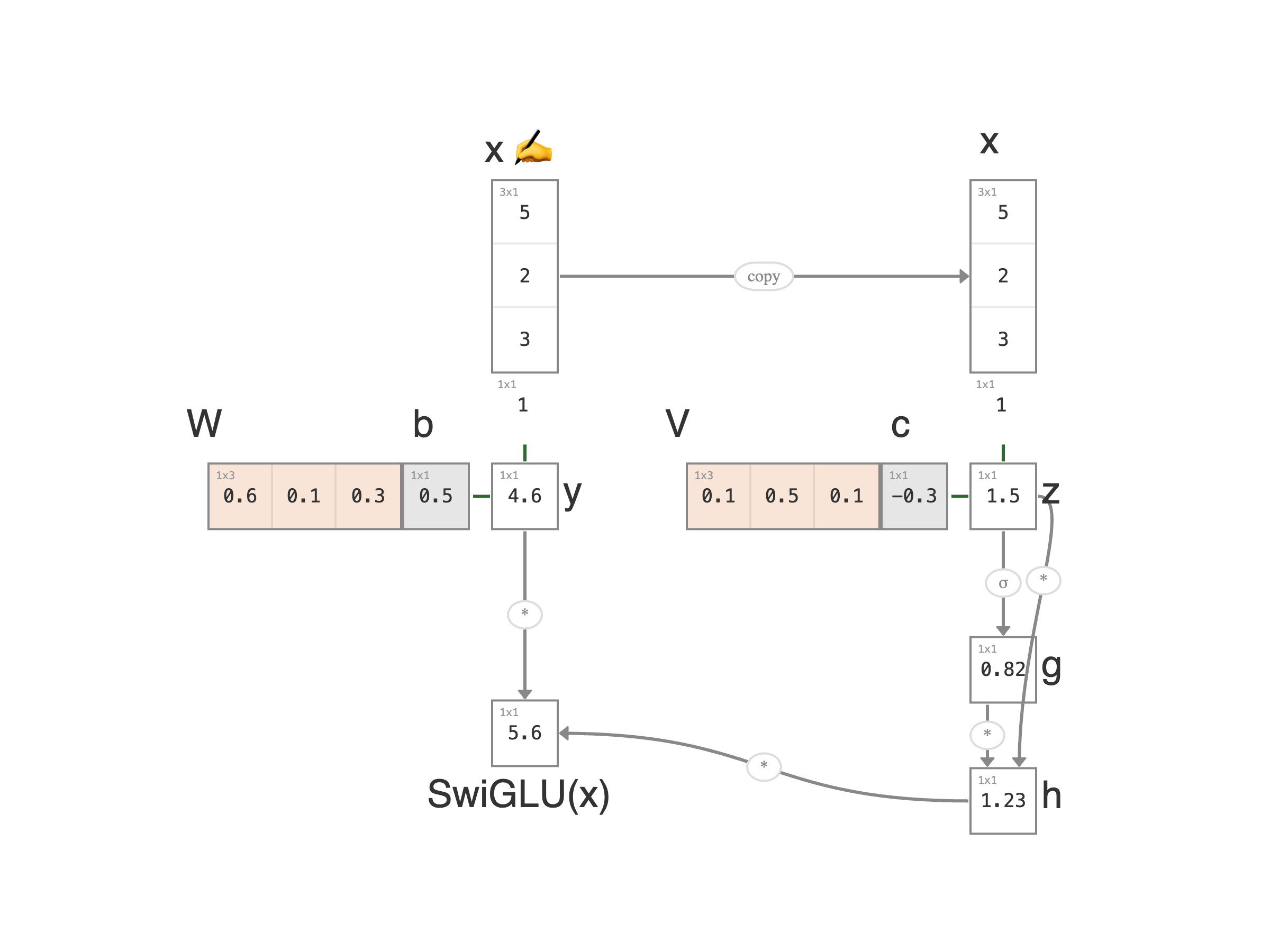
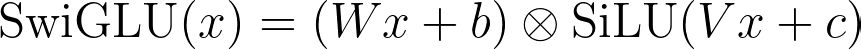SwiGLU is GLU with the sigmoid gate replaced by a SiLU gate. The two-branch shape is identical; the only change is that the gate is no longer capped at 1 — it can push past full rated capacity into overdrive.
Paid members: open the interactive diagram below ↓