
GPU by Hand ✍️ Together (Nov 2, 2025)
AI by Hand ✍️ Seminars

“Dad, why didn’t you buy a ton of NVIDIA stock and become a millionaire? Didn’t you work on AI?”
My son hit me with that one recently. Ouch. He asked me the same question about Bitcoin last year too. 🤣
No, I didn’t retire by owning $NVDA.
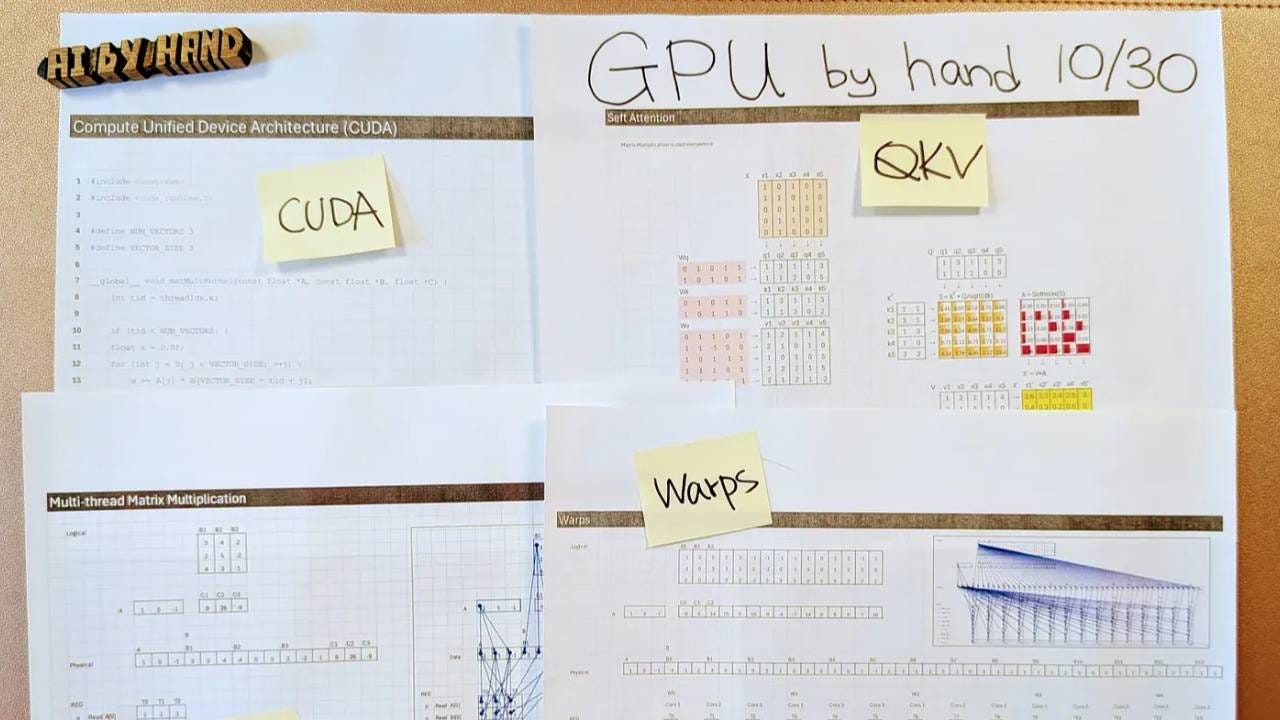
But I did choose to own something else: a deep understanding of how GPUs actually work: threads, warps, blocks, CUDA.
That’s what this lecture was about.
In this session, I used my AI by Hand ✍️ approach to demystify GPU execution from first principles, treating Excel not as a spreadsheet but as a giant whiteboard we filled in together. We started from the original meaning of GPU = graphics, using simple point-cloud transformations to show how matrix multiplication powers graphics, and why dot products are such a natural fit for parallel hardware.
From there, I connected that intuition directly to Transformers. Not to re-teach attention, but to make one idea stick: Transformers are dominated by repeated matrix multiplications, and that repetition is exactly what GPUs are designed for.
I then peeled back the execution model step by step:
how a dot product maps to load → multiply → accumulate
how repeating the same computation with different offsets becomes parallel threads
how thread IDs turn into real CUDA-style indexing
how those threads are scheduled into warps and blocks, and what it really means to share memory within a block but not across blocks
I closed by building intuition for quantization and mixed precision: why saving memory matters at scale, how naïve quantization can destroy signal, and how modern GPU designs evolve to support these AI-driven workloads efficiently.
No stock tips here. Just the kind of understanding that lets you see what’s really happening when a model runs.
Special thanks for Zain Hasan and Together AI for hosting and sponsoring this lecture. Check out his popular RAG course on DeepLearning.ai.
Special thanks for Shanya Chaubey to volunteer to be my teaching assistant. It was really nice to reunite with her. Go Buffs! 🦬
Feedback
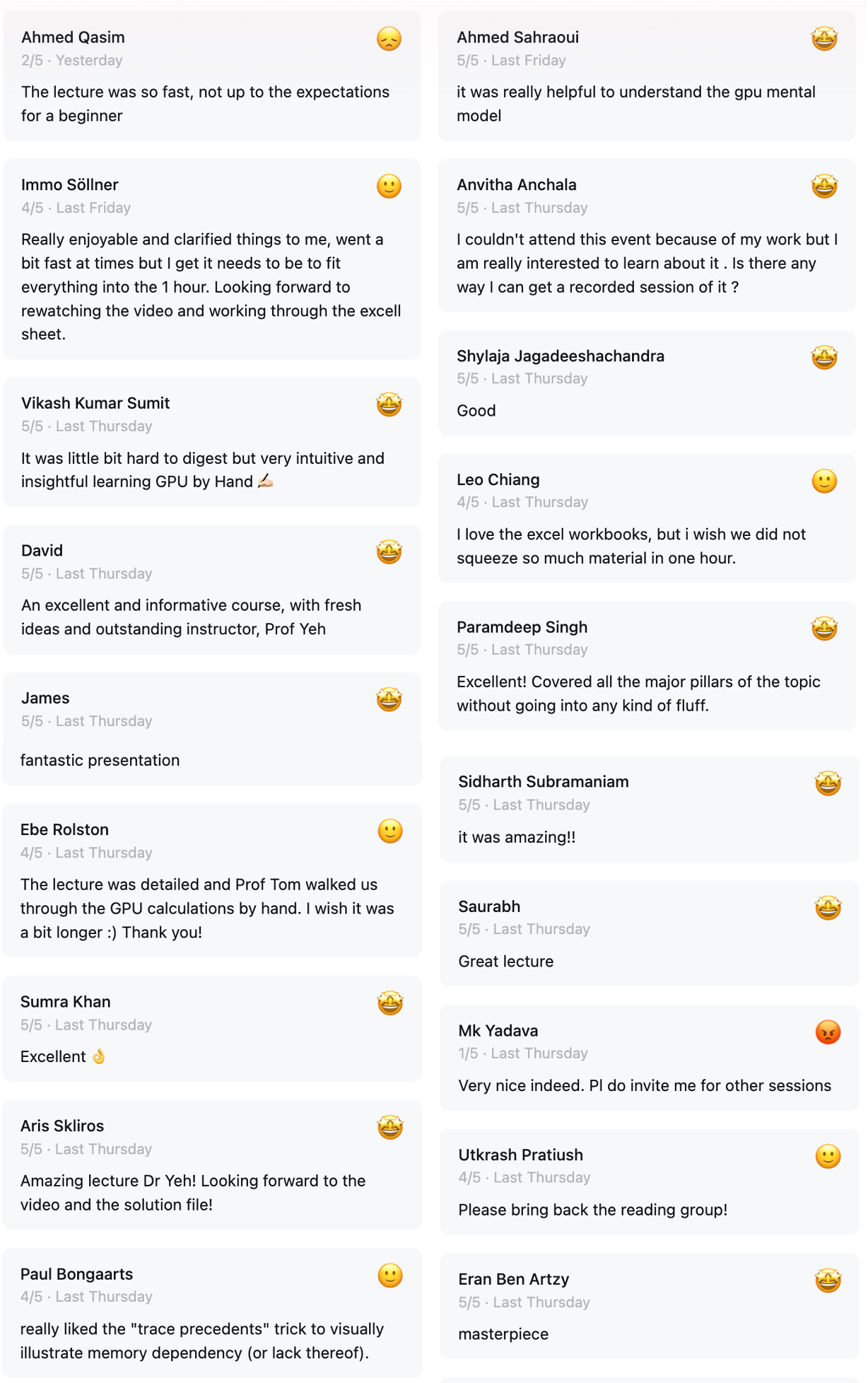
🙏🙏🙏🙏🙏 Thank you all for the thoughtful feedback! This lecture has been months in the making. It took a lot of trial and error to find a way to break the GPU down to its first principles, all by hand ✍️.
Strengths (in participants’ words):
“Amazing lecture, Dr. Yeh!”
“An excellent and informative course, with fresh ideas and an outstanding instructor.”
“Very intuitive and insightful learning GPU by Hand ✍🏻.”
“Really liked the ‘trace precedents’ trick to visually illustrate memory dependency.”
“Covered all the major pillars of the topic without any fluff.”
“Masterpiece.”
“Matrix multiplication is all you need.”
“I love the Excel workbooks!”
“Great way to see how GPU works, lots of stuff packed in one hour.”
“Fantastic presentation.”
“It was amazing!!”
Weakness: Some beginners found the pacing was too fast. They found it hard to keep up with formulas like MMULT and LET, especially while following the live chat.
Mitigation: I’ll keep the current pace to preserve the rigor and depth that the majority of attendees valued, but I’ll also provide separate warm-up exercises focused on Excel basics, notation, and setup. This way, newcomers can build confidence before the main lecture, without slowing the momentum for experienced learners.
Recording & Workbook
Become a paid subscriber to access the full recording and the associated Excel workbook.