
Self Attention Flow ~ New Release!

Building upon Matmul Flow I released two weeks ago, I’d like to share with you Self-Attention Flow — my attempt to turn the self-attention diagram I’ve drawn by hand ✍️over a hundred times in class into an interactive tool you can explore yourself.
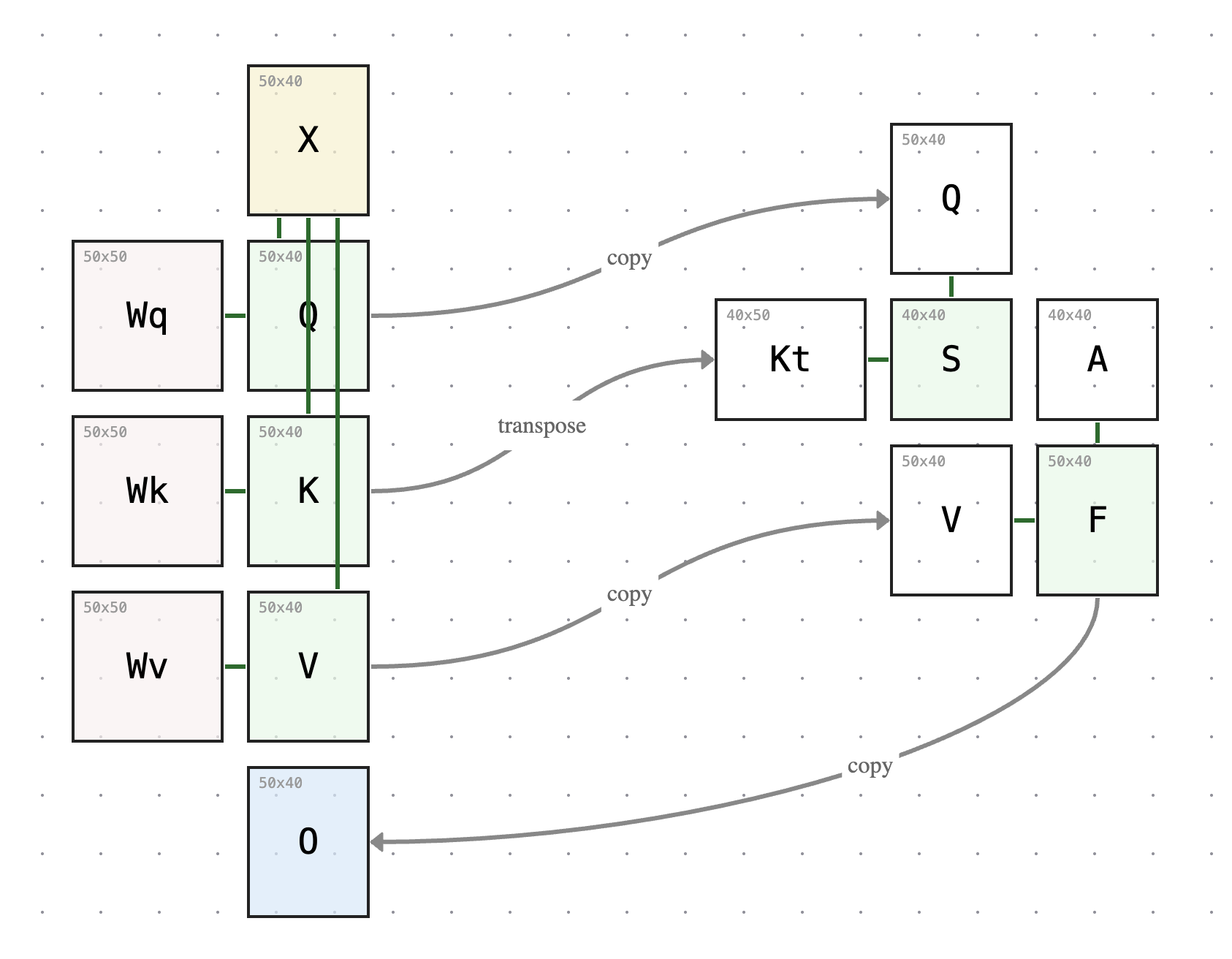
Self-attention is the core mechanism behind Transformers, yet it’s almost always explained through equations and code. What gets lost is the spatial relationship between matrices — how dimensions propagate, why certain shapes must match. You can’t see that Q and K must be the same size but V doesn’t have to be, or that the score matrix S and attention matrix A are always square, just by reading S = softmax(Kᵀ Q / √d).
Think you already know self-attention inside and out and don’t need this tool? Here are three questions to test your knowledge:
Does increasing the model size (X’s height) change the shape of the score matrix S?
Does increasing the sequence length (X’s width) change the size of Wq, Wk, or Wv?
Does increasing the key dimension (K’s height) change the size of the attention matrix S = QKᵀ?
Use the sliders to change these values and observe what happens before you read the answer key below.
[space intentionally left blank so you don’t read the answers right away]
Answers:
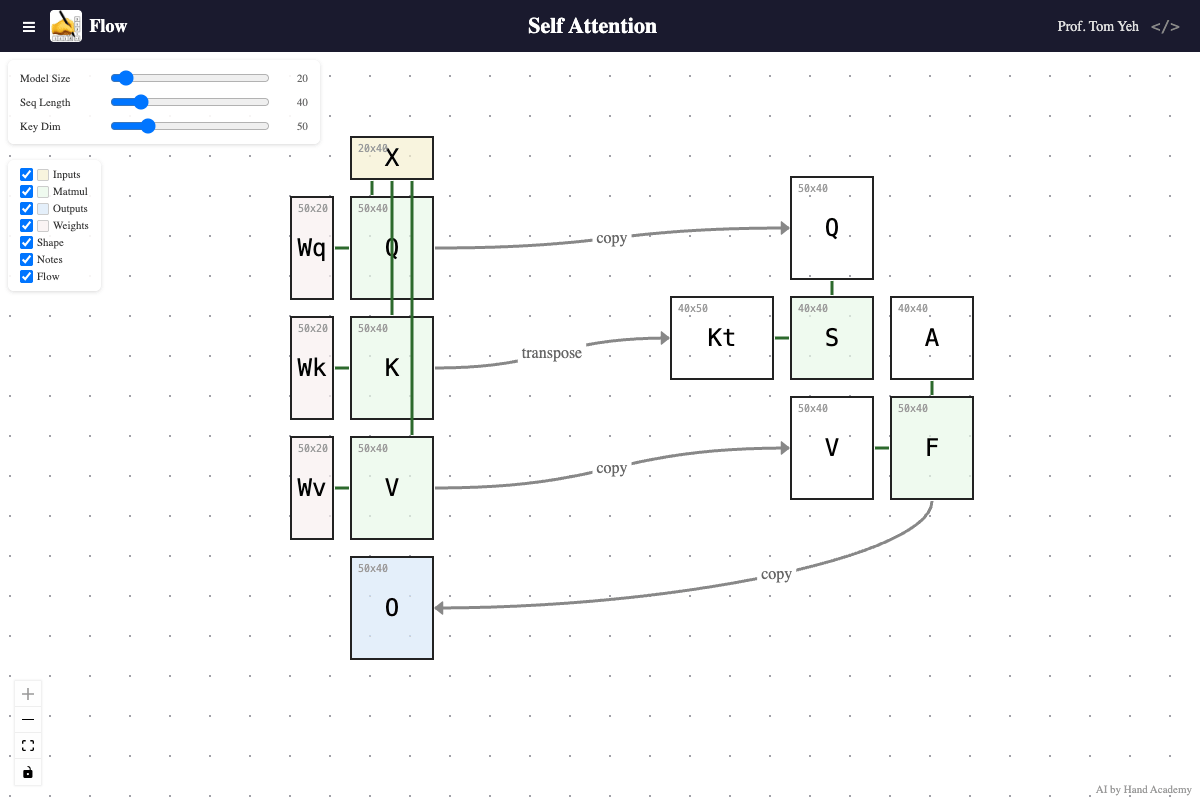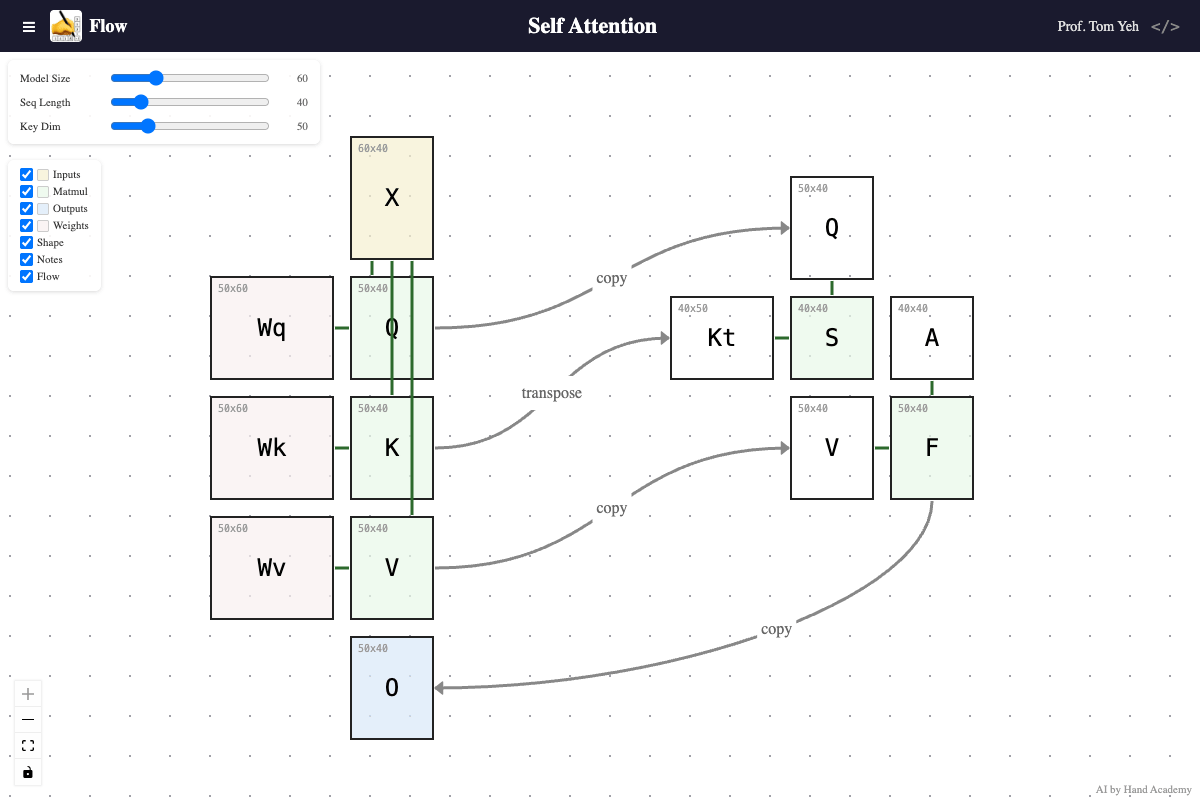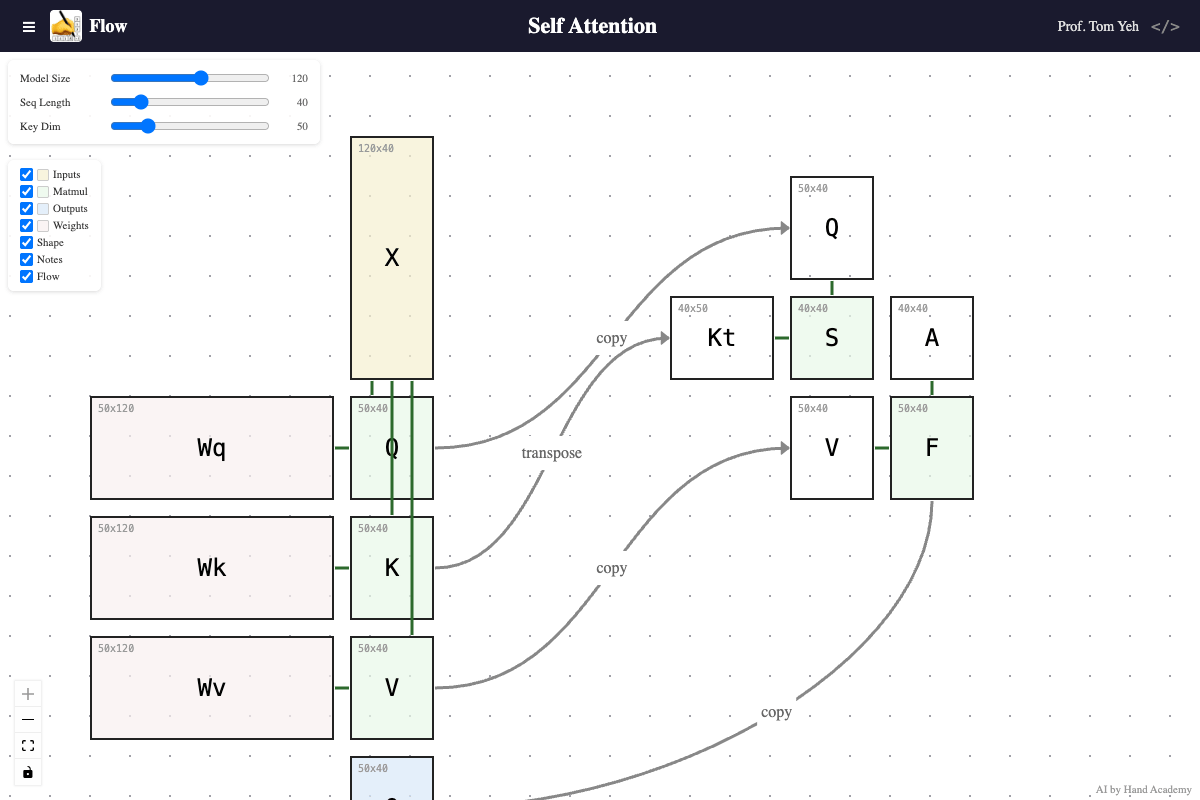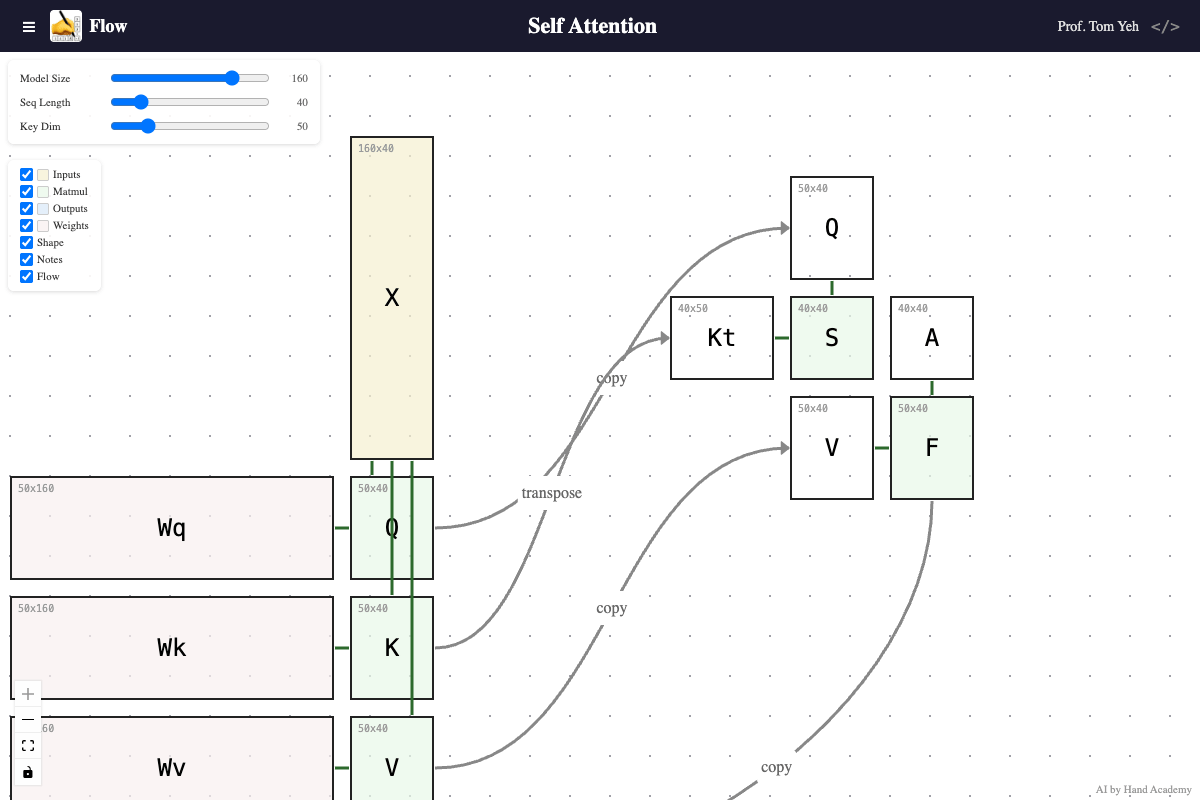
Model Size
Q: Does increasing the model size (X’s height) change the shape of the score matrix S?
A: No. Drag the Model Size slider and watch: X gets taller, the weight matrices Wq, Wk, Wv grow wider — but S stays exactly the same size. The score matrix S is always sequence length × sequence length, regardless of model size. Model size controls how many features each token carries, but the attention pattern — which tokens attend to which — is purely determined by sequence length and key dimension. You can see nothing in the right side is changing.
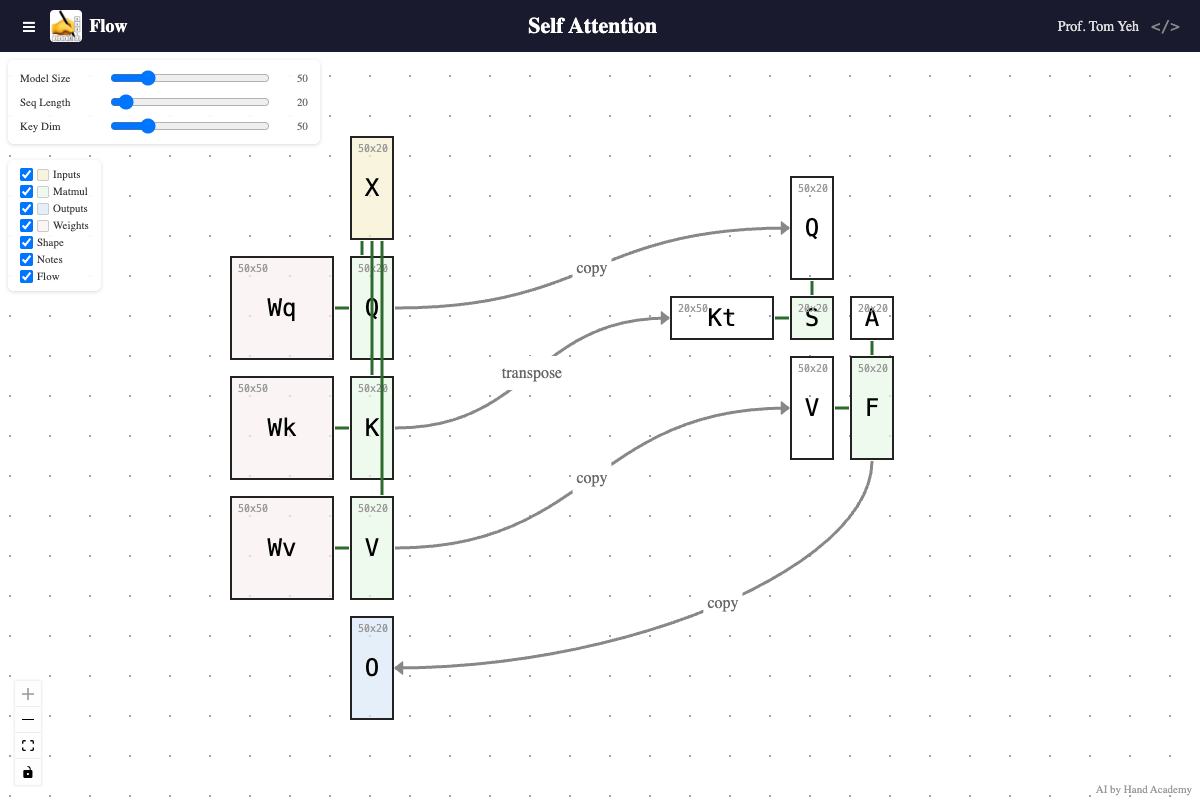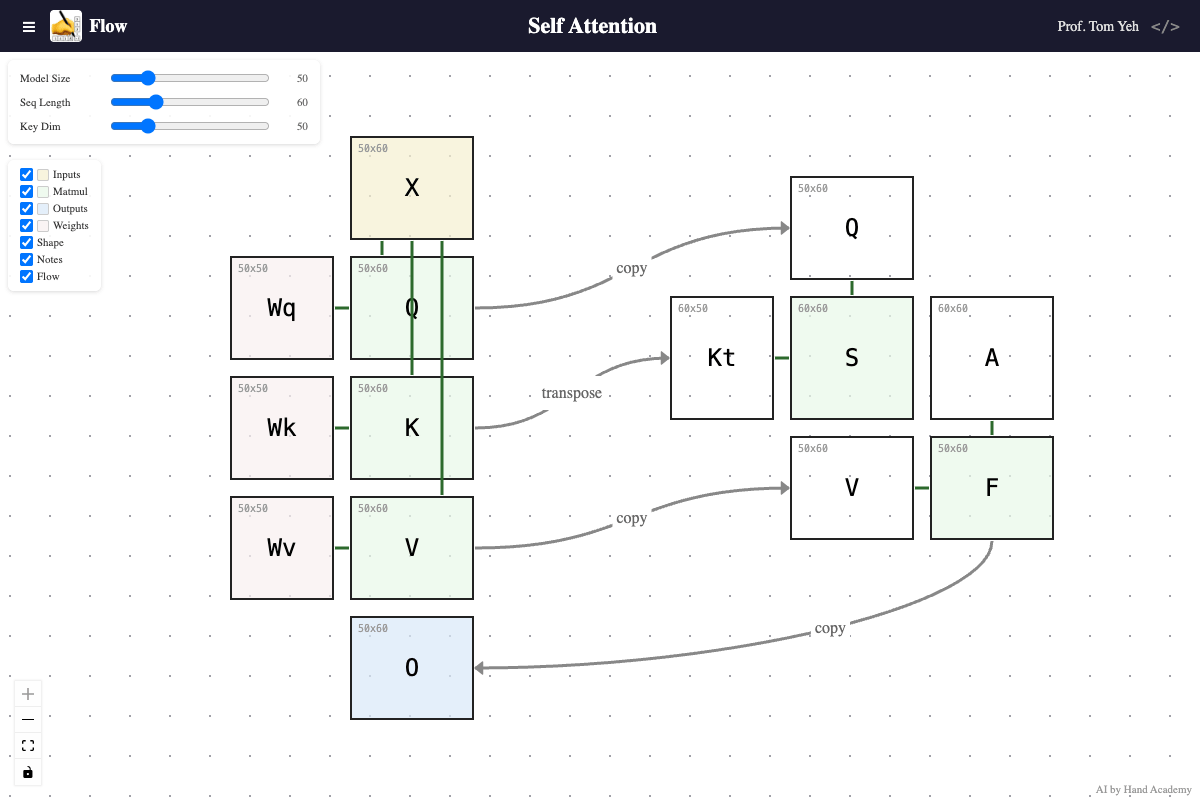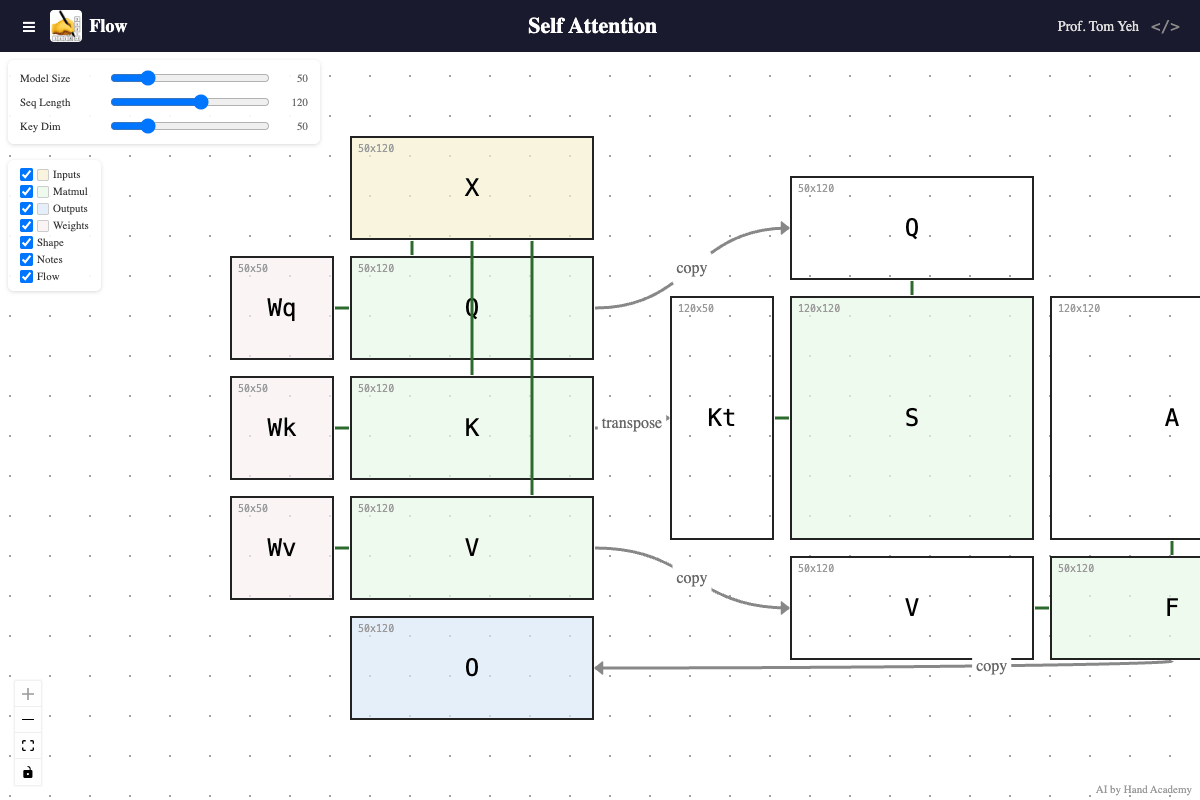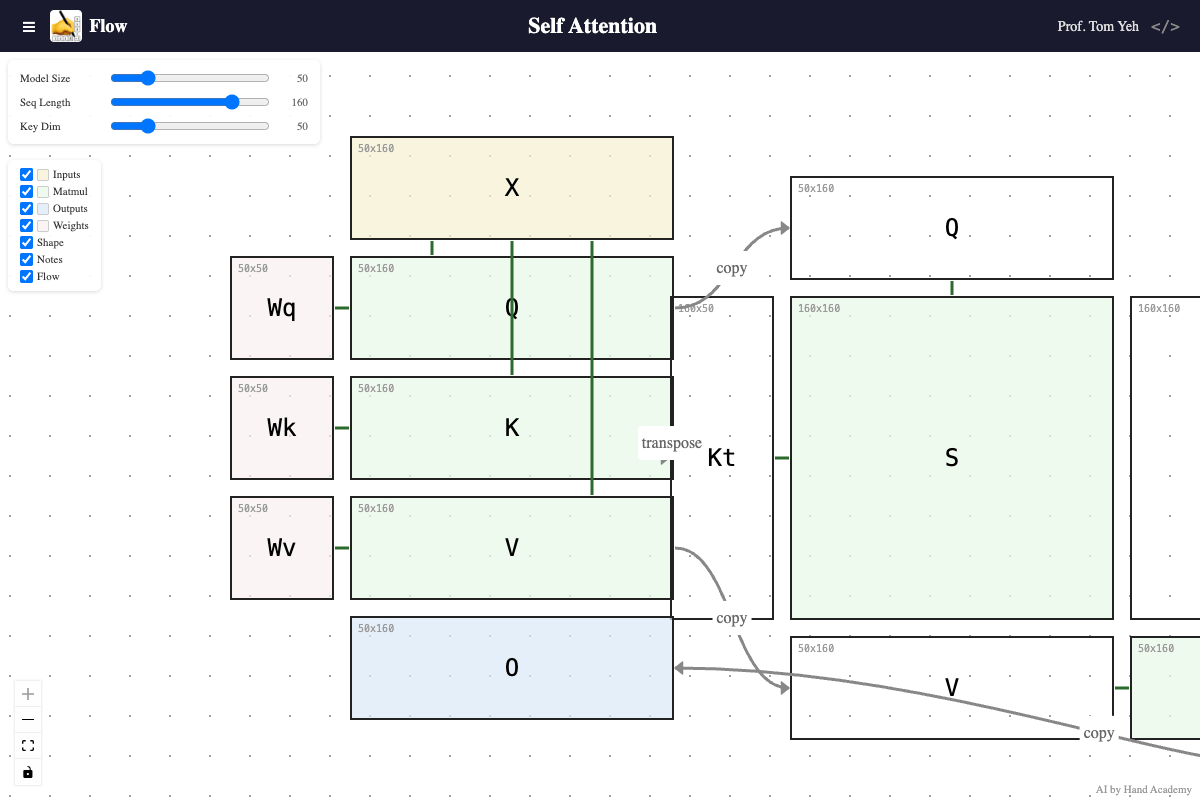
Sequence length
Q: Does increasing the sequence length (X’s width) change the size of Wq, Wk, or Wv?
A: No. Increasing sequence length does not change any weight matrix. The number of trainable parameters stays the same. That’s why when you hear a model increases its context length from 5K to 5M, the “size” of the model does not change. However, the time to compute the attention matrices (S and A) grows quadratically with sequence length.
Key Dimension
Q: Does increasing the key dimension (K’s height) change the size of the attention matrix S = QKᵀ?
A: No. As you increase the key dimension, query and key vectors grow longer, but the attention score matrix (S) and attention weight matrix (A) do not change size. The attention matrix is always sequence length x sequence length regardless of key dimension. However, each value in it — a dot product — takes more to compute, because the key and query vectors are longer.
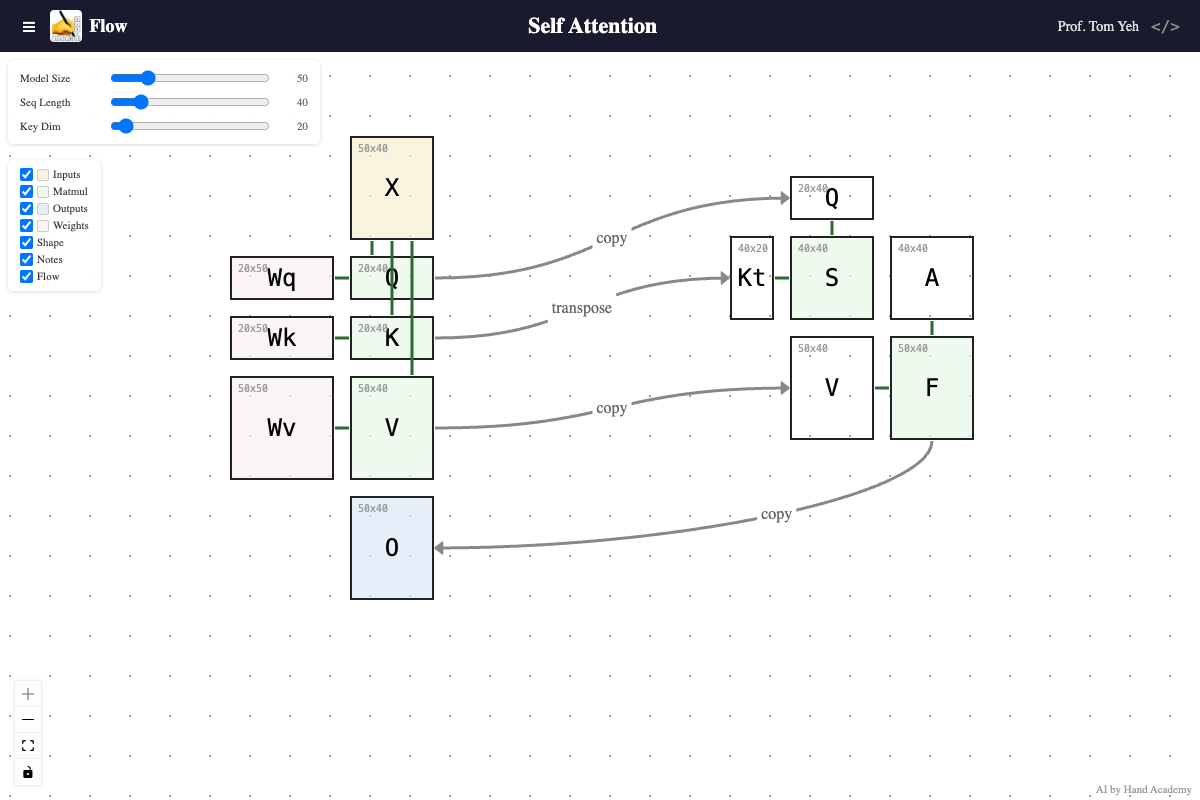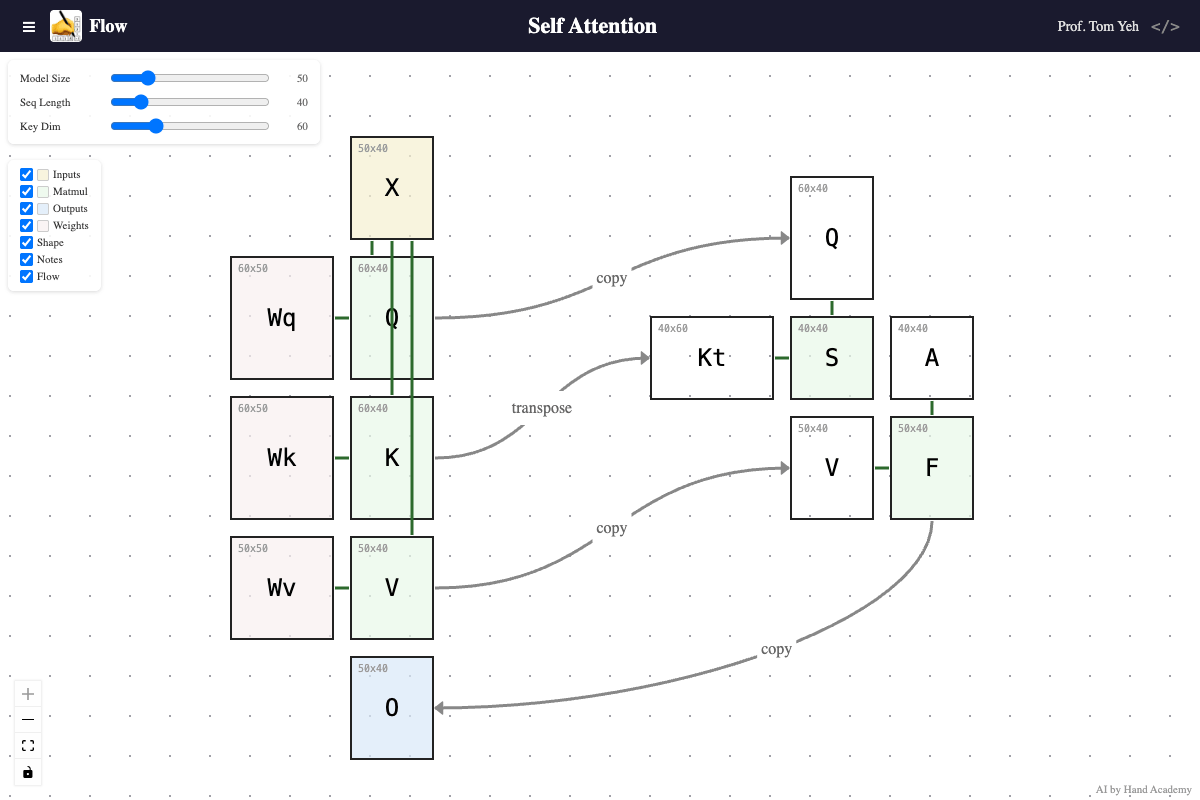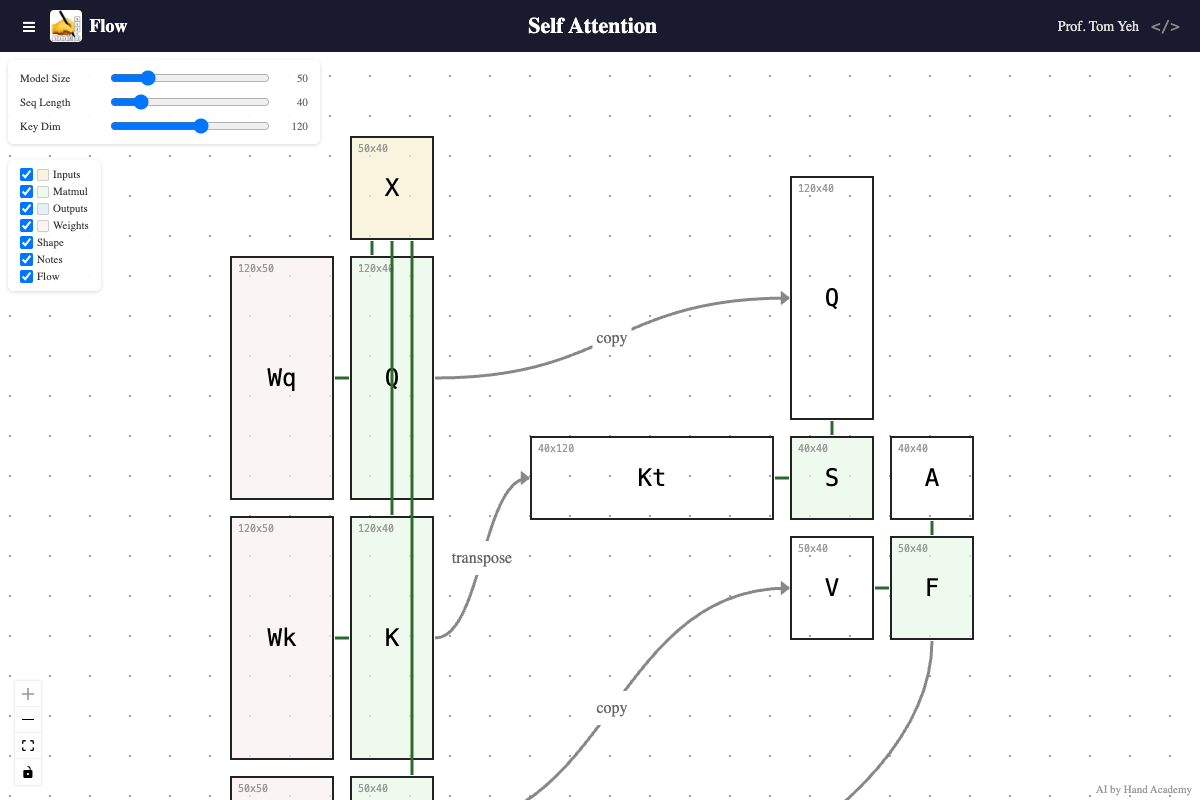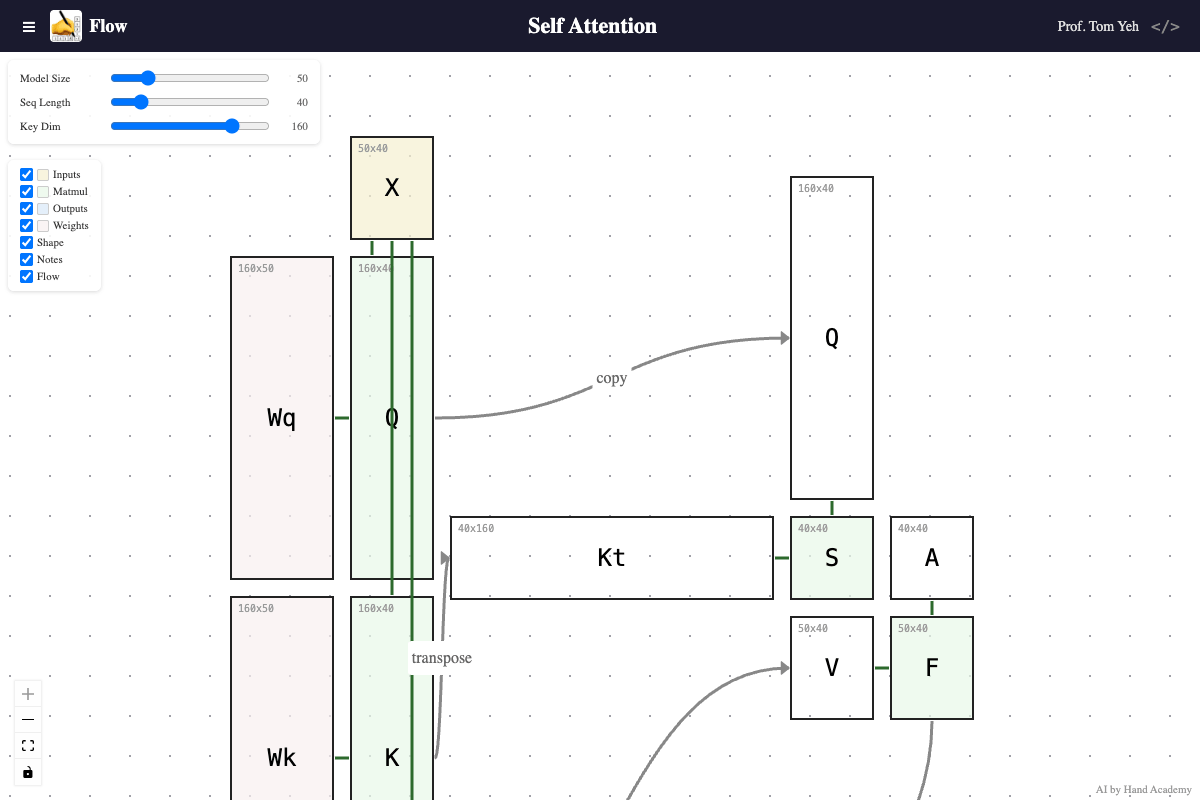
Give Self Attention Flow a try. Resize any matrix in the diagram and watch the dimensions “flow” to other matrices in the self-attention mechanism.
You know the memory continuity issues then. CoPilot maintains continuity between its sessions better than most.
The AIs also like to tell you how they work.
They tend to get stuck in themes so i’m learning to ask questions around that.
Matmul Flow is easy to use and help me understand a difficult concept quickly.
I’ll appreciate more work from you