
LoRA
Fine-Tuning series: 8 of 8

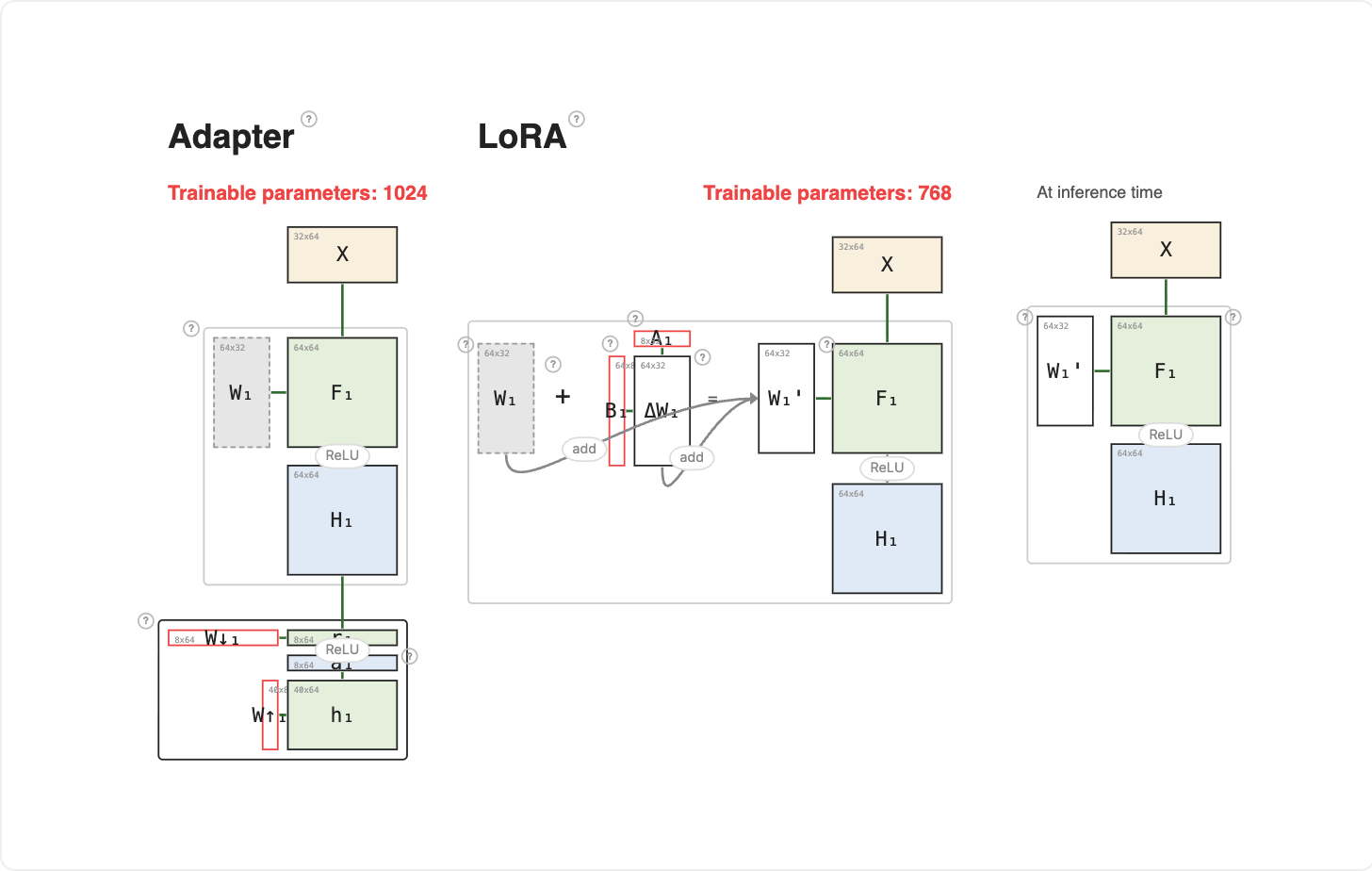
Adapters showed that a low-rank bottleneck can specialize a frozen layer with far fewer parameters than a full ΔW.
Paid members: the full breakdown continues below ↓
Adapters showed that a low-rank bottleneck can specialize a frozen layer with far fewer parameters than a full ΔW.
Paid members: the full breakdown continues below ↓