
Weight Update
Fine-Tuning series: 1 of 8

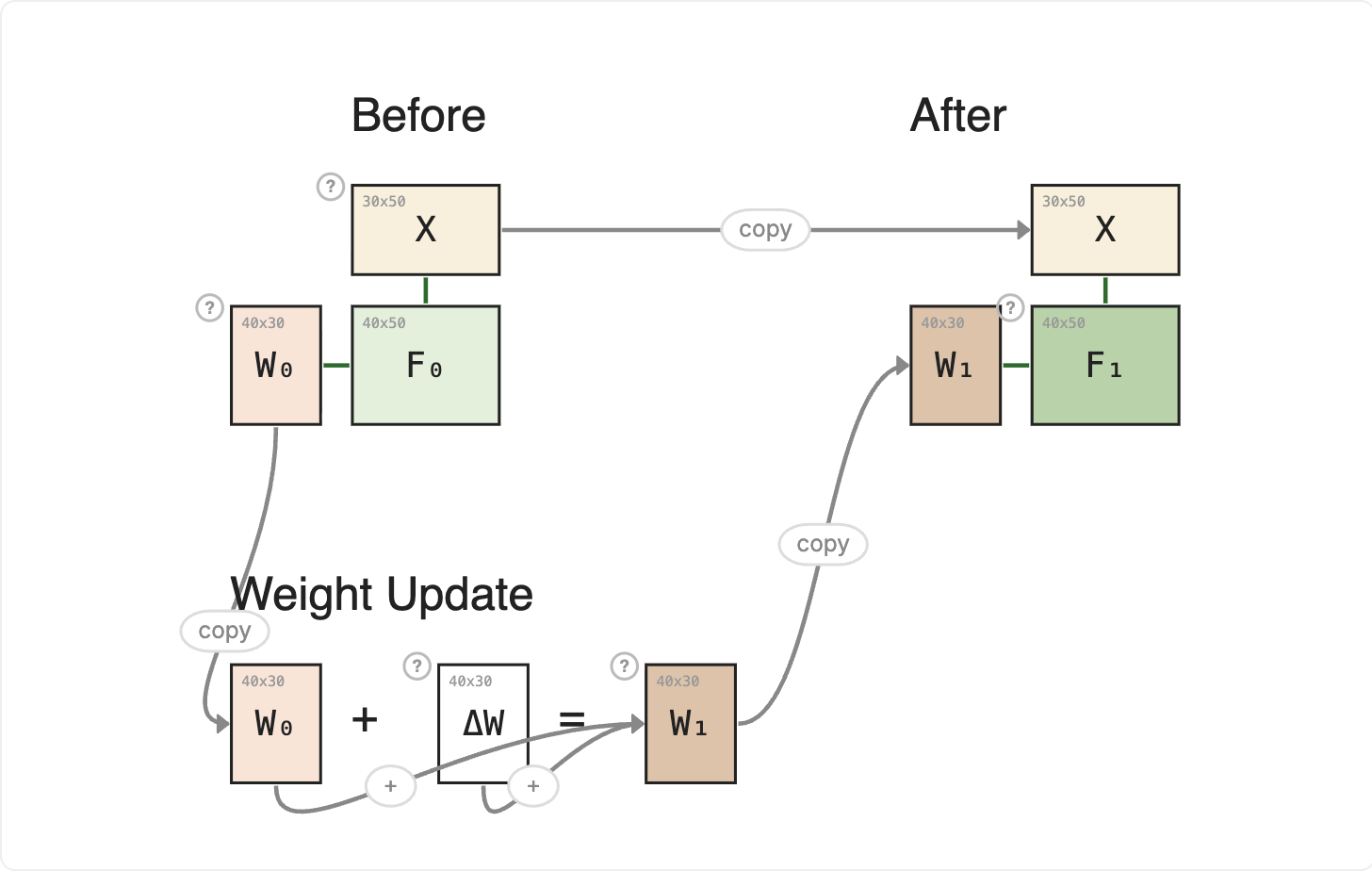
When a neural network learns, what actually changes? Not the architecture: the shape of the network stays fixed. Not the inputs: those come from outside. What moves is the weights.
Paid members: the full breakdown continues below ↓