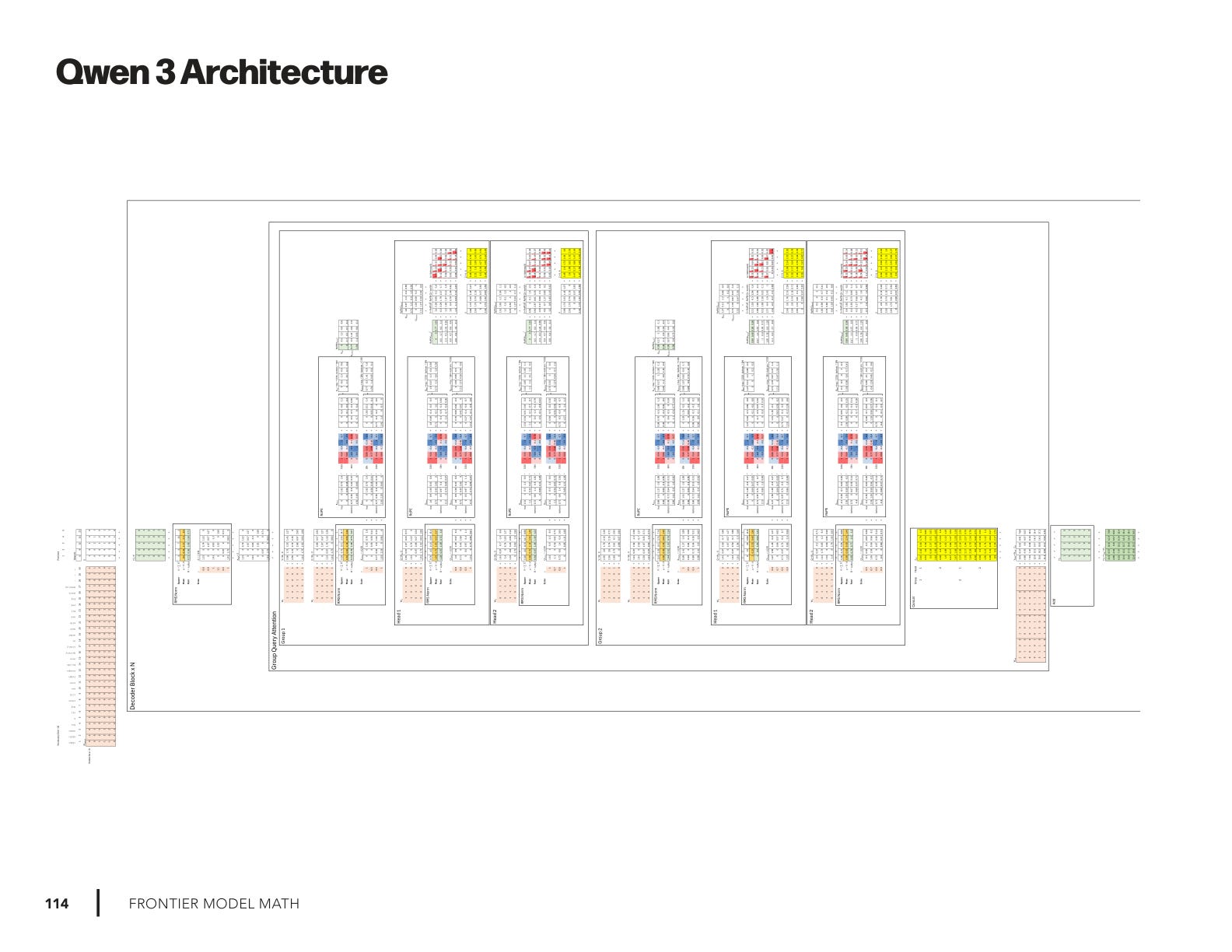
This is where the series comes together. Every concept from the twelve articles before this one shows up in Qwen 3: RoPE for positional encoding, Group-Query Attention for efficient multi-head attention, RMSNorm for normalization, and sparse MoE to activate only a fraction of parameters per token.

I know some of you work in infrastructure, some in training systems, others on model internals. I’ve heard from you that these drawings have become your shortcut to clarity. You’ve told me they help you skip the paper grind, parse the math faster, and get straight to math-accurate implementation. One of you mentioned using the worksheets to explain to colleagues the importance of parameter-efficient fine-tuning, a perfect example of how these materials are finding life beyond just individual study. I’m genuinely glad to hear that, because that’s exactly why I created this series.
Drawings
In this week’s full Qwen3 breakdown, I created the following new drawings:
Two-page spread of the full Qwen3 architecture for quick orientation
Mini-map that previews each section and how it flows
Zoomed-in panels with worksheets that walk through each section of the architecture
Section-by-section detail:
Input → Embedding
Attention: Group-Query Attention + RoPE
Mixture of Experts (MoE):
Output stack: RMSNorm → Linear → Softmax → Sample
Each panel shows the exact tensors, shapes, and operations.
Page 1 of 11
Become a member to access the rest of the drawings.