
Sigmoid
Activation series: 2 of 12


Sigmoid squashes any real number into a probability between 0 and 1: the classic activation for binary classification, and still the gating function inside LSTMs and GRUs.
QQ Activation (2 of 3)
When a new boba shop opens, I'd go try it. After the first cup, the question hits: what's the chance I'll come back? It depends on how the new shop stacks up against my baseline: the average shop back in Taiwan, chewiness zero on my QQ scale.
Now imagine you're in the same spot. You try a new shop and mentally apply the same QQ scale, giving the new place a score x, with your baseline (whatever you've calibrated to) sitting at chewiness zero. What's the chance you'll come back?
Sigmoid turns that single x into a probability between 0 and 1: the chance the new place earns a return visit. It's softmax narrowed to just two options: the new shop on one side, the average of everyone else on the other.
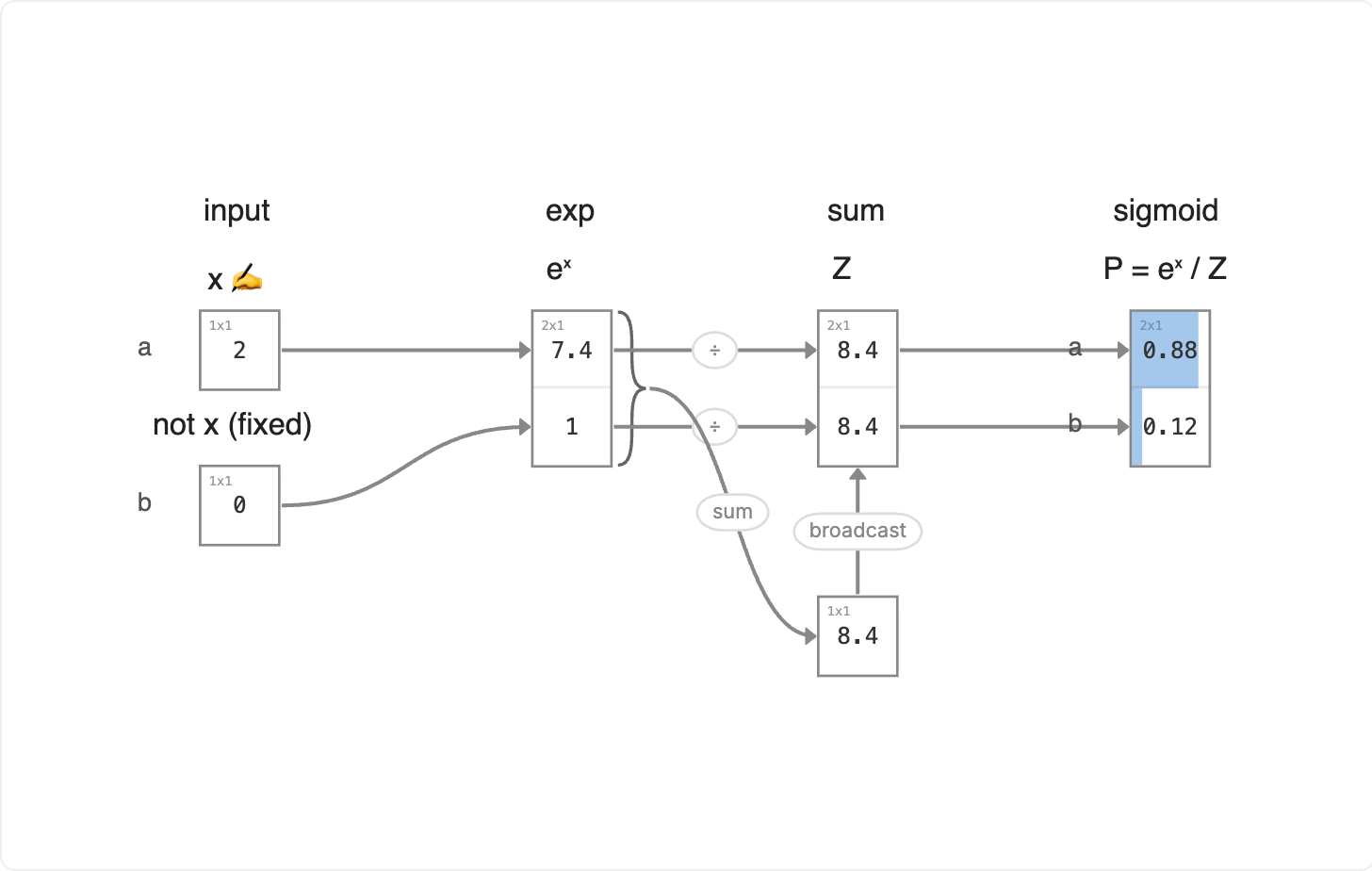
Walking through the Math
Input: the new shop's chewiness x and the fixed baseline 0 for the usual.
Exp: exponentiate both, eˣ and e⁰ = 1.
Sum: total Z = eˣ + 1.
Sigmoid: probability P = eˣ / Z for the new shop, 1 − P for the usual.
The two probabilities add up to one. The new shop earns a higher chance of your next visit when its pearls get chewier; your usual keeps the rest. Sigmoid turns one chewiness score into a clean 0-to-1 odds of trying the new place.
Reading the Numbers
What does sigmoid forecast across the QQ scale?

Notice sigmoid never says "definitely yes" or "definitely no" — even at chewiness +3, there's a 5% chance you don't return (you got busy, the shop closed early). And even at chewiness -3, there's a 5% chance you do (you happened to be in the area). That bounded honesty is sigmoid's signature.
Diving into Equations
Sigmoid is just softmax with two players, one of them pinned to zero. Apply softmax to the pair [x, 0], and the probability for a is:

Since e⁰ = 1, this simplifies:

Multiply top and bottom by e⁻ˣ to get the canonical form:

That's sigmoid.
Next:
3. Tanh