
RMS, Group, Layer, Batch Norm, Tensor Parallelism
Frontier AI Drawings: 12 of 13

Library › Frontier AI Drawings
RMS, Group, Layer, Batch Norm, Tensor Parallelism
Last week, we explored RoPE, a 2021 innovation that quickly became the default for positional encoding. This week, we turn to another technique that rose to prominence around the same time: RMSNorm.
And because we covered tensor parallelism a few weeks back, I can now show you RMSNorm’s key advantage: in a multi-GPU setting, it needs only one all-reduce instead of two, a simple change that delivers a clear efficiency gain.
Today, RoPE and RMSNorm stand side by side as two of the most influential transformer upgrades of the past few years. They’re no longer just clever tweaks. They’re foundational components of frontier models like LLaMA, Qwen3, and DeepSeek.
Drawings
For this week’s issue, I created eight new drawings as follows:
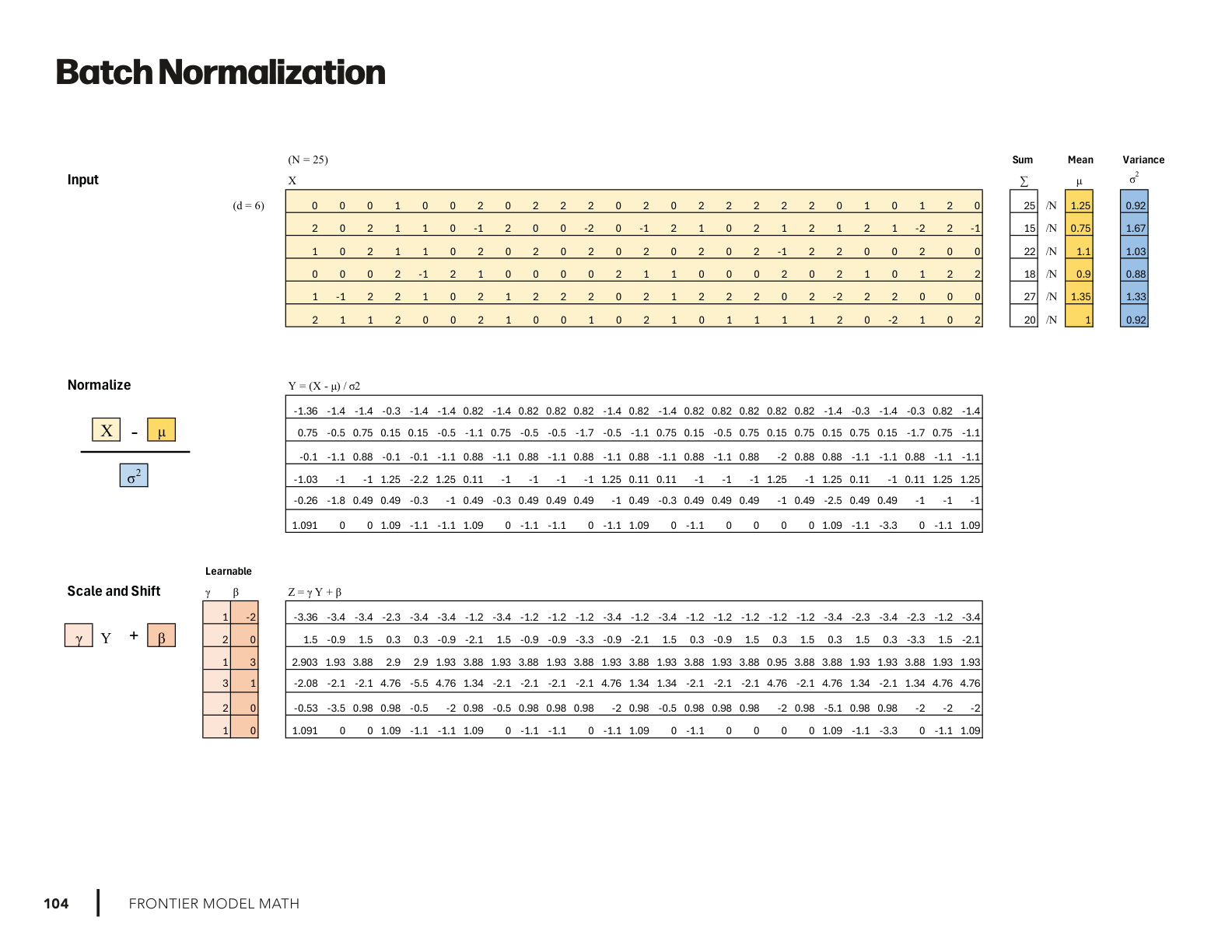
BatchNorm – The classic approach that started it all, now mostly seen in CNNs.
LayerNorm – The original choice for transformers, normalizing across features.
RMSNorm – A simplified variant that drops the mean, now standard in many frontier models.
GroupNorm – A middle ground between BatchNorm and LayerNorm, useful in specific architectures.
LayerNorm + Tensor Parallelism – Shows why LayerNorm typically requires two all-reduce operations (to compute mean and variance) when sharded across devices, a key scalability bottleneck.
RMSNorm + Tensor Parallelism – Illustrates how dropping the mean reduces synchronization to a single all-reduce, making RMSNorm significantly more efficient at scale.
Post-LayerNorm (Original Transformer) – The design used in the original 2017 architecture.
Pre-RMSNorm (Modern Transformer) – The modern variant used in LLaMA, DeepSeek, and beyond.
Next Week: We’ll bring everything together for a full, step-by-step breakdown of Qwen3, one of the most advanced open-source transformers today. All the pieces I’ve covered in the series will finally click into place.

Page 1 of 8
Become a member to access the rest of the drawings.