
ReLU
Activation series: 4 of 12


ReLU is the default activation in modern deep learning: cheap to compute, and stable enough to train networks hundreds of layers deep.
The Fate of Five Boba Shops (1 of 5)
In Taiwan, it feels like every day brings a new boba shop opening, and an old one quietly closing its doors. ReLU is the brutal arithmetic behind that turnover.
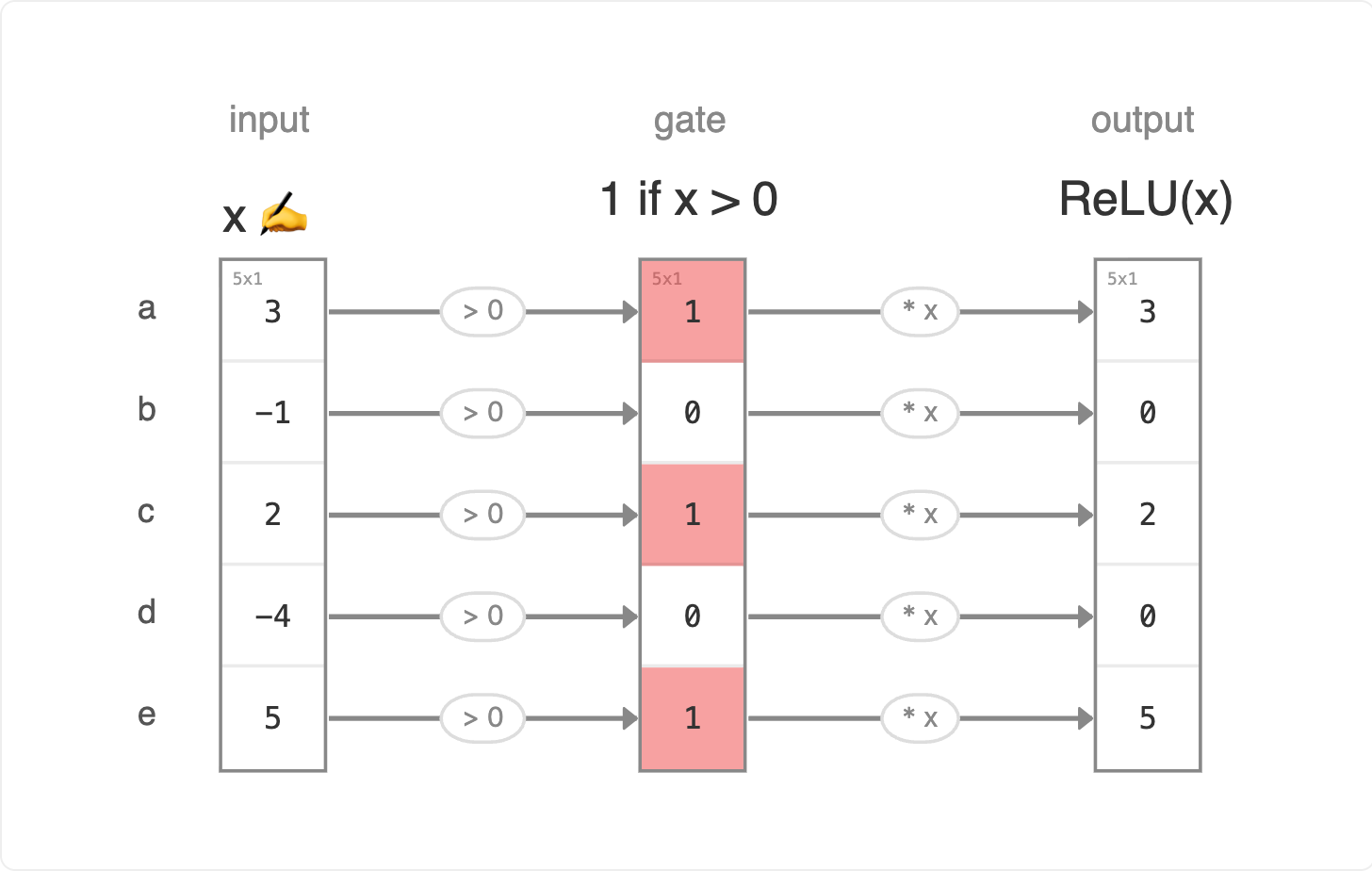
Picture five boba tea shops on the same block (a, b, c, d, e), each closing the books on the month.
Each value is a shop's monthly profit, in thousands: a 3 is a 3K month in the black, a -1 is 1K in the red. Receipts minus rent, ingredients, and wages. When profit is positive, the shop stays open and the owner keeps every K. When profit turns negative, the shop runs out of cash and shutters — the lights go off, the books are wiped to zero. ReLU is exactly that rule, applied one shop at a time.
Walking through the Math
Input: each shop's profit x at month's end.
Gate: 1 if x > 0 (shop is open), 0 if x ≤ 0 (shop has shuttered).
Output: x multiplied by the gate. Open shops pass their profit through untouched; shuttered ones are zeroed out.
Five rows means five parallel shops on the same block, each evaluated independently. ReLU is element-wise: every neuron decides its own fate.
Reading the Numbers
What does the harsh ledger do to a shop at each profit level?

ReLU is a binary verdict: above zero, you keep what you earn; at or below zero, the books are zeroed out. No in-between, no second chances!
Next:
5. Leaky ReLU