
RLHF PPO Blueprint
Frontier AI Excel Blueprint

In this week’s issue, I’m sharing the initial results of my research to break down RLHF PPO into a fully traceable AI by Hand ✍️ Excel Blueprint.
RLHF PPO = Reinforcement Learning from Human Feedback (RLHF) trained with Proximal Policy Optimization (PPO). Popularized by OpenAI, it has since become widely used across the industry to align large language models.
If I had to nominate the most complex loss function used in frontier AI, there’s no doubt: it’s RLHF.
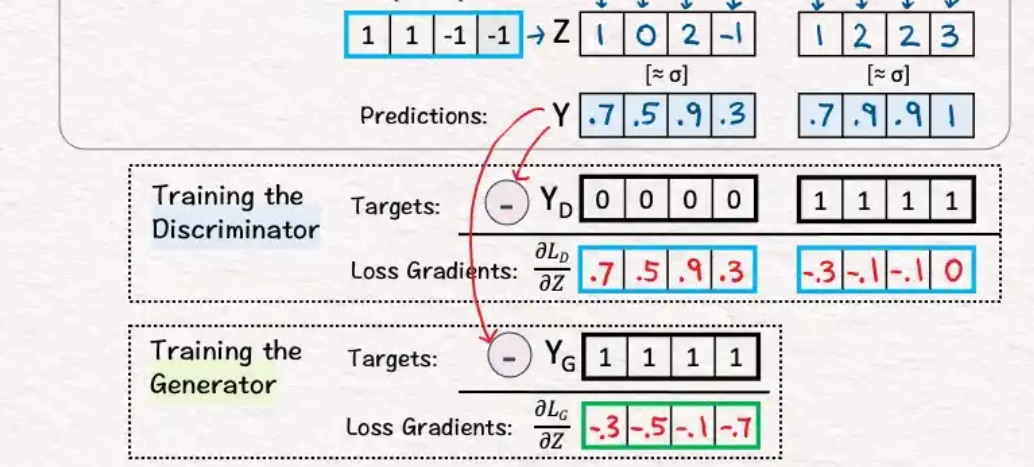
For perspective, here is the loss for Generative Adversarial Networks (GANs), which many of my students already consider very complicated. A GAN has:
two loss terms combined for the Generator, and
one loss for the Discriminator
So in total: about three moving pieces, like this:
For RLHF, there are close to 20 pieces you must somehow put together. Just to list a few:
policy loss (PPO clip)
value loss
policy KL (current vs previous)
reference KL (current vs SFT base)
reward model coupling
GAE advantage estimation
proximity model (θold)
reference model (θref)
importance sampling ratios
value targets from old model
sequence-level credit assignment
token-level advantage weighting
many more ….
Design
Prerequisites: This Blueprint is aimed at those of you who have already worked with RLHF in some capacity but want extra help connecting your technical experience to the underlying math. It is not designed as a first introduction to RLHF. If you’d like a high-level overview of RLHF before diving in, I recommend this excellent interview with Nathan Lambert, author of the RLHF book.
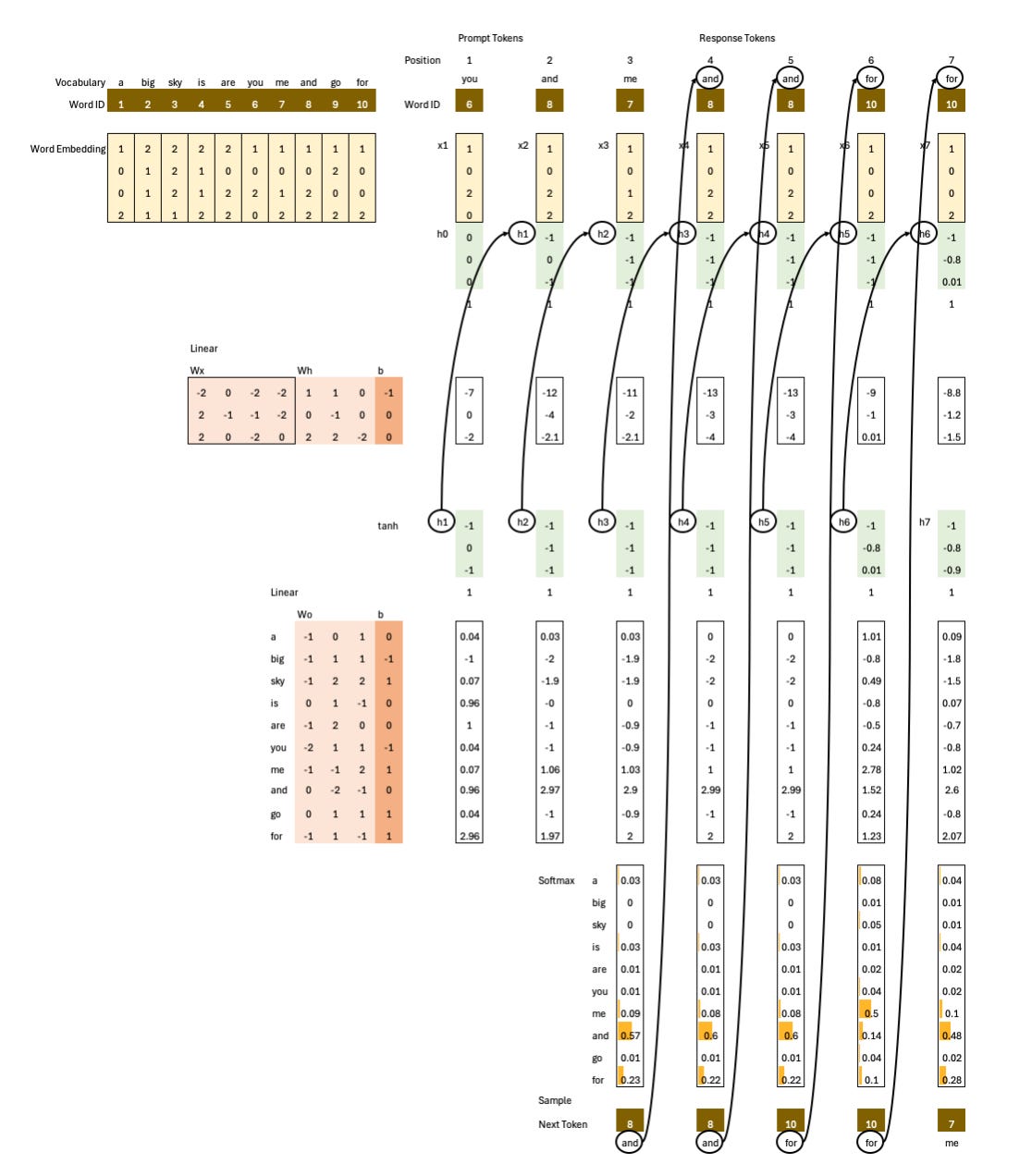
Language Model: I use an autoregressive RNN as the language model instead of a transformer stack so you can focus entirely on the RLHF component, which works the same way regardless of architecture. The RNN keeps the example simple and avoids unnecessary distraction.
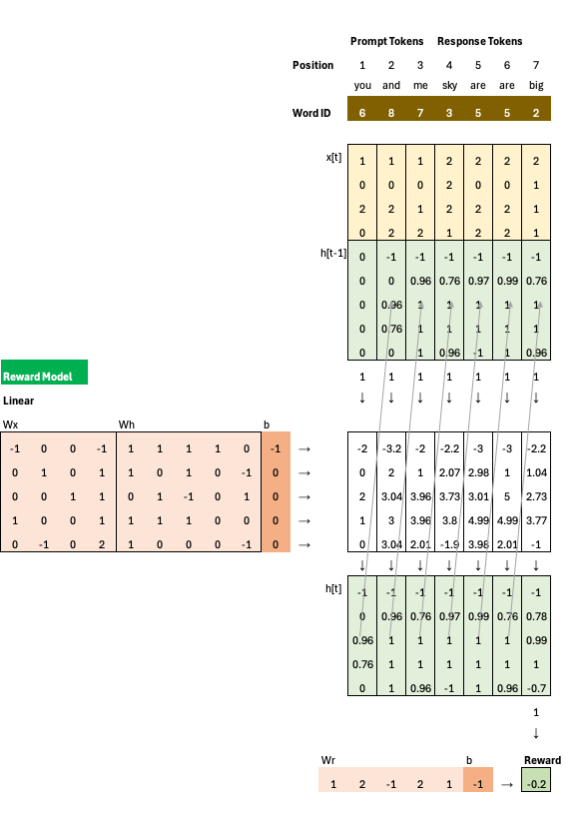
Reward Model: I started from the point after the reward model is already trained; I’ll create a separate Blueprint for reward-model training later.
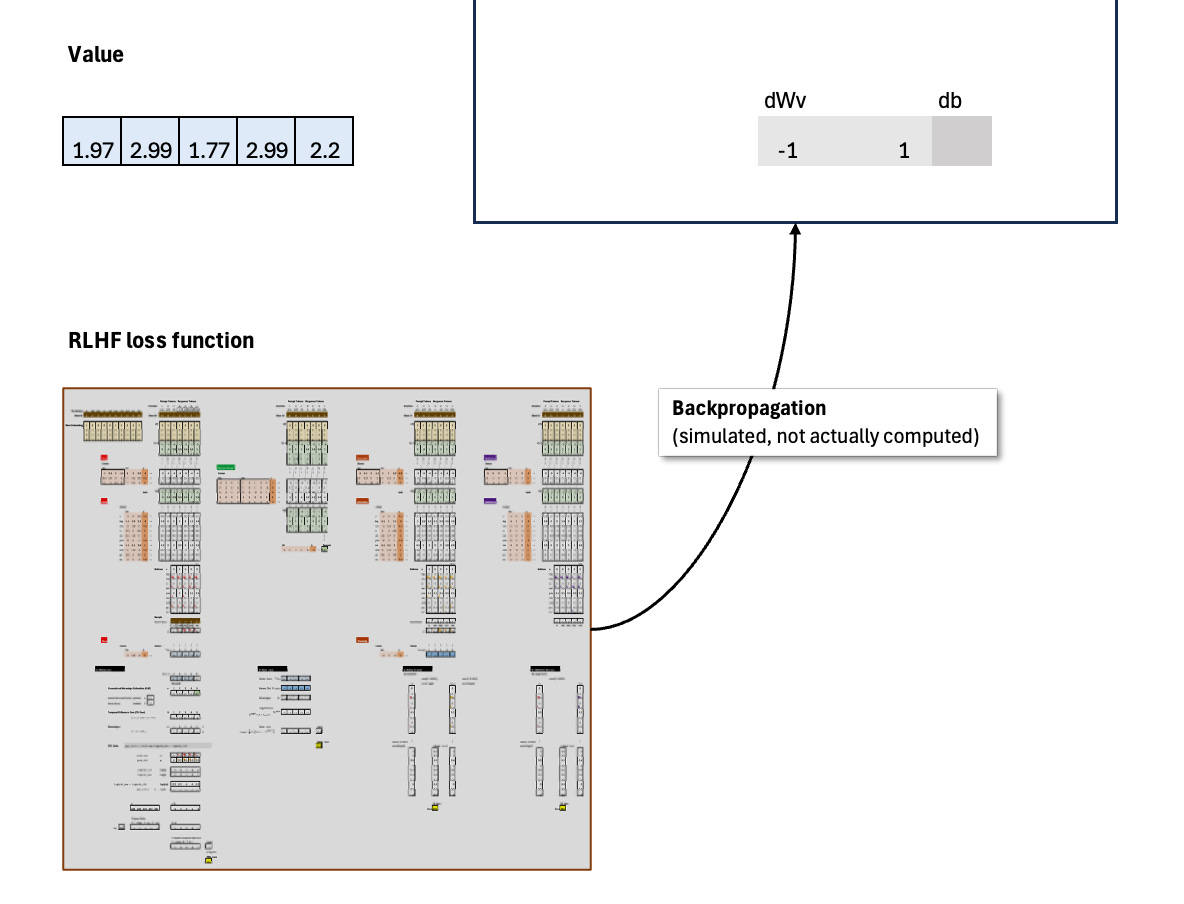
Policy Gradient: The loss function is fully implemented, but the policy-gradient update is simulated for clarity, since the goal is to break down this notoriously confusing loss function step by step. In other words, I didn’t implement backpropagation here.
Download
This Frontier AI Excel Blueprint is available to AI by Hand Academy members. You can become a member via a paid Substack subscription.