
RoPE vs PE in QKV Self-Attention
Frontier AI Drawings: 11 of 13

Library › Frontier AI Drawings
RoPE vs PE in QKV Self-Attention
")
Yesterday, DeepSeek released version 3.2, formally introducing DSA (DeepSeek Sparse Attention) and releasing both the Python reference implementation and open pre-trained weights. I’ve been busy building an Excel reference implementation to help a partner company grasp the math behind DSA and begin constructing its own version.
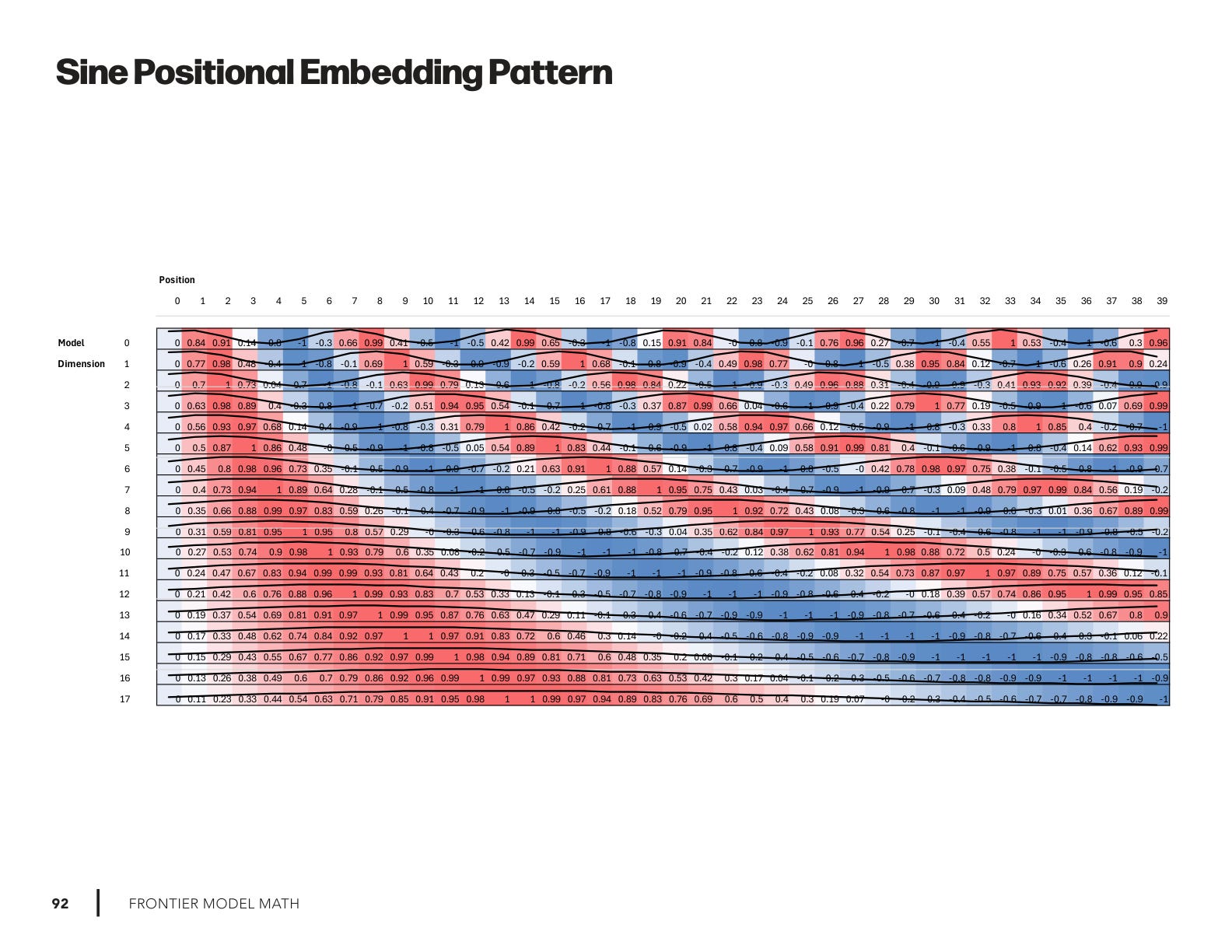
For this week’s issue, I intend to focus on RoPE (Rotary Positional Embedding). The timing of DeepSeek’s 3.2 is perfect. It reinforces why understanding RoPE is no longer optional. RoPE has quickly become a de facto standard in modern transformer architectures since it was published in April 2021, and its influence is only growing.
Drawings
I created four new sets of drawings to illustrate the following:
Sine & Cosine Positional Encoding Patterns
Positional Encoding (PE) vs. Rotary Positional Embedding (RoPE)
QKV Self-Attention + Positional Encoding (PE)
QKV Self-Attention + Rotary Positional Embedding (RoPE)
Once I finish explaining RoPE, only a few more building blocks remain, like RMSNorm and SwiGLU, before I’ll have unpacked all the key pieces needed to do a full architecture breakdown. My plan is to work toward a complete Qwen3 breakdown in the coming weeks.

Page 1 of 10
Become a member to access the rest of the drawings.