
Attention Computation
Attention: 2 of 11

You have your query ("who has a dog?"), every neighbor's key, and every neighbor's address. Now you score each neighbor against your query.
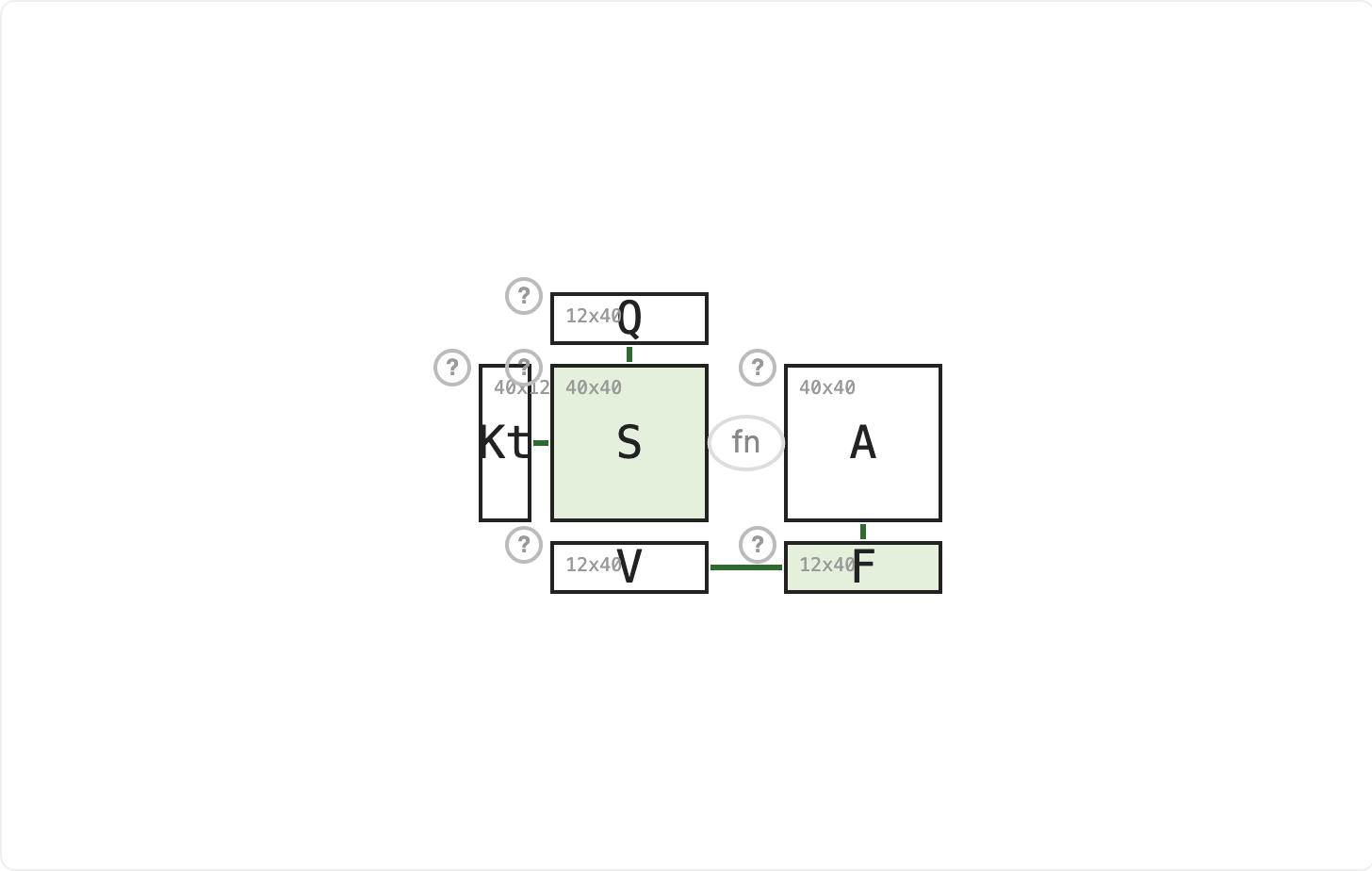
S = Kᵀ × Q computes one score per (neighbor, querier) pair. The neighbor with a dog scores high. The neighbor with a cat scores near zero. S is a seq × seq matrix: every token scoring every other token simultaneously.
The scores are divided by √d (key dimension) before softmax. Without this, dot products grow large as the key dimension increases, and softmax collapses: you'd fixate on one neighbor and ignore everyone else.
A = softmax(S/√d) converts scores into attention weights. Each column of A sums to 1: your attention is a probability distribution over all neighbors. The dog owner gets most of the weight.
F = V × A takes a weighted combination of all addresses. The dog owner's address dominates the output. In practice this blend is the whole point: the model does not pick one token but mixes information from all of them, weighted by relevance.
This step has no learned parameters. It is just matrix multiplications and a softmax. It is also what makes self-attention O(n²): S and A are both seq × seq regardless of key or value dimensions.
Next:
3. Self Attention