
QKV Projection
Attention: 1 of 11

It's midnight. A dog is barking somewhere in the neighborhood and you can't fall asleep. Your query: "who has a dog?"
Each neighbor holds a key vector. One dimension of that key signals whether they own a dog. When a neighbor's key matches your query well, you retrieve their value: their address.
Notice: the address has nothing to do with dogs. The query and key are both about dogs: that's the matching signal. The value carries something completely different: the information you actually need to act on tomorrow morning.
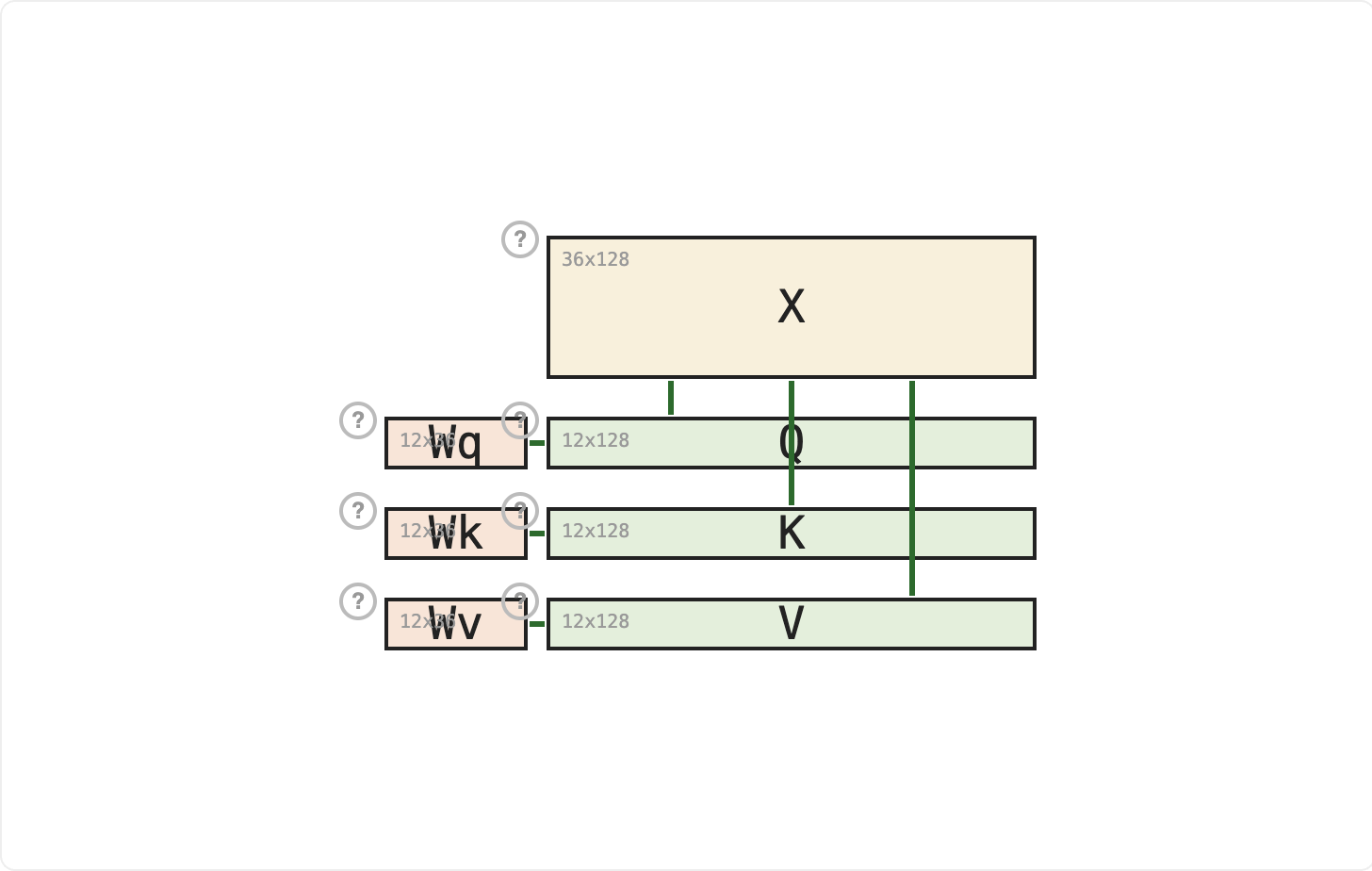
This is why three separate projections exist. Wq produces Queries (what you're looking for), Wk produces Keys (what you can be matched on), and Wv produces Values (what you send forward when selected). Each is a simple matrix multiplication: Q = Wq × X, K = Wk × X, V = Wv × X.
Q and K must share the same row count (Key Dimension) so their dot product works in the attention computation. V can have a different row count (Value Dimension), which determines the output size.
The model size is the number of rows in the input X. The key and value dimensions are usually smaller than the model size, so these projections compress the input into a smaller representation.
pytorch convention uses row vectors for input, so you will need to transpose the math. It's quite confusing, I know. 😉
I have seen other explanations which use the input X as a bunch of row vectors. And they multiply it from the other side of the matrix to generate Q, K, V. Q = X x Wq, K = X x Wk, V = X x Wv. Which way is actually used in industry code e.g. PyTorch transformers class?