
Full Fine-Tuning
Fine-Tuning series: 3 of 8

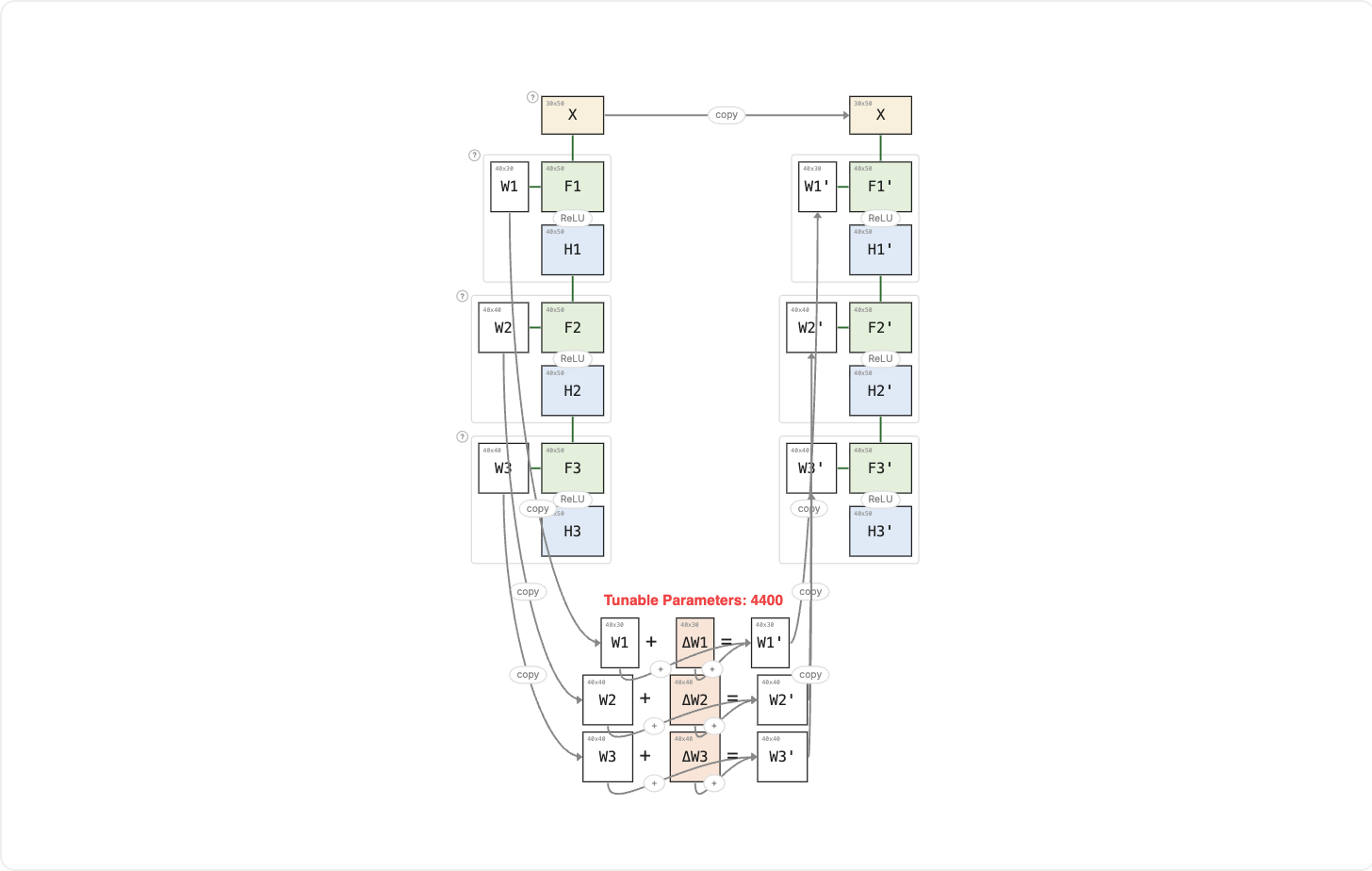
In the previous lesson, fine-tuning meant updating one weight matrix. A real network has many: three layers in this example, billions of parameters in a production model. What does fine-tuning look like when you update all of them?
Paid members: the full breakdown continues below ↓