
Cross Attention
Attention: 4 of 11

You are going on a trip and your dog needs a sitter. Your query: who among the teens on this street can sit a dog?
There are M teens in the neighborhood. Each teen's key: can I sit a dog right now? Each teen's value: their availability and how to reach them.
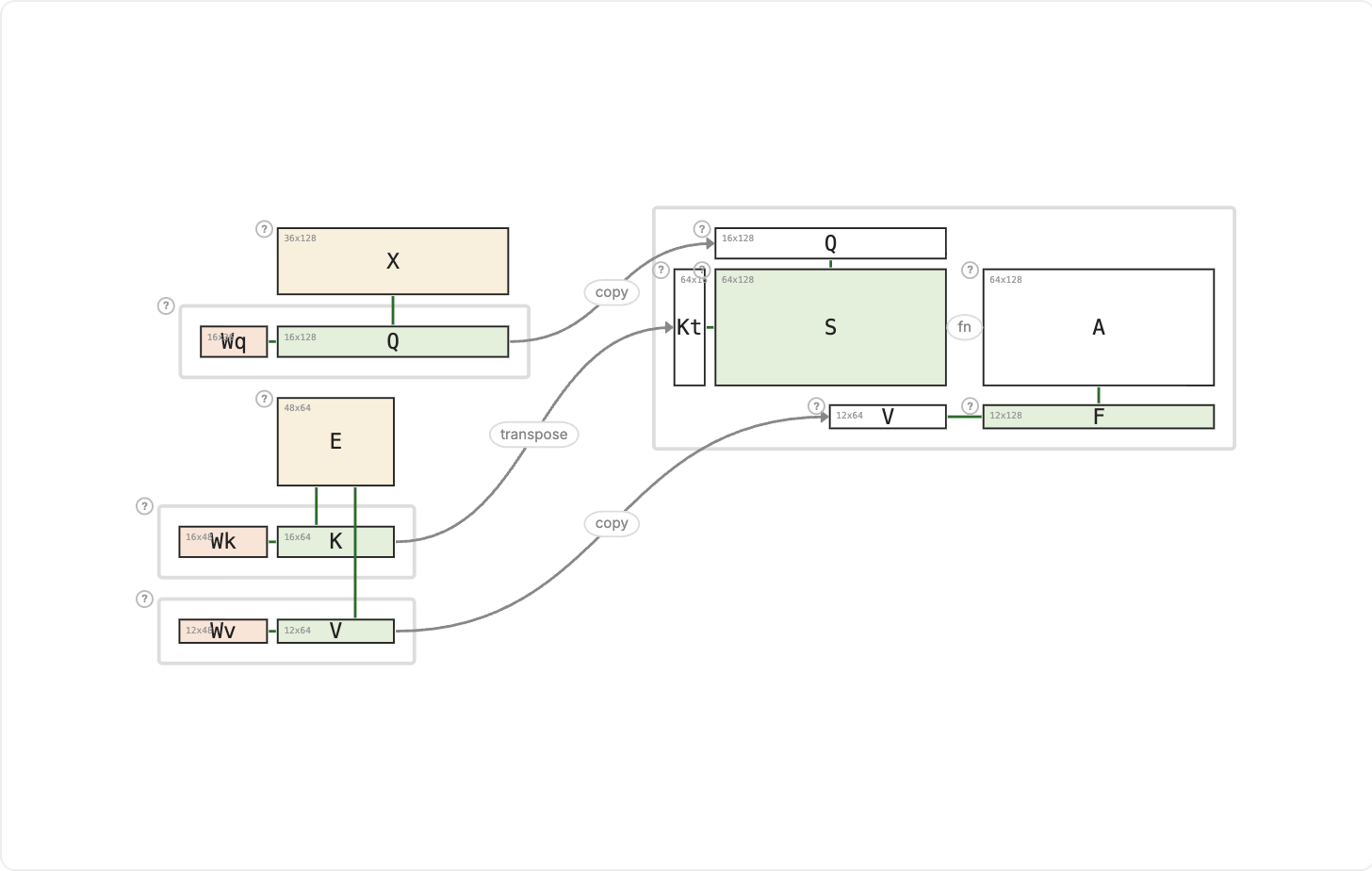
You score every teen against your query. The teen who can sit scores high; you retrieve their contact. That's cross-attention: your query comes from you (X), and the keys and values come from a completely different group (E).
Now suppose all N neighbors are going on trips. Every one of them is asking the same M teens the same question. The score matrix is N × M: N neighbors each scoring all M teens. N rows of queries, M columns of keys. Not square, because the queriers and the answerers are two different groups.
This is not an accident. The Transformer was originally designed for translation. A sentence in English might have N words; the same sentence in French might have M words. Different lengths, different vocabularies, different structures, yet the same meaning. Cross-attention lets the decoder (generating French) look at the encoder (reading English): N French tokens querying M English tokens, a N × M score matrix.
Mechanically, only one thing changes from self-attention: the K and V projections take E as input instead of X. Wq still projects X into queries; Wk and Wv project E into keys and values. Everything downstream (the score matrix S = Kᵀ × Q, the softmax, the V × A output) is identical.
The two sources don't have to share the same embedding dimension. X has model_x = 36 features, E has model_e = 48. What matters is that after projection, queries and keys both land in the same key space (key = 16). That's what makes the dot product Kᵀ × Q valid.
This is how transformers in encoder-decoder models, vision-language models, and RAG systems let one stream "look at" another.