
PPO → DPO → GRPO → Rubrics (Mar 2, 2026)
AI by Hand ✍️ Seminars

Library › Seminar Series 2026
Manifold-Constrained Hyper Connections (mHC) from DeepSeek (Jan 9, 2026)
Meta Superintelligence Labs vs Facebook AI Research (Jan 30, 2026)
PPO → DPO → GRPO → Rubrics (Mar 2, 2026)
In last week’s AI by Hand ✍️ seminar, I talked about reinforcement learning from first principles. I started all the way back from pre-training and inference, before climbing forward through the major evolution stages of the modern RL stack: PPO → DPO → GRPO. I finally arrived at Rubrics, widely considered one of today’s frontier topics in RL research.
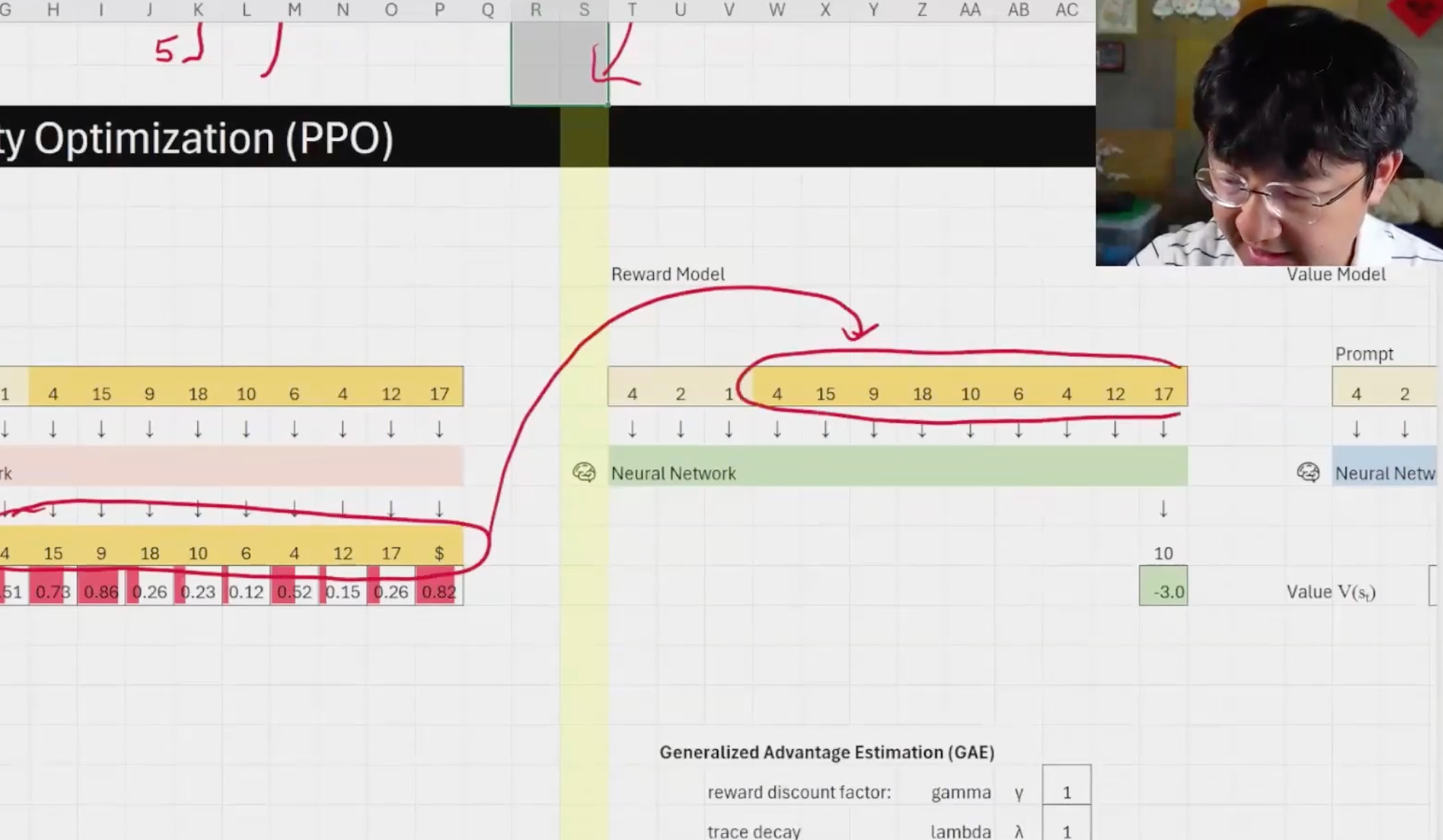
I was joined by Cameron R. Wolfe, author of the Deep (Learning) Focus newsletter (60K subscribers) and a Senior Research Scientist at Netflix. He gave a special guest lecture based on his popular recent article Rubric-based Rewards for RL.

After eight seminars in 2026, I’ve settled into a format that has clearly resonated:
AI by Hand Lecture → Industry Guest Interview → Industry Guest Lecture.
I’m the professor in the first half—and the student in the second. 🙌
Feedback
Industry Expert: Cameron Wolfe
As a professor in academia, how can I possibly know what kind of research is really going on in the industry? I turn to people like Cameron. I've been reading his long-form articles long before I even started sharing my own content through this AI by Hand newsletter. Cameron was one of the early supporters who encouraged me to share more publicly.
I still remember two years ago when he told me he had just gotten married and was moving to Netflix to become a Senior Research Scientist working on reinforcement learning. He mentioned he might need to pause the Deep Focus newsletter for a while. Fortunately for all of us, the break was short. Cameron kept writing. I kept learning.
In the seminar, I finally got a chance to interview him so his story can be heard by all of you:
Q: Can you use Jiu-Jitsu as a metaphor to explain reinforcement learning?
Q: Reinforcement learning used to feel like robotics demos. Why has RL become so important for frontier language models?
Q: What are the main challenges of doing RL research at large scale?
Q: What motivated you to write the Deep Focus newsletter?
Watch the recording to hear Cameron explain it in his own words.
Recording & Workbook
Become a paid subscriber to access the full recording and the associated Excel workbook.