
Linear Probe
Fine-Tuning series: 5 of 8

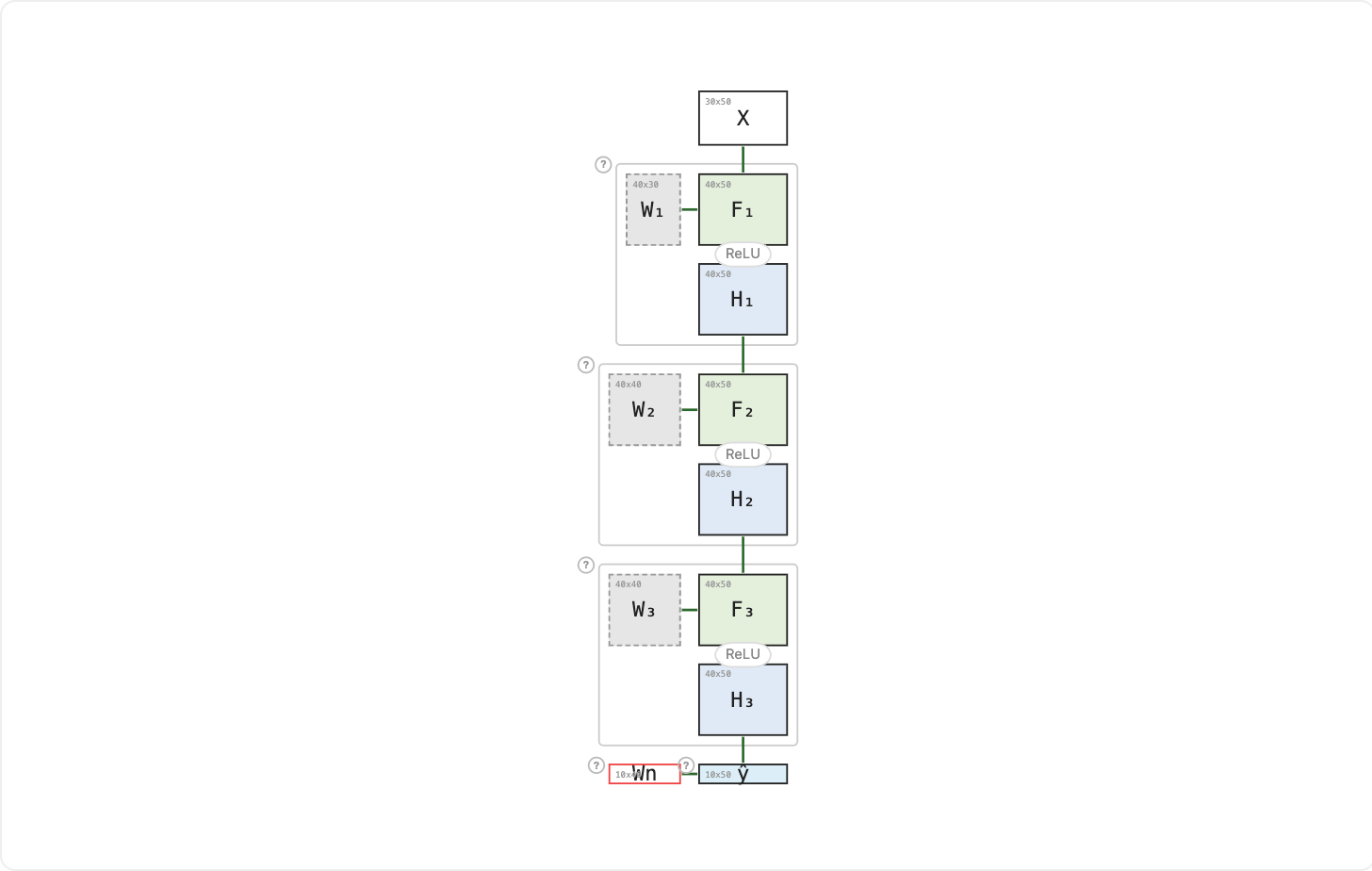
In Freezing Layers, we kept the foundational prerequisites fixed and refreshed only the advanced course on top, W₃. But even refreshing one course is still a whole course. W₃ is a full 40 × 40 matrix (1600 weights to update), weeks of lectures, assignments, and exams to work through. What if we don't re-take any existing course at all, and instead pick up a single new one-credit certificate, the kind you can finish in a month?
Paid members: the full breakdown continues below ↓