
Adapter Layers
Fine-Tuning series: 7 of 8

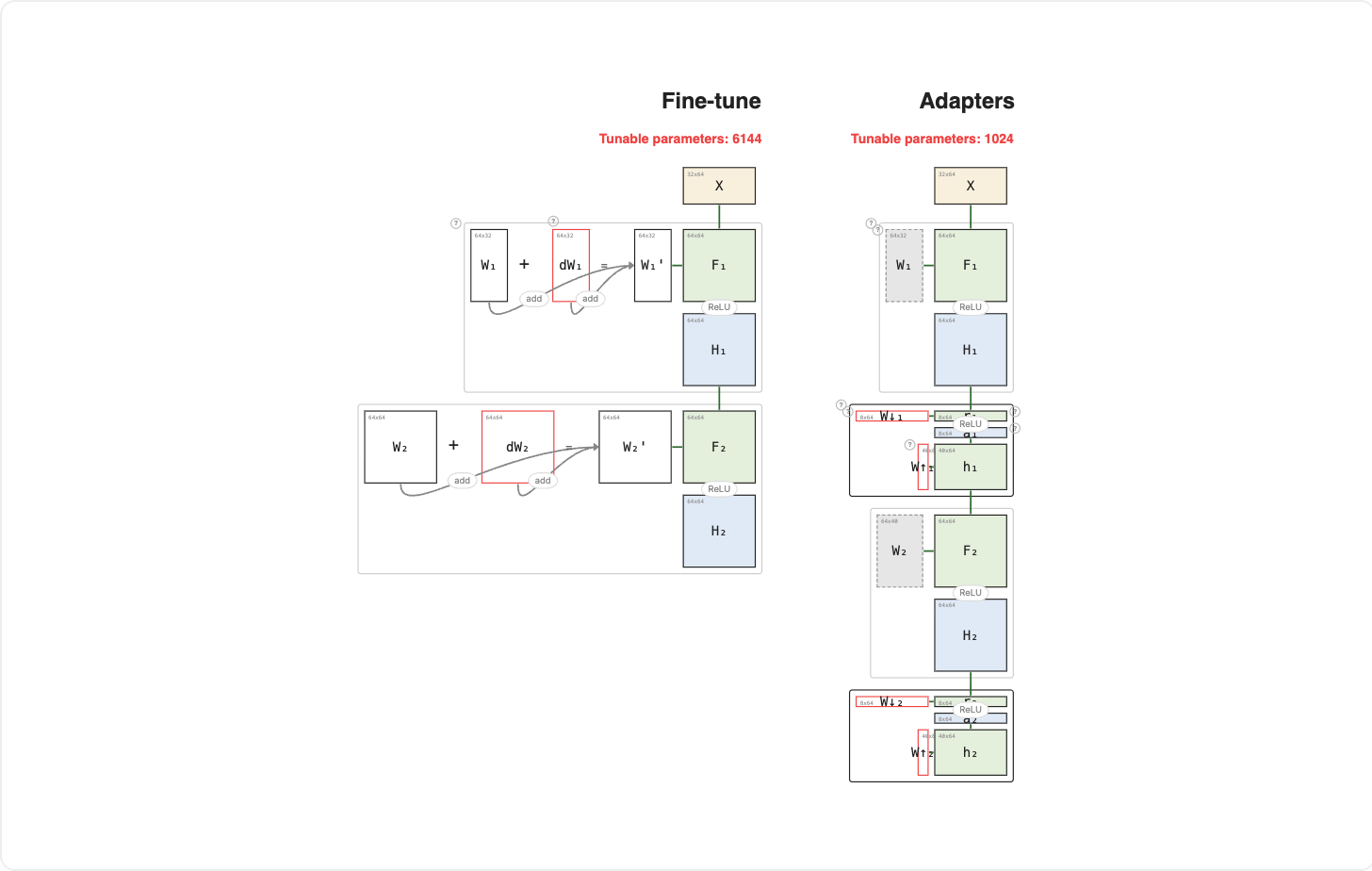
Houlsby et al., 2019 proposed a different strategy: instead of choosing which layers to freeze, insert small trainable modules (adapters) between every frozen layer.
Paid members: the full breakdown continues below ↓