
Self Attention (Shared KV)
Attention: 6 of 11

I hope the midnight dog story has helped build good intuition for what queries, keys, and values actually do. From here, the series shifts to mechanics and engineering trade-offs.
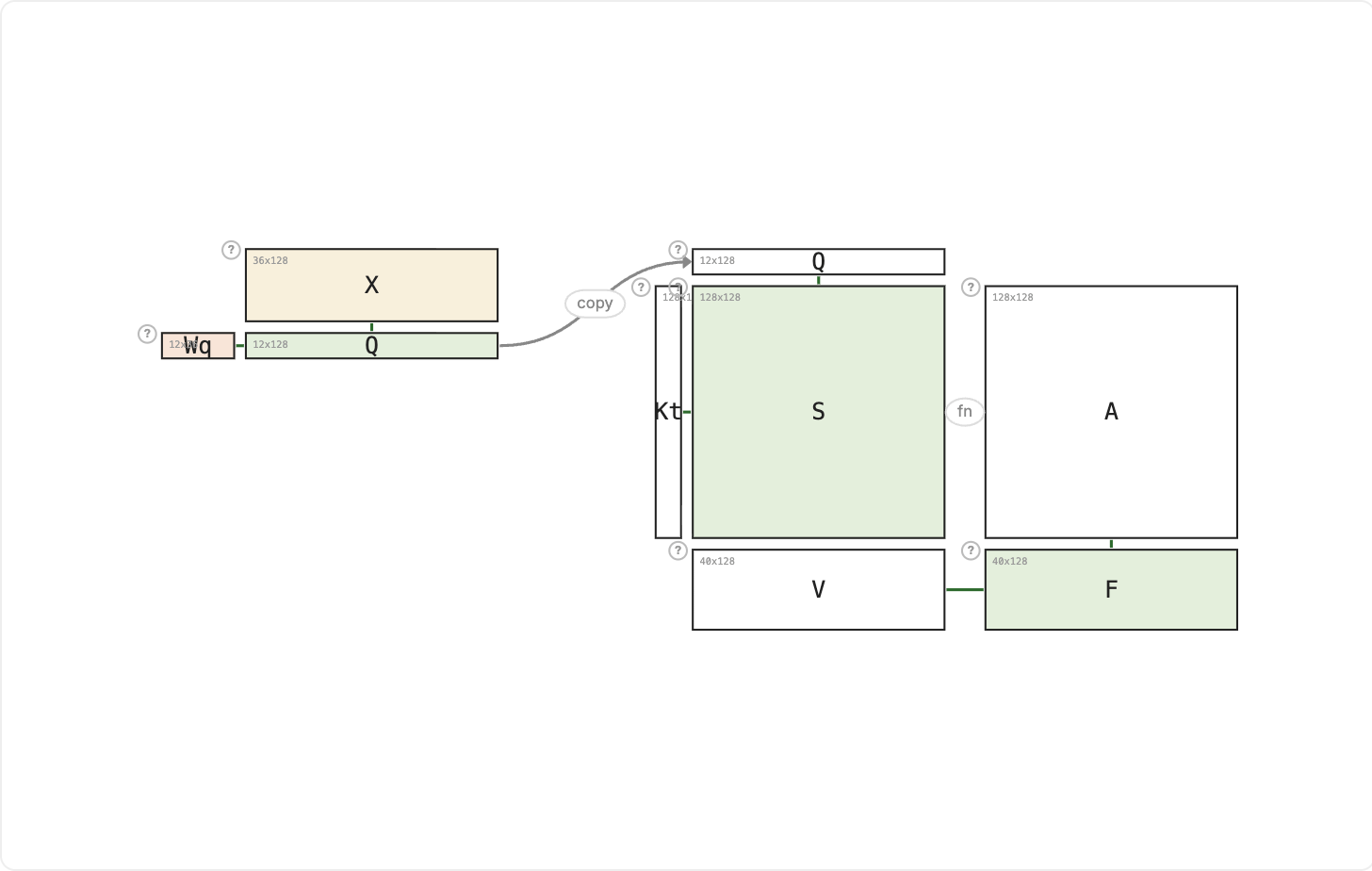
This is a single attention head that receives shared Key and Value from another head: the building block of Multi-Query Attention. Only the Query projection (Wq) is unique to this head. K and V are computed once by a primary head and passed here unchanged. There are no Wk or Wv weight matrices on this head at all.
The motivation is memory. In autoregressive decoding, K and V from every previous token must be stored in a KV cache so they can be reused at each new step. If every head stores its own K and V, that cache grows proportionally with the number of heads. Sharing K and V across heads cuts that cost without touching the queries, which remain independent. Each head can still ask its own question; it just looks up the answers in a shared directory.