
Freezing Layers
Fine-Tuning series: 4 of 8

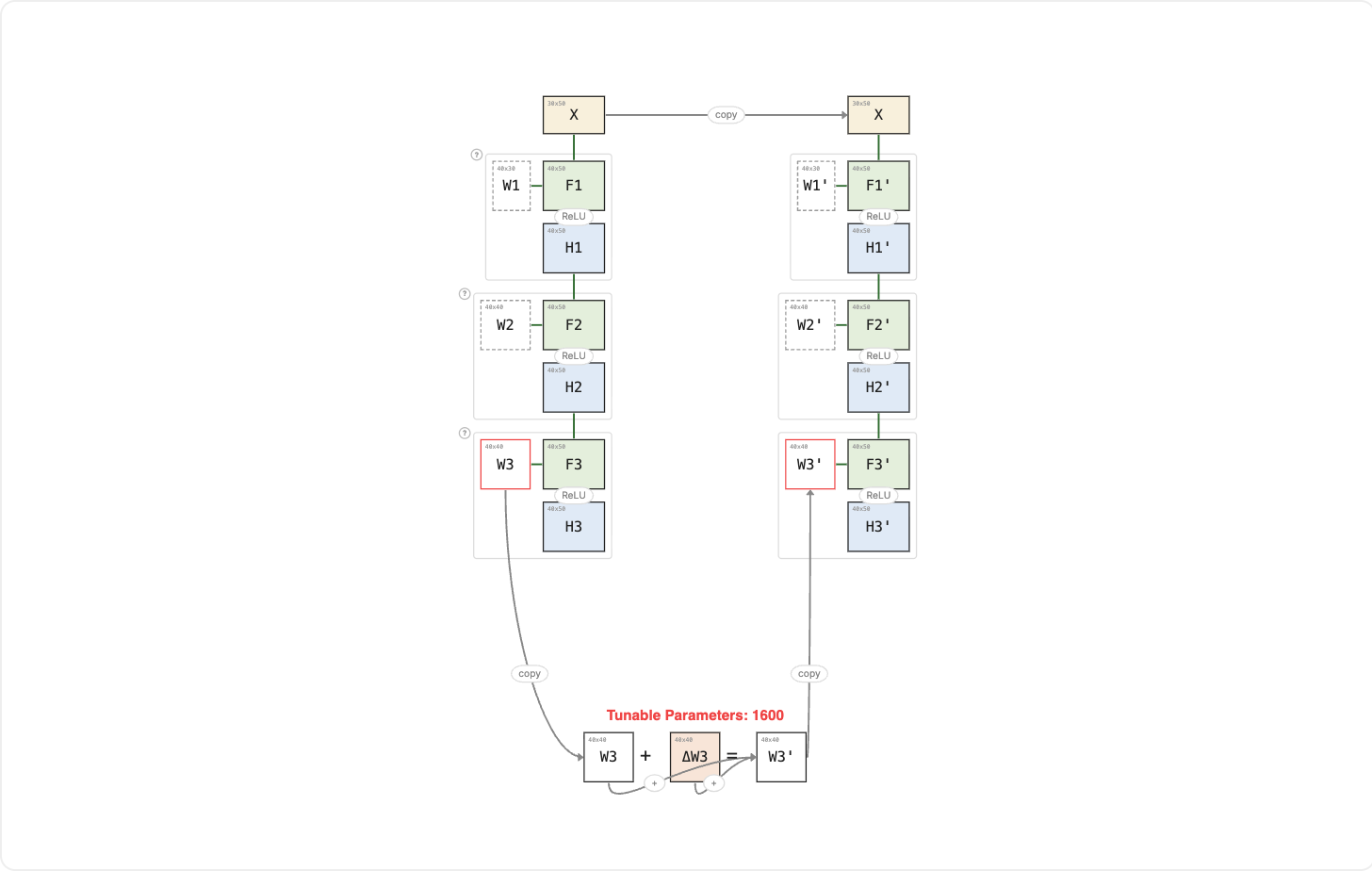
In the previous lesson, full fine-tuning reviewed every prerequisite (Linear Algebra, Probability, Advanced ML) to refresh each subject with the latest topics. Effective, but exhausting.
Paid members: the full breakdown continues below ↓