
Softmax
Activation series: 1 of 12


Softmax is how deep networks turn raw scores into a probability distribution: the final layer of every classifier, and the core of every attention head in a transformer.
QQ Activation (1 of 3)
QQ matters to us Taiwanese: that hard-to-translate texture of perfect chewy tapioca, the heartbeat of any decent boba. So I developed a 7-point chewiness scale to capture it:

Now imagine you just won 100 boba coupons in a Taiwan promotion, each good for one drink at any of five top chains on the block. A reviewer has rated each shop (a through e) on this scale.
How do you spend the 100 coupons across the five shops? You could blow them all at the chewiest one, but that wastes the variety, and you've got 100 visits to plan. Softmax is the smooth alternative: the chewiest shop earns the biggest share, the runners-up get smaller cuts, and even the mushy disaster gets a stray coupon or two.
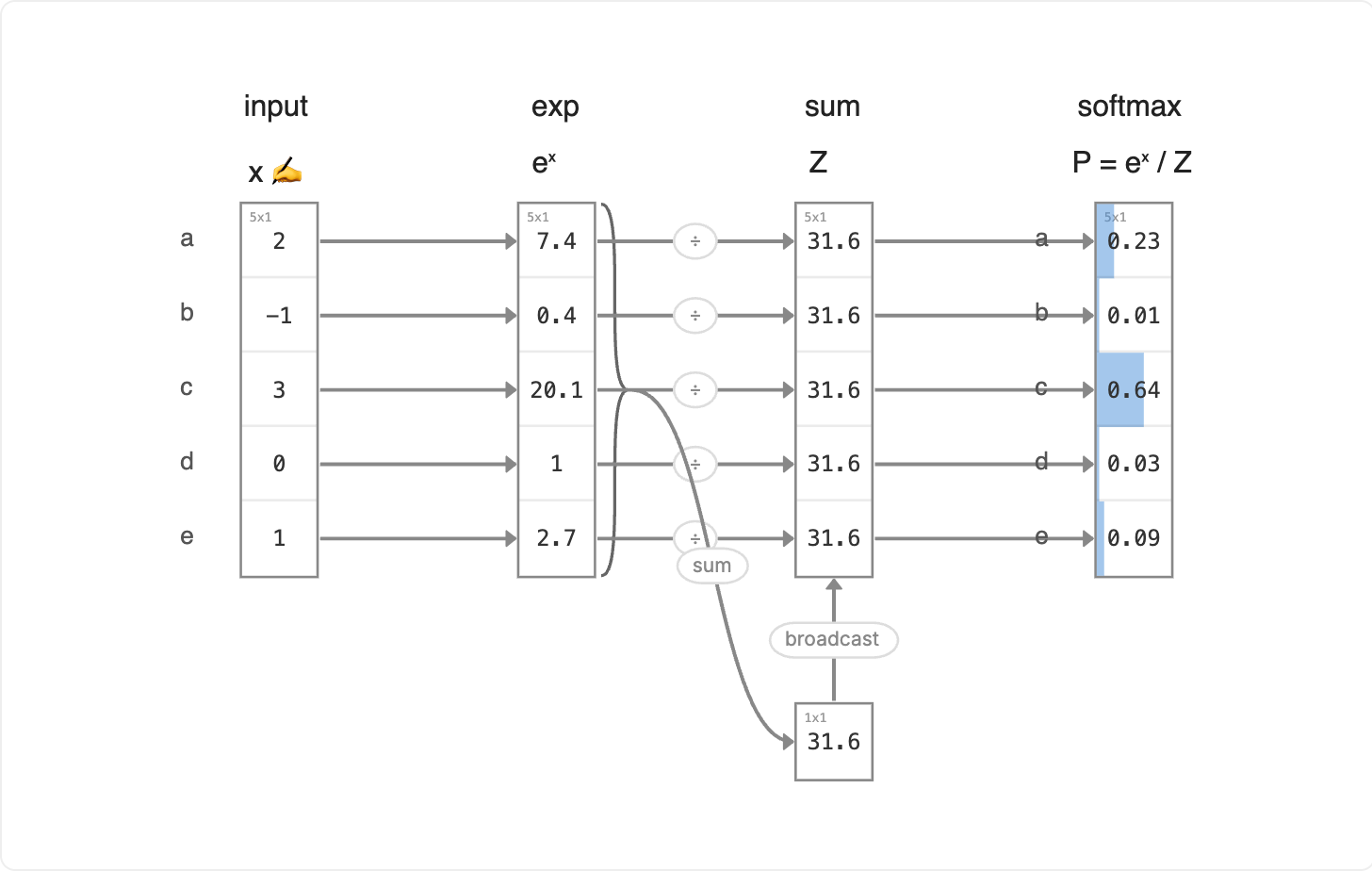
Walking through the Math
Input: each shop's chewiness score x.
Exp: exponentiate, eˣ, turning negative chewiness into small positives and stretching gaps exponentially.
Sum: total Z = Σ eˣ.
Softmax: share P = eˣ / Z, the fraction of your 100 coupons that goes to each shop.
The five shares add up to one, so you can read them as percentages of your 100 coupons. The chewiest shop gets the biggest slice, but never the whole stash. Softmax ranks confidently while still leaving room for the others.
Reading the Numbers
How does softmax split the 100 coupons among the five shops?

Shop c (+3) wins 64 of the 100 coupons. Notice every adjacent score gap multiplies the share by about 2.72 (= e¹): c (+3) earns 64, a (+2) earns 23, e (+1) earns 9, d (0) earns 3, b (-1) earns 1. Small score gaps become big coupon swings — that's the "exp" in softmax doing its work.
Diving into Equations
The five shares always sum to one, no matter what the chewiness scores are. Sum the formula across all shops:

The denominator is the same for every term, so pull it out front:

The remaining sum in the numerator is exactly the denominator:

That's why your 100 coupons always split into exactly 100, no matter what the reviewer hands you. Softmax conserves the budget by construction.
Next:
2. Sigmoid