
Feature Extraction + Head
Fine-Tuning series: 6 of 8

Library › Fine-Tuning
Feature Extraction + Head
A feature head is a small trainable MLP bolted onto a frozen pretrained backbone. Think of it as pursuing a PhD on top of a master's degree. The master's, your pretrained backbone, stays exactly as it was, with no review. You aren't re-taking Linear Algebra or Probability; you're building something specialized on top of it: the PhD adds its own coursework, its own nonlinearity, and its own thesis layer.
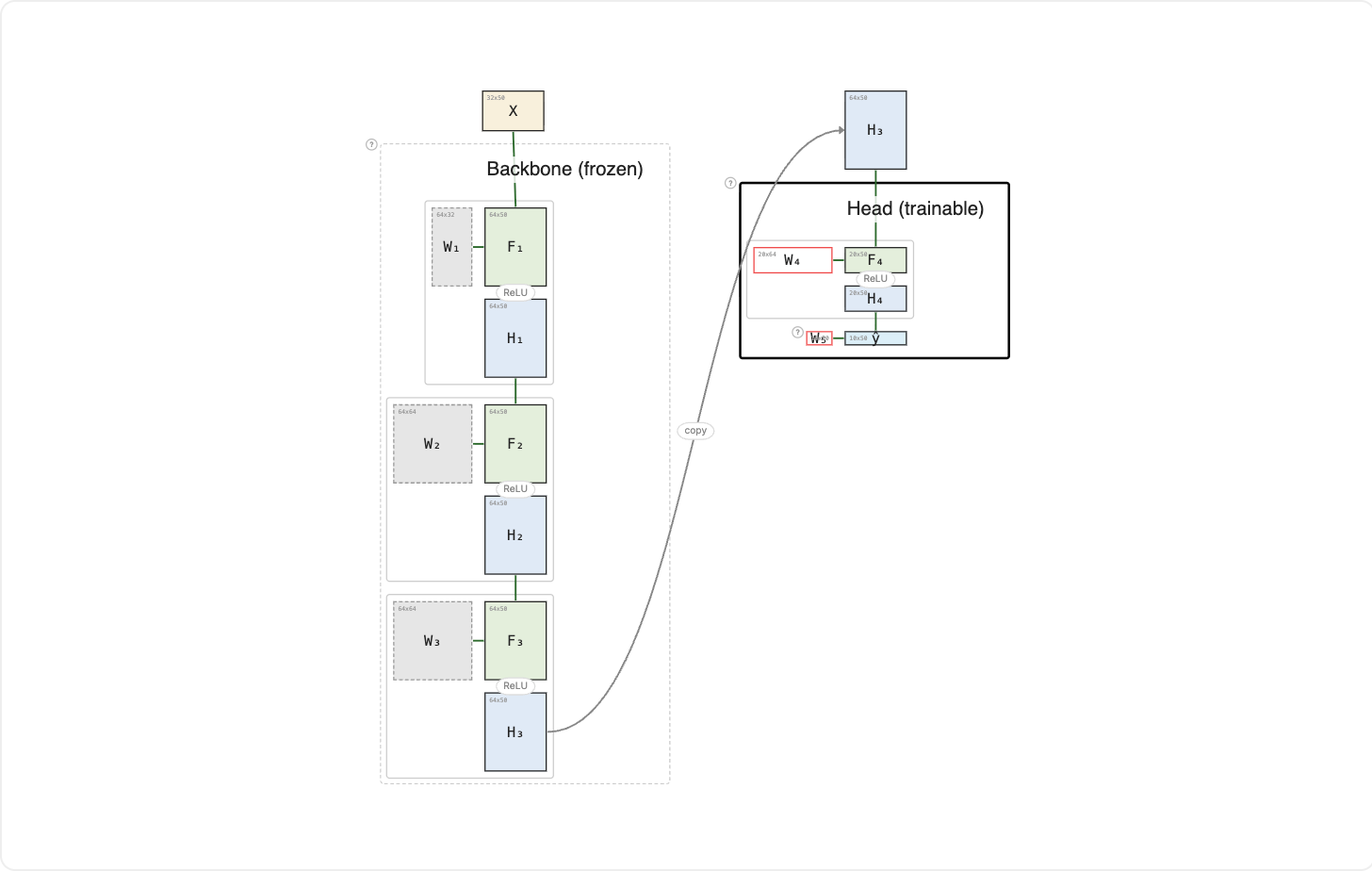
Paid members: the full breakdown continues below ↓