
GLU
Activation series: 11 of 12

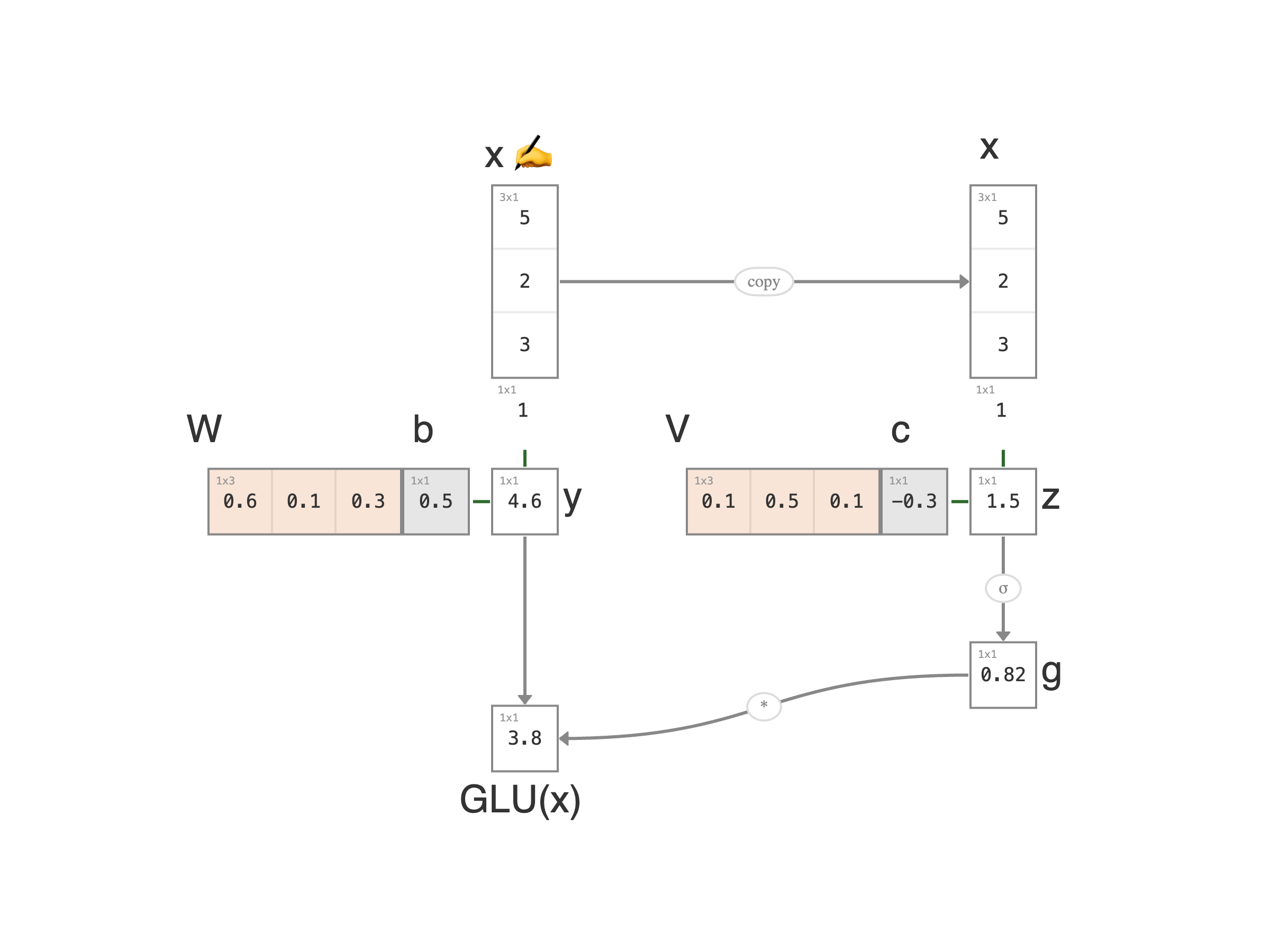
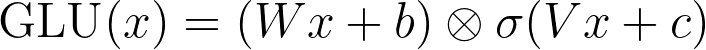
GLU is the first activation in this chapter where the network decides about a value rather than only shaping it. The same input is run through two learned linear transforms (one produces a value, the other produces a 0..1 mask), then multiplied elementwise.
Paid members: open the interactive diagram below ↓