
SVM, Self Attention, Linear Layer, Workbook Videos

1. SVM
by Tom Yeh
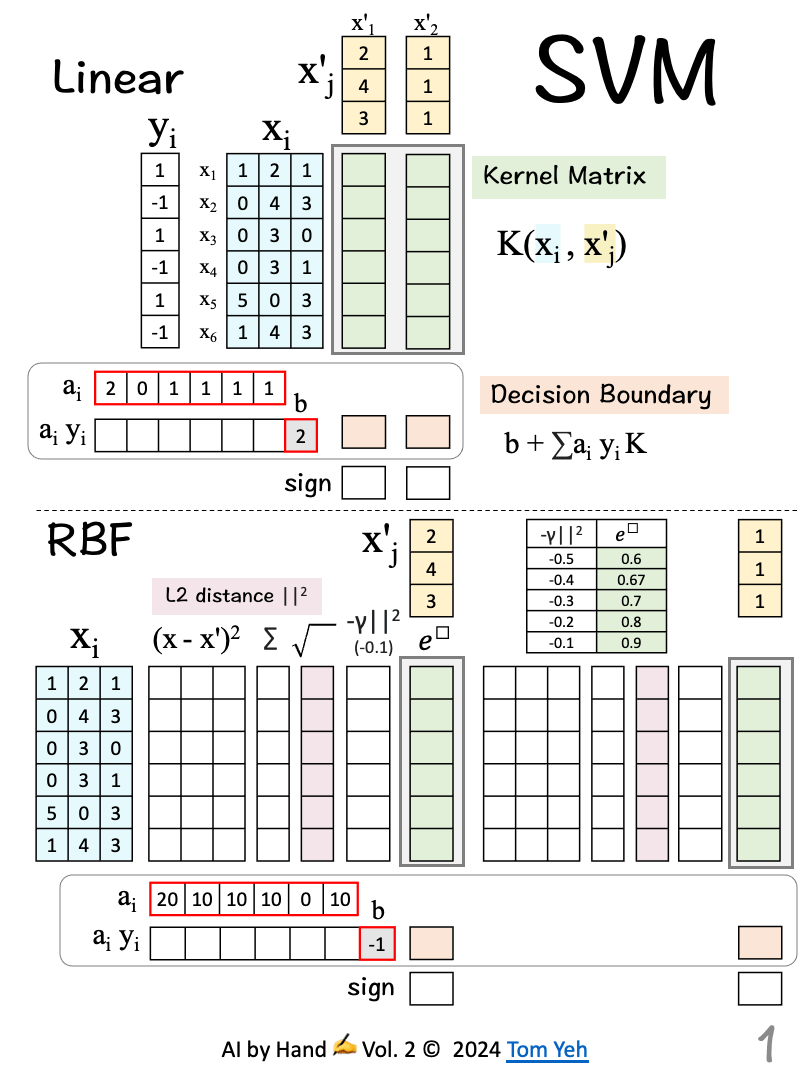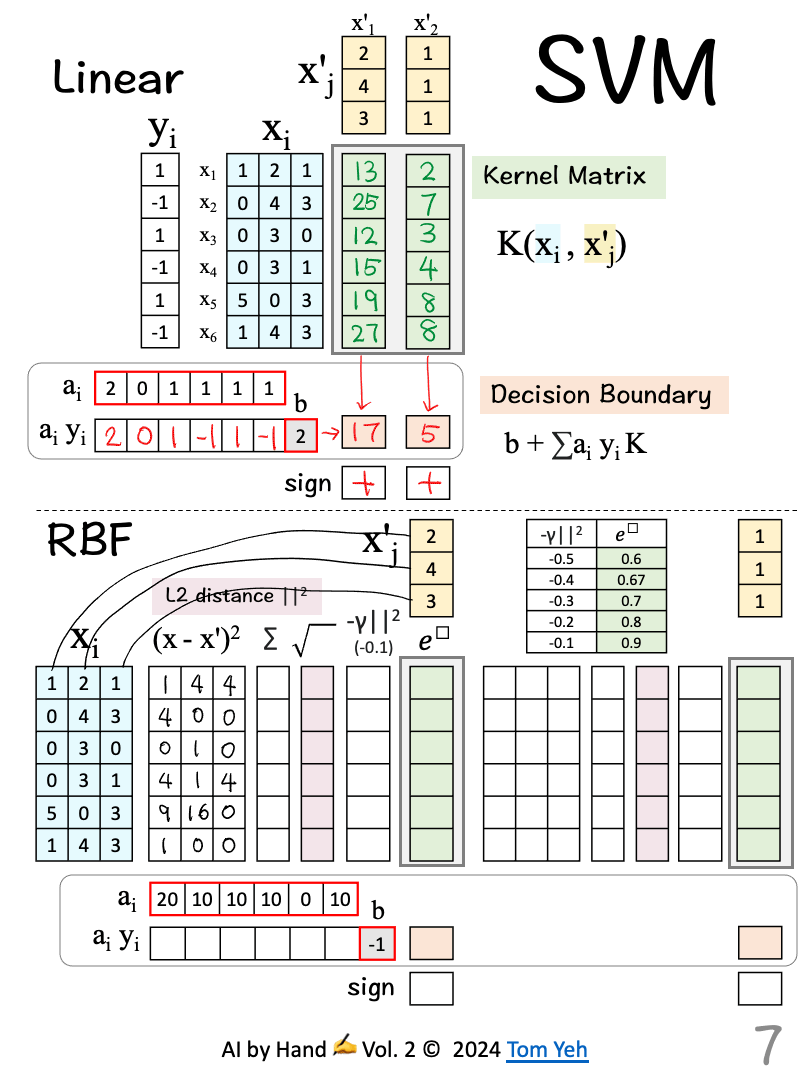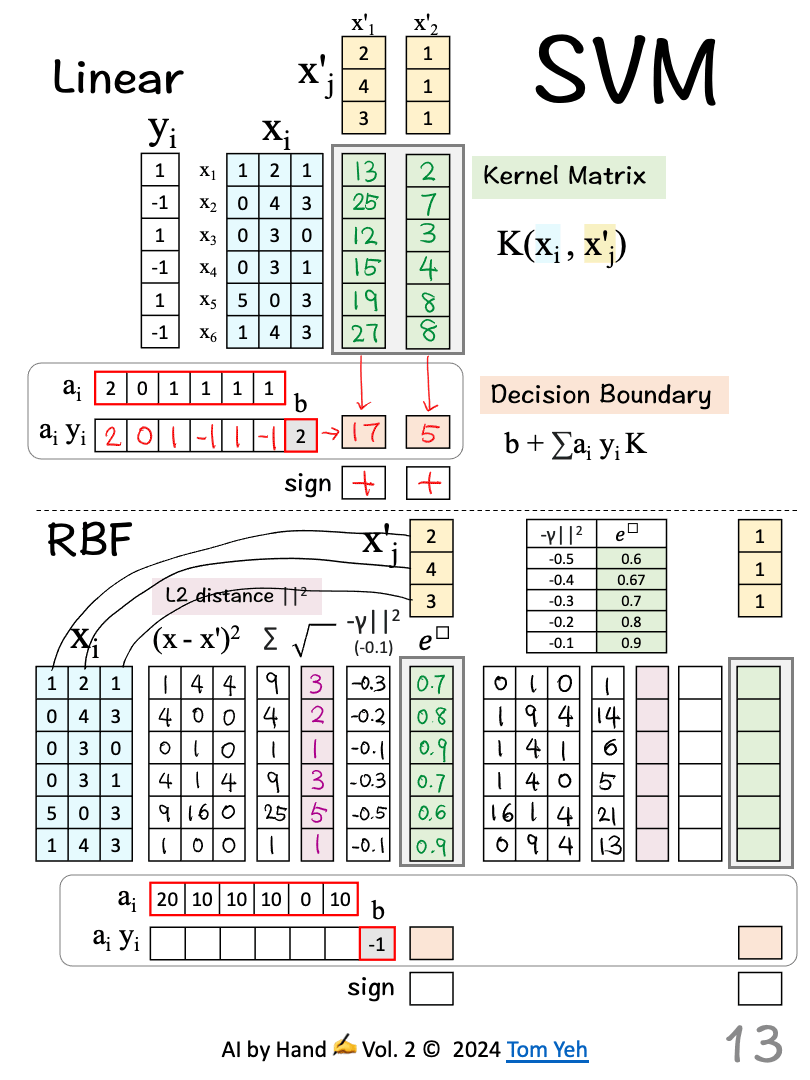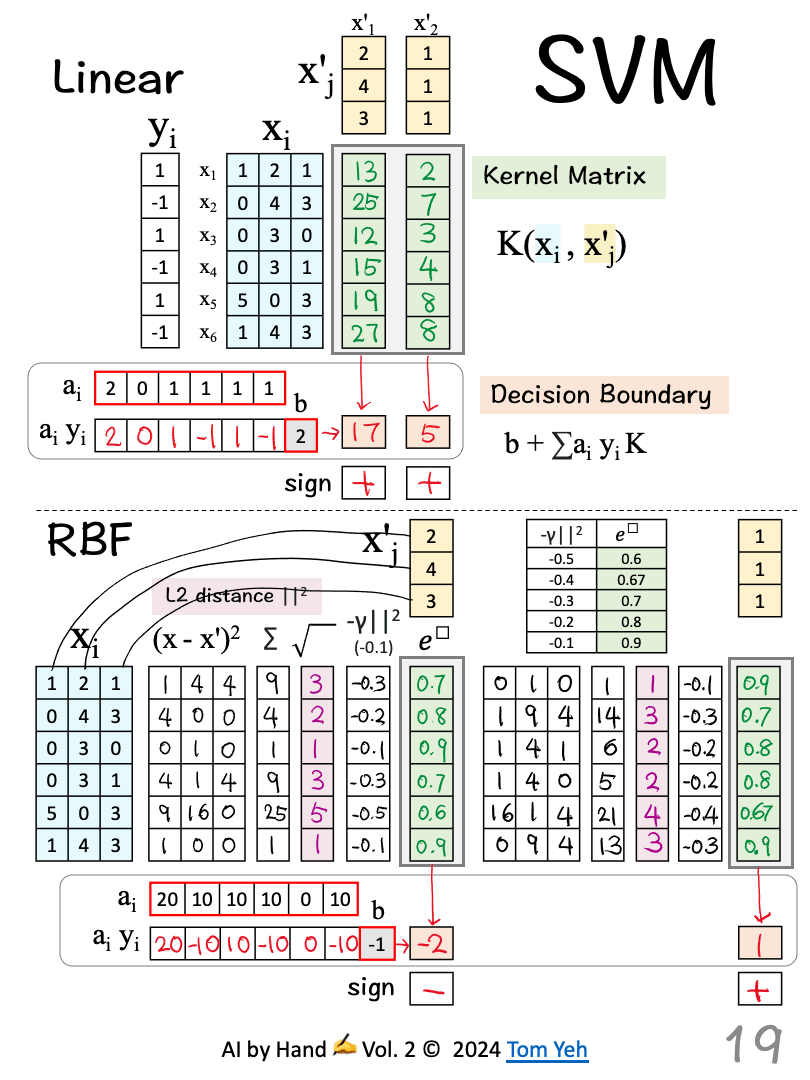
Support Vector Machines (SVMs) reigned supreme in machine learning before the ascendancy of the deep learning revolution.
How do SVMs work?
This exercise compares Linear vs RBF SVMs in terms of how they classify test vectors, assuming the SVMs are already trained.
See the original LinkedIn post (1,213 Likes):
https://www.linkedin.com/feed/update/urn:li:ugcPost:7175504806239719425/
Download:
2. Self Attention
Deep Dive into Self Attention by Hand ✍️
by Srijanie Dey

Attention! Attention!
Because ‘Attention is All You Need’.
No, I am not saying that, the Transformer is.
As of today, the world has been swept over by the power of transformers. Not the likes of ‘Robtimus Prime’ but the ones that constitute neural networks. And that power is because of the concept of ‘attention’. So, what does attention in the context of transformers really mean?
Read the full article: https://towardsdatascience.com/deep-dive-into-self-attention-by-hand-%EF%B8%8E-f02876e49857
3. Linear Layer
Workbook: 25 Exercises 🏋️
by Tom Yeh

Download the workbook:
4. Workbook Videos

